融合语音特征的远程多模态人脸识别增强技术
186 浏览量
更新于2024-08-30
收藏 1.08MB PDF 举报
"这篇研究论文探讨了一种生物特征水印算法,通过将语音特性嵌入到面部图像中来增强远程多模态人员验证。该算法同时嵌入了一个脆弱水印用于篡改检测和一个鲁棒水印来表示从语音中提取的GMM(高斯混合模型)参数。实验表明,提出的方案能够检测篡改,并对各种水印攻击具有抗性。在XM2VTS数据库上的人员验证实验验证了结合面部和语音分类器的有效性。关键词包括人脸识别、语音识别、数字水印和量化索引调制。"
在当前的科技环境下,生物识别技术已经成为身份验证的重要手段,特别是在远程识别领域,如安全访问控制、支付验证等。这篇论文【标题】"Augmenting remote multimodal person verification by embedding voice characteristics into face images" 提出了一种创新方法,旨在提高远程多模态身份验证的准确性和安全性。研究人员将语音特征与面部图像相结合,利用生物特征水印算法实现这一目标。
具体来说,论文中介绍的算法包含两个主要部分:脆弱水印和鲁棒水印。脆弱水印设计用于检测图像是否被篡改,确保数据的完整性;而鲁棒水印则用于存储从语音信号中提取的GMM参数,这些参数反映了个人独特的语音特征。GMM(高斯混合模型)是语音识别中的常用工具,能够捕捉语音信号的统计特性。
通过将这些水印嵌入到面部图像中,系统不仅能够利用面部特征进行识别,还能利用嵌入的语音信息增强识别过程。实验结果表明,这种结合了面部和语音信息的身份验证方法在XM2VTS数据库上表现出了良好的性能,证实了这种融合策略的有效性。
XM2VTS数据库是一个广泛用于人脸识别和语音识别研究的多模态数据库,包含了不同光照、表情和角度下的面部视频以及相应的同步语音记录。在该数据库上进行的实验为实际应用提供了有力的证据,证明了这种水印技术可以提升远程身份验证系统的鲁棒性和安全性。
此外,论文还关注了数字水印的抗攻击性,即水印在面对图像处理或篡改时的稳定性。量化索引调制(Quantization Index Modulation, QIM)是一种常见的数字水印技术,它在不影响图像视觉质量的同时,隐藏信息于图像的量化层。在这里,QIM可能被用作嵌入水印的方式,确保了水印的存在不会显著降低面部图像的质量。
这篇论文提出了一种新的多模态生物识别方法,通过将语音特性嵌入面部图像,提高了远程身份验证的效率和安全性。这种方法不仅能够检测潜在的图像篡改,还增强了识别系统的鲁棒性,对于未来的生物识别系统设计具有重要的参考价值。
AUGMENTING REMOTE MULTIMODAL PERSON VERIFICATION BY EMBEDDING
VOICE CHARACTERISTICS INTO FACE IMAGES
Su Wang
a
, Roland Hu
a
, Huimin Yu
a
, Xia Zheng
b
, R. I. Damper
c
a
Department of Information Science & Electronic Engineering, Zhejiang University, 310027, China
b
Department of Culture Heritage & Museology, Zhejiang University, 310027, China
c
Department of Electronics & Computer Science, University of Southampton, SO17 1BJ, UK
ABSTRACT
This paper presents a biometric watermarking algorithm to
augment remote multimodal recognition by embedding voice
characteristics into face images. We embed both a fragile wa-
termark for tampering detection, as well as a robust water-
mark to represent the GMM parameters extracted from voice.
We show that the proposed scheme can detect tampering, and
is also robust to various watermarking attacks. Person ver-
ification experiments on the XM2VTS database indicate the
validity of combining face and voice classifiers.
Index Terms— Face recognition, speaker recognition,
Digital watermarking, Quantization index modulation
1. INTRODUCTION
With the rapid progress of computer technology, biometric
recognition systems have become increasingly popular com-
pared to traditional approaches such as identification cards,
passwords, etc. However, biological information itself is not
secure. Ratha and Connell [1] summarized eight types of se-
curity attacks on a biometric system. These attacks would
alter original data in every stage of recognition. Hence, resist-
ing these attacks and protecting the security of data become
an important task.
Watermarking provides another means to increase the se-
curity of biometric data. Research work in this area can be
divided into three approaches [2]. The first is to embed bio-
metric template/sample data into host data (referred as ‘tem-
plate watermarking’ in [3]). Applications associated with this
category include convert transmission of biometric data in in-
secure channels. The second approach is to embed some data
into biometric template/sample data (referred as ‘sample wa-
termarking’ in [3]). Applications in this category can be fur-
ther distinguished by embedding robust watermarks into bio-
metric data to protect ownership; or embedding fragile wa-
termarks to detect tampering of the biometric data. Finally,
the above two approaches can be combined to form a multi-
biometric recognition system, by embedding biometric tem-
plate/sample data into another biometric data. This approach
Watermark
Embedding
Extracting
Voice Features
Encoding &
Generate
Watermarks
Host Voice
Face Image
Watermarked Image
Face
Recognition
Watermark
Extraction
Voice
Recognition
Final
Evaluation
Decoding &
Rebuild
Watermarks
Rebuild Voice
Features
Recognition
Result
Database Image
Database Voice
Noise or Resize Attacks
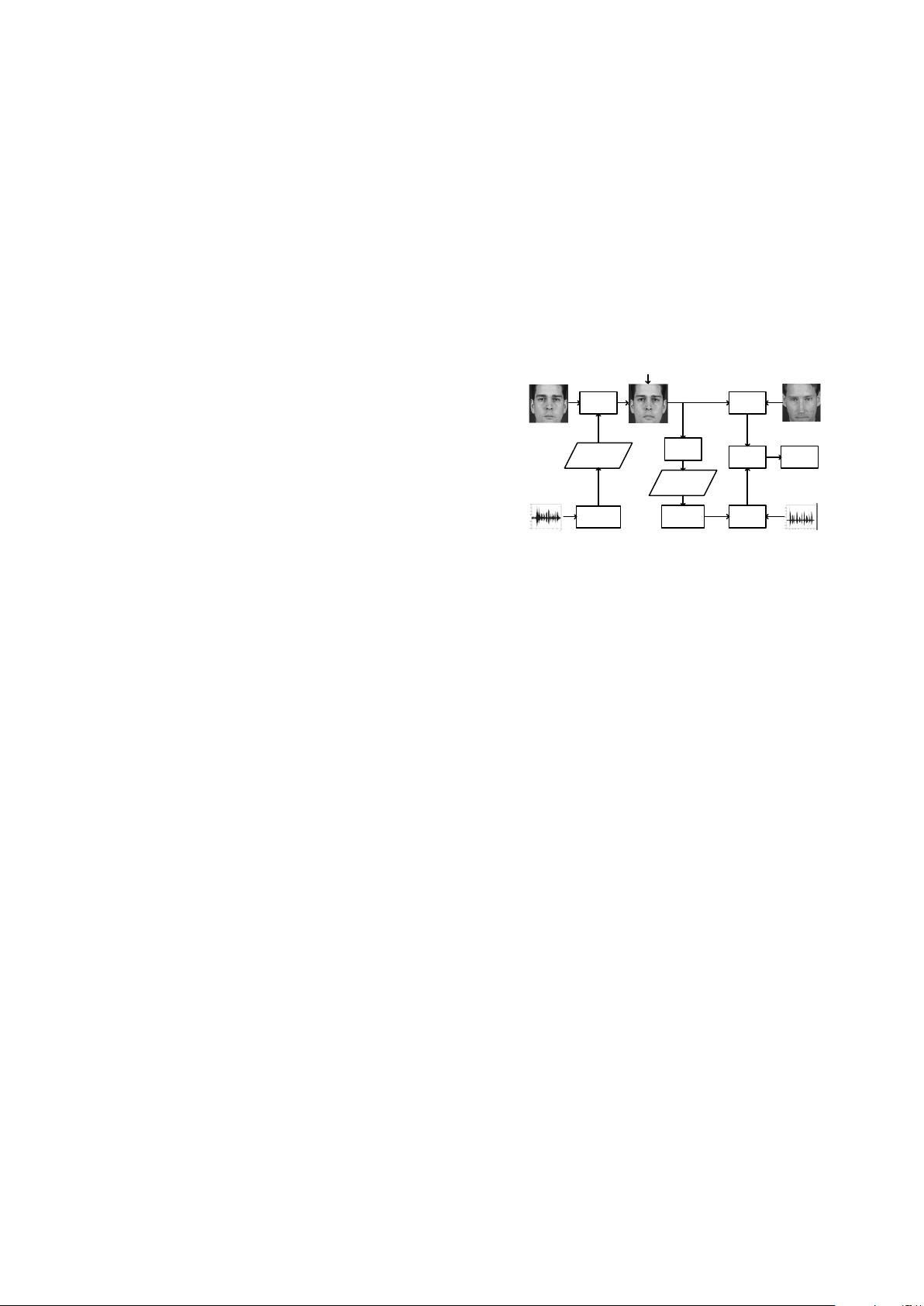
Fig. 1. The flowchart of the watermark embedding and ex-
traction scheme.
can take advantages of both template watermarking and sam-
ple watermarking. In addition, recognition performance can
also be improved by multiple biometrics compared with only
one biometric [4, 5].
In this paper, we propose a watermarking method to build
a multimodal system by embedding voice features into face
images. We confine our application into the area of remote
multimodal person verification. We propose a framework for
transferring multi-biometrics over fixed or remote networks
in which a face image is used as a container to embed voice
features before they are sent to the server for verification.
The flowchart of the system is given in Fig. 1. At the sen-
sor side, voices and face images are obtained by the audio
and visual sensors individually. Then voice characteristics are
extracted by Mel-Frequency Cepstrum Coefficients (MFCC)
and trained by the Gaussian Mixture Models [6]. The GMM
parameters are embedded into the face images using a Quan-
tization Index Modulation (QIM)-based watermarking algo-
rithm [7]. Face images embedded with voice features are
transmitted to the server for verification. In order to prevent
malicious tampering of facial features during transmission,
a fragile watermark is also embedded into salient facial re-
gions (e.g., eyes, noise and mouth). The server firstly checks
whether the fragile watermark is retained. If not, it stops au-
thentication and inform the user that his/her biometric data
has been tampered during transmission. If the fragile water-
mark is retained, then voice features are extracted from the
下载后可阅读完整内容,剩余5页未读,立即下载
2022-09-20 上传
2021-12-04 上传
2021-03-13 上传
2023-08-26 上传
2023-01-28 上传
2021-08-21 上传
2022-07-04 上传
2021-05-30 上传
2021-02-14 上传

weixin_38610815
- 粉丝: 4
- 资源: 870
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
