2006年ICDM评选的十大数据挖掘算法概览
需积分: 50 31 浏览量
更新于2024-07-24
收藏 783KB PDF 举报
本文将深入探讨数据挖掘领域内由2006年国际数据挖掘会议(IEEE International Conference on Data Mining, ICDM)评选出的十大经典算法。这十种算法在数据挖掘研究社区中具有显著影响力,包括C4.5决策树、k-means聚类、支持向量机(SVM)、Apriori关联规则、Expectation-Maximization (EM)、PageRank、AdaBoost集成学习、k近邻(kNN)、朴素贝叶斯(Naive Bayes)以及CART分类与回归树。每个算法都将被详细介绍,其工作原理、在实际应用中的作用,以及当前和未来的研究趋势。
1. **C4.5决策树**:由Ross Quinlan开发,是一种基于信息增益的决策树算法,用于分类和特征选择,通过不断划分数据集来形成树状结构,易于理解和解释。
2. **k-means聚类**:这是一种无监督学习方法,通过将数据集划分为k个紧密且内部差异小的簇,有助于发现数据内在结构和模式。
3. **支持向量机(SVM)**:基于最大间隔分类,通过构建超平面来区分不同类别,适用于线性和非线性分类问题,且对高维数据处理能力强。
4. **Apriori关联规则**:用于市场篮子分析,发现频繁项集之间的关联性,如“购买牛奶的人通常也会购买面包”,常用于推荐系统和营销策略。
5. **EM算法**:一种迭代的统计学方法,用于参数估计和混合模型,尤其在序列数据和隐马尔可夫模型中有广泛应用。
6. **PageRank**:Google搜索引擎的核心算法之一,用于评估网页的重要性,通过链接分析确定网页排名。
7. **AdaBoost**:一种集成学习方法,通过结合多个弱分类器形成一个强分类器,特别在处理不平衡数据时效果显著。
8. **k近邻(kNN)**:基于实例的学习,通过计算新样本与训练样本的距离,预测其所属类别,简单易实现但计算成本可能较高。
9. **朴素贝叶斯(Naive Bayes)**:基于贝叶斯定理的分类算法,假设特征之间相互独立,虽简单但常用于文本分类和垃圾邮件过滤。
10. **CART决策树**:分类与回归树的简称,既能进行分类也能进行回归分析,通过递归地二分数据以寻找最优分割。
这些算法不仅在学术研究中占据核心地位,而且在实际商业应用中发挥着关键作用。理解并掌握这些算法的优缺点,有助于数据科学家们在处理各种数据挖掘任务时做出最佳选择。随着大数据和AI的发展,对这些算法的优化、扩展和创新将继续推动数据挖掘领域的前沿研究。
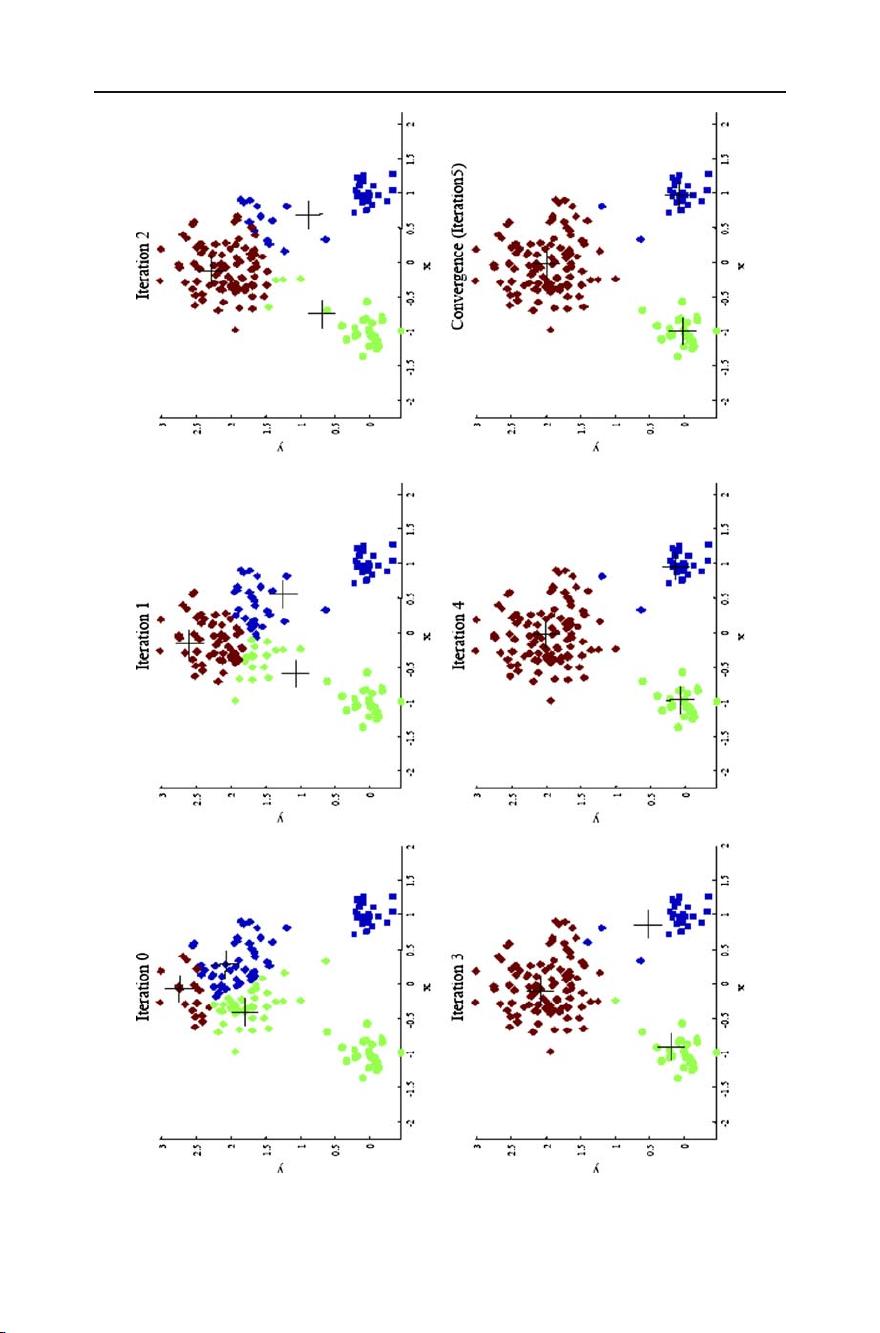
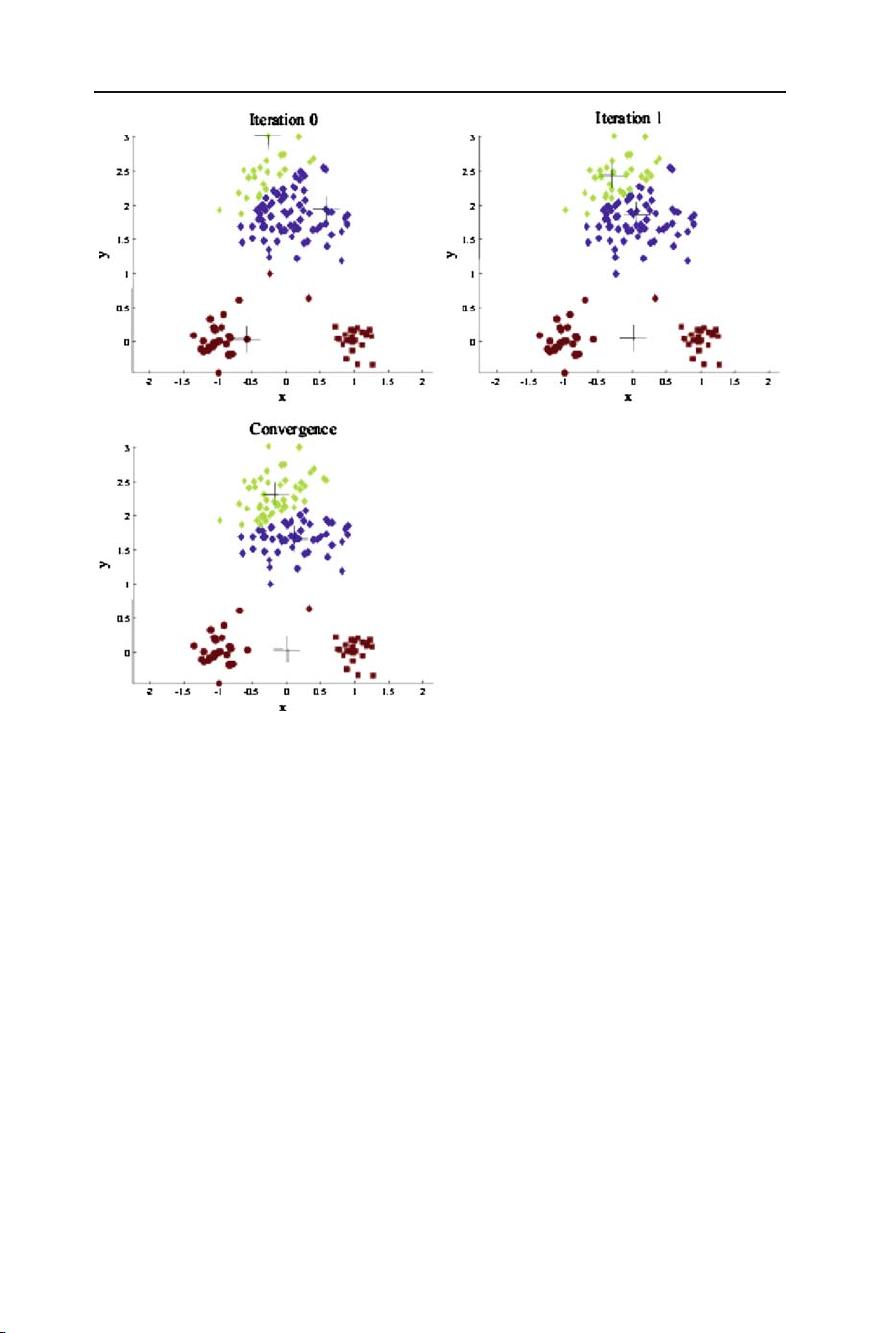
Top 10 algorithms in data mining 7
Fig. 1 Changes in cluster representative locations (indicated by ‘+’ signs) and data assignments (indicated
by color) during an execution of the k-means algorithm
123
剩余36页未读,继续阅读
2018-11-07 上传
2011-09-15 上传
2011-07-23 上传
2018-12-14 上传
308 浏览量
2023-07-03 上传
2022-07-14 上传

wison_wtj
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
