Hadoop大数据与云计算教程:HDFS核心讲解
版权申诉
34 浏览量
更新于2024-07-07
收藏 1.11MB PPTX 举报
"该资源是一个全面的大数据与云计算教程系列,涵盖了从Hadoop基础到高级应用的多个主题,包括HDFS、MapReduce、Hive、HBase、Pig、Zookeeper、Sqoop、Kafka、Storm、Spark、Oozie、Impala、Solr、Lily、Titan、Neo4j和Elasticsearch等关键技术和工具。"
在这个大数据与云计算的课程中,首先介绍了Hadoop的核心组件——HDFS(Hadoop Distributed File System),它是分布式存储的基础。HDFS设计的主要目标是处理大规模数据,通过将大型数据集分割成块并在多台服务器上分布存储,以实现高可用性和容错性。HDFS的一个关键特性是它的通透性,使得用户可以像访问本地文件一样访问分布式文件,同时它还具备强大的容错机制,即使部分节点故障,整个系统仍能保持稳定运行。
课程中详细讲解了HDFS的工作原理,包括NameNode和DataNode的角色,以及Secondary NameNode如何协助主NameNode管理元数据。此外,课程还涉及到了HDFS的网络拓扑和基本部署架构,展示了如何构建一个高可用的HDFS集群。
MapReduce是Hadoop的并行计算模型,用于处理和生成大规模数据集。课程详细阐述了MapReduce的工作流程,包括Map阶段、Shuffle与Sort阶段和Reduce阶段,以及如何使用Eclipse开发插件进行MapReduce程序的编写和调试。
除了Hadoop基础,课程还深入到Hive、HBase、Pig等数据处理工具。Hive提供了一种基于SQL的查询语言(HQL),用于处理和分析存储在HDFS中的结构化数据。HBase是一个NoSQL数据库,适合实时读写大数据。Pig是数据分析的平台,其Pig Latin语言简化了大数据处理任务。
课程还涵盖了数据导入导出工具Sqoop,消息队列Kafka,实时流处理系统Storm,以及作业调度器Oozie。Spark作为一个快速、通用且可扩展的数据处理引擎,其Scala和Java API的使用也在课程中得到详细介绍。最后,课程讨论了多种数据索引和搜索技术,如Solr、Lily、Titan和Neo4j,以及搜索引擎Elasticsearch。
这个课程内容丰富,旨在帮助学习者掌握大数据处理和云计算的关键技术和实践,适合初学者和有一定经验的开发者进一步提升技能。通过这些课程,学员可以深入了解大数据生态系统,并具备实际操作和解决复杂问题的能力。
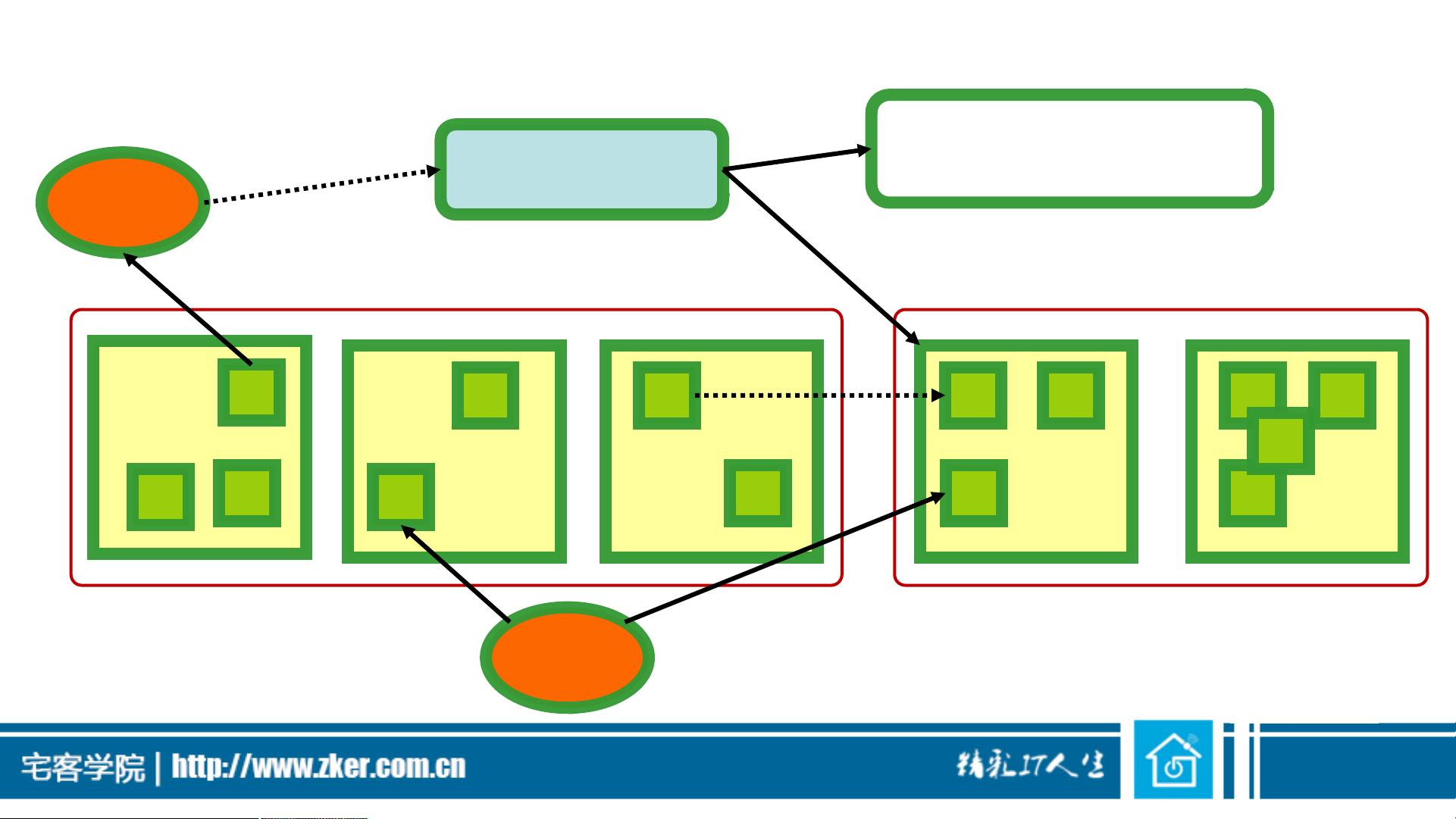
HDFS体系结构
Client
Namenode
Metadata(Name,replicas,…)
/usr/hadoop/data,3,….
Metadata操作
机柜2
机柜1
Block 操作
datanodes datanodes
容错
Client
Read
Write
Write
HDFS体系结构

剩余37页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传

passionSnail
- 粉丝: 460
- 资源: 7531
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
