YOLOv3:年度改进版,速度与精度提升
需积分: 12 30 浏览量
更新于2024-09-08
收藏 2.14MB PDF 举报
YOLOv3,全称为"You Only Look Once version 3",是一种先进的目标检测算法,由Joseph Redmon和Ali Farhadi在华盛顿大学开发。它的出现是对前一代YOLO(You Only Look Once)算法的一次迭代改进,旨在提高准确性和保持实时性能。
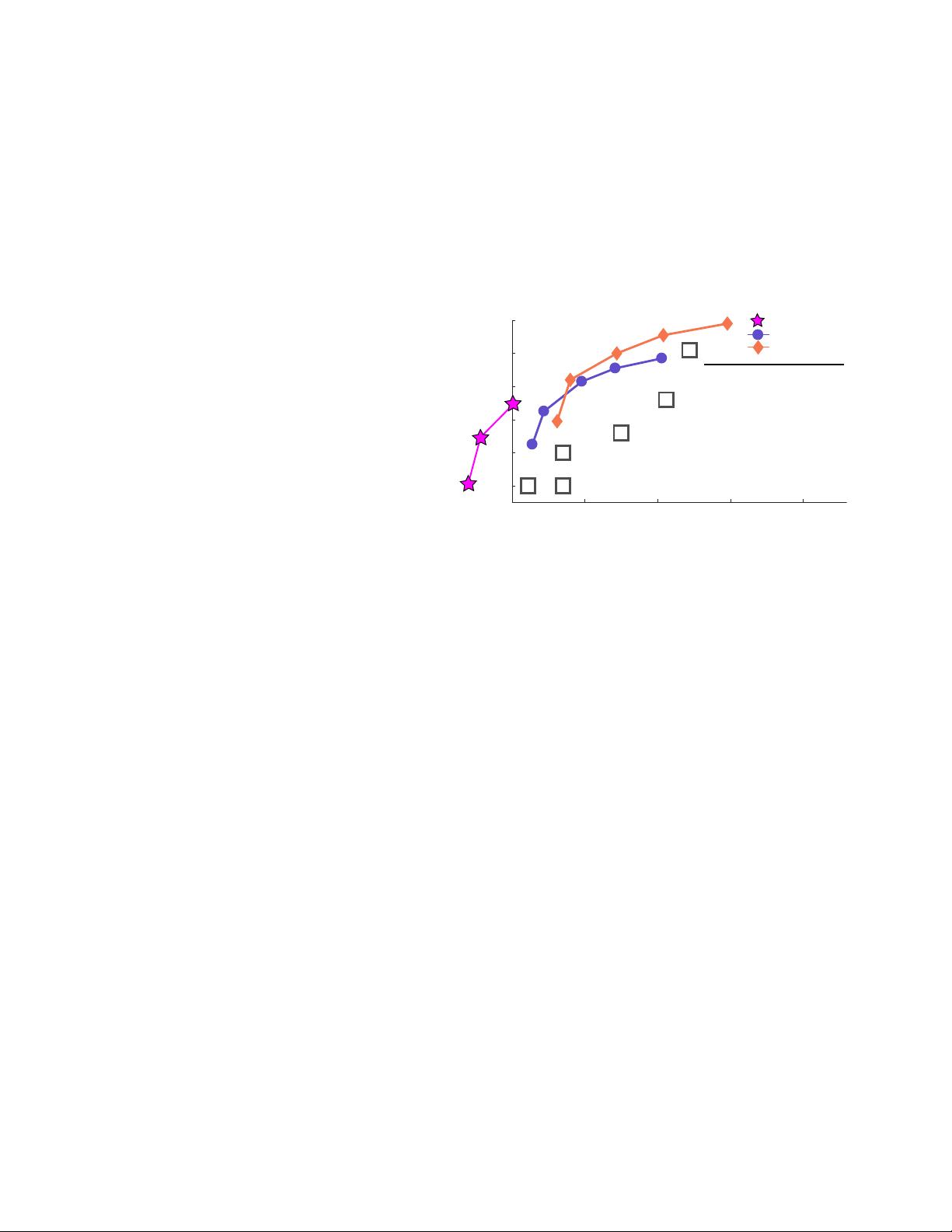
在YOLOv3的设计上,开发者们做了一系列的小改动,这些改进旨在优化模型效率和精确度。尽管YOLOv3的网络结构比前代稍微大一些,但这种增大带来了显著的好处。在320x320的分辨率下,YOLOv3的运行速度达到了惊人的22毫秒,准确率达到28.2 mAP,这使得它与SSD(Single Shot MultiBox Detector)相当,同时速度快了三倍。在旧的5IOU mAP检测指标下,YOLOv3的表现也十分出色,达到了57.9 AP50,在Titan X上仅需51毫秒,相比RetinaNet的57.5 AP50但耗时198毫秒,YOLOv3的速度优势更为明显,提升了约3.8倍。
作者没有进行大量的研究工作,而是更多地将精力投入到了对现有技术的微调和优化上。他们的目标是通过一系列小的、针对性的改进来提升YOLOv3的整体性能,而不是追求颠覆性的创新。这种务实的方法使得YOLOv3能够在保持快速响应的同时,提供与当前最先进的深度学习方法竞争的性能。
值得注意的是,所有的YOLOv3代码都开放源码,用户可以直接访问<https://pjreddie.com/yolo/> 获取和使用。这体现了开源社区对于推动AI技术进步的重要作用,同时也鼓励其他研究人员和开发者参与到算法的改进和完善中来。
总结来说,YOLOv3是一个在目标检测领域具有竞争力的算法,它在保持实时性的同时,通过精心设计的改进提高了精度。这标志着在AI技术发展过程中,不断优化既有算法并结合实际应用需求的重要性。YOLOv3的成功案例展示了如何在现有基础上进行迭代创新,推动技术的进步。
YOLOv3: An Incremental Improvement
Joseph Redmon, Ali Farhadi
University of Washington
Abstract
We present some updates to YOLO! We made a bunch
of little design changes to make it better. We also trained
this new network that’s pretty swell. It’s a little bigger than
last time but more accurate. It’s still fast though, don’t
worry. At 320 × 320 YOLOv3 runs in 22 ms at 28.2 mAP,
as accurate as SSD but three times faster. When we look
at the old .5 IOU mAP detection metric YOLOv3 is quite
good. It achieves 57.9 AP
50
in 51 ms on a Titan X, com-
pared to 57.5 AP
50
in 198 ms by RetinaNet, similar perfor-
mance but 3.8× faster. As always, all the code is online at
https://pjreddie.com/yolo/.
1. Introduction
Sometimes you just kinda phone it in for a year, you
know? I didn’t do a whole lot of research this year. Spent
a lot of time on Twitter. Played around with GANs a little.
I had a little momentum left over from last year [12] [1]; I
managed to make some improvements to YOLO. But, hon-
estly, nothing like super interesting, just a bunch of small
changes that make it better. I also helped out with other
people’s research a little.
Actually, that’s what brings us here today. We have
a camera-ready deadline [4] and we need to cite some of
the random updates I made to YOLO but we don’t have a
source. So get ready for a TECH REPORT!
The great thing about tech reports is that they don’t need
intros, y’all know why we’re here. So the end of this intro-
duction will signpost for the rest of the paper. First we’ll tell
you what the deal is with YOLOv3. Then we’ll tell you how
we do. We’ll also tell you about some things we tried that
didn’t work. Finally we’ll contemplate what this all means.
2. The Deal
So here’s the deal with YOLOv3: We mostly took good
ideas from other people. We also trained a new classifier
network that’s better than the other ones. We’ll just take
you through the whole system from scratch so you can un-
derstand it all.
50 100 150 200 250
inference time (ms)
28
30
32
34
36
38
COCO AP
B C
D
E
F
G
RetinaNet-50
RetinaNet-101
YOLOv3
Method
[B] SSD321
[C] DSSD321
[D] R-FCN
[E] SSD513
[F] DSSD513
[G] FPN FRCN
RetinaNet-50-500
RetinaNet-101-500
RetinaNet-101-800
YOLOv3-320
YOLOv3-416
YOLOv3-608
mAP
28.0
28.0
29.9
31.2
33.2
36.2
32.5
34.4
37.8
28.2
31.0
33.0
time
61
85
85
125
156
172
73
90
198
22
29
51
Figure 1. We adapt this figure from the Focal Loss paper [9].
YOLOv3 runs significantly faster than other detection methods
with comparable performance. Times from either an M40 or Titan
X, they are basically the same GPU.
2.1. Bounding Box Prediction
Following YOLO9000 our system predicts bounding
boxes using dimension clusters as anchor boxes [15]. The
network predicts 4 coordinates for each bounding box, t
x
,
t
y
, t
w
, t
h
. If the cell is offset from the top left corner of the
image by (c
x
, c
y
) and the bounding box prior has width and
height p
w
, p
h
, then the predictions correspond to:
b
x
= σ(t
x
) + c
x
b
y
= σ(t
y
) + c
y
b
w
= p
w
e
t
w
b
h
= p
h
e
t
h
During training we use sum of squared error loss. If the
ground truth for some coordinate prediction is
ˆ
t
*
our gra-
dient is the ground truth value (computed from the ground
truth box) minus our prediction:
ˆ
t
*
− t
*
. This ground truth
value can be easily computed by inverting the equations
above.
YOLOv3 predicts an objectness score for each bounding
box using logistic regression. This should be 1 if the bound-
ing box prior overlaps a ground truth object by more than
any other bounding box prior. If the bounding box prior
1
下载后可阅读完整内容,剩余5页未读,立即下载
2023-10-24 上传
2023-06-07 上传
2023-05-04 上传
2024-05-23 上传
2024-06-28 上传
2021-01-20 上传
2024-10-08 上传
2023-07-01 上传

Darkmoon_L
- 粉丝: 7
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
