InfoSphere集成Teradata:提取与查找数据示例
144 浏览量
更新于2024-08-27
收藏 872KB PDF 举报
本篇文章主要介绍了如何使用IBM InfoSphere Information Server (IIS) 集成Teradata数据,通过创建示例ETL( Extract, Transform, Load)作业实现数据迁移。首先,我们关注的是从Teradata Orders表中提取数据的过程。步骤如下:
1. **使用TeradataConnector提取数据**:
- 示例作业名为ExtractOrders,采用立即访问模式,利用Teradata连接器从Orders表中读取数据。
- 连接器使用了图12中展示的相同表定义,以及图13中的连接细节,确保数据一致性。
- 数据提取时,使用TeradataDBC/SQL分区运行SQL,支持小量数据的立即访问,但不适合大规模并行提取。
2. **设置数据提取操作参数**:
- 指定运行作业的指导者节点需为序列模式,且支持批量访问方法和TeradataParallelTransporter导出驱动,以处理大容量数据。
- 提供SQL选择语句,通常结合EndofWave特性,但本文例未涉及。
- 数组大小用于连接器缓存输入记录,对提取操作影响不大,连接器会设置最大包大小为64k或1MB(取决于Teradata服务器支持)。
3. **查找Teradata数据的方法**:
- 文章讨论了两种查找方法:普通查找和稀疏查找。
- **普通查找**:所有数据一次性从目标数据库检索并存储,针对每个输入记录,通过缓存进行交叉检查获取结果。
- **示例作业**:如图19所示,使用查找工作台和Teradata连接器执行普通查找,适合相对频繁且需要完整数据的情况。
通过这些步骤,读者可以了解到如何有效地将Teradata数据集成到InfoSphere Information Server中,包括数据提取、缓存策略以及不同查找方法的选择。这对于管理和分析大规模数据仓库至关重要,能够优化性能并确保数据的准确性和可用性。
使用使用InfoSphereInformationServer集成集成Teradata数据数据
使用 Teradata Connector 提取数据
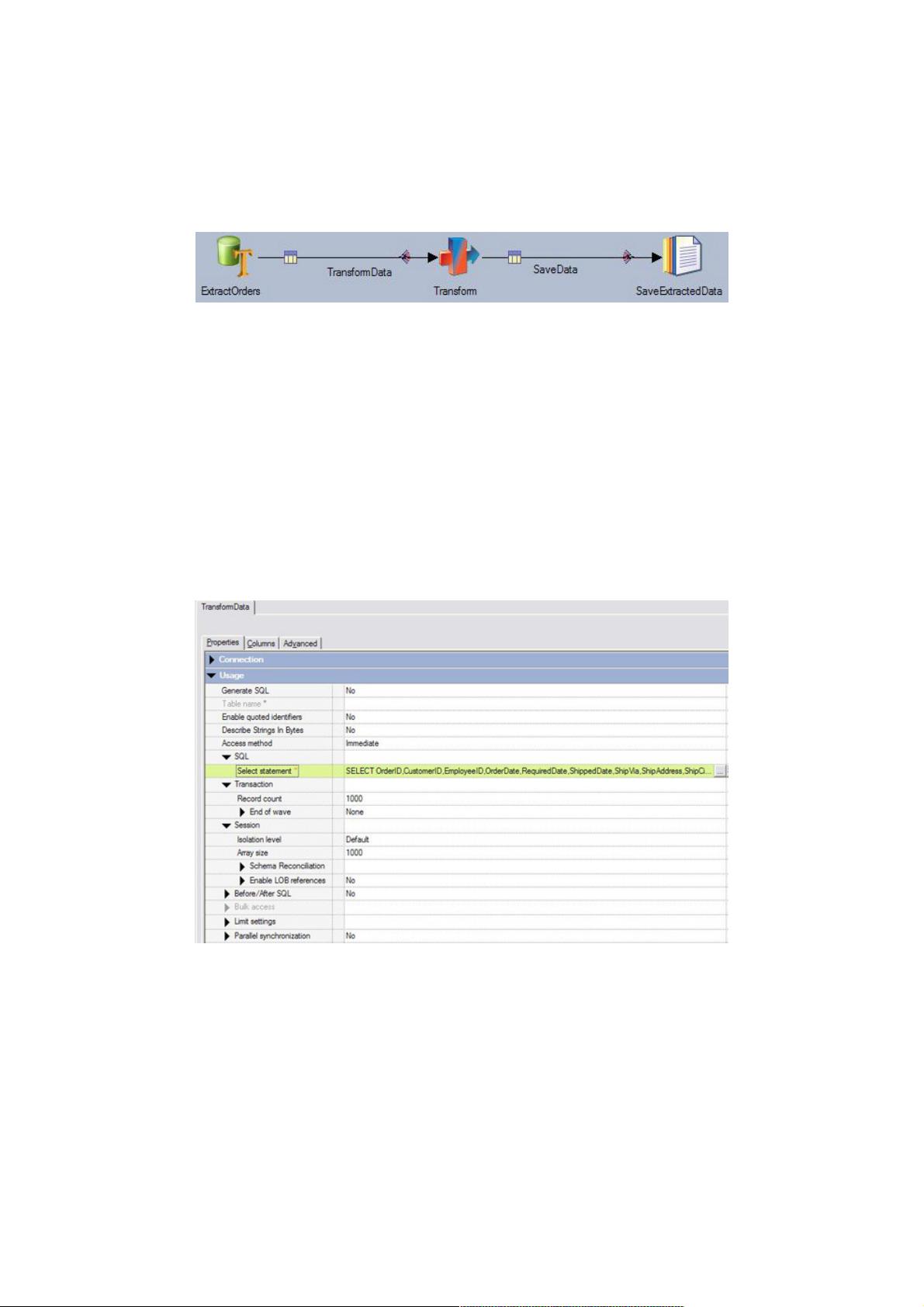
本节将使用一个示例 ETL 作业来演示从名称为 Orders 的 Teradata 表中提取数据的步骤。图 17 展示了示例作业,它使用立
即访问模式。作业使用名为 ExtractOrders 的 Teradata 连接器从 Orders 数据库读取订单。作业将转换提取的数据并将其传送
到名为 SaveExtractedData 的序列文件工作台。
ExtractOrders 连接器将使用相同的表定义,如 图 12 所示, 以及相同的连接详细信息,如 图 13 所示。
图 17. 从 Teradata Orders 表提取数据
如图 18 所示,为数据提取操作指定以下参数:
通过 Teradata DBC/SQL 分区运行 SQL 的立即访问方法。此作业只能在 DataStage 指导者节点上以序列模式运行,并且它适
合于小量数据提取。要支持并行提取大容量数据,需要配置指导者使用批量访问方法和 Teradata Parallel Transporter 导出驱
动程序。
选择语句。 指导者可以使用如 图 13 所示的表名和列定义生成 SQL。在本例中,SQL 语句将手动输入。
记录计数。 记录计数通常与 End of Wave 特性结合使用。您可以使用 End of Wave 特性将输入/输出记录划分为许多小事务,
或者工作单元。本例未使用 End of Wave 特性,并且记录计数不会影响数据提取操作。
数组大小。 数组大小主要用于为连接器缓存输入记录,以便于立即和批量加载操作。它不会对此数据提取操作造成影响。连
接器将 Teradata 数据库与连接之间通信的最大包大小设置为 64k 或者 1MB(如果 Teradata 数据库服务器通过四字节替代包
报头 (APH) 支持 1MB 大小的包)。
图 18. 设置数据提取操作
查找 Teradata 数据
本节将使用两个 ETL 作业演示根据输入记录查找 Teradata 数据的步骤。这些示例将根据输入订单 ID 查询订单详细信息。以
下小节将讨论 DataStage 支持的两种查找方法:普通查找和稀疏查找。
普通查找
对于普通查找来说,所有引用的数据都将从目标数据库中检索一次,并缓存在缓存或磁盘中。对于各输入记录,缓存引用数据
将通过交叉检查来查找结果。
图 19 展示了某示例作业的查找工作台和 Teradata 连接器,可用于执行普通查找。Teradata 连接器对 Orders 表执行完整的表
查询,并将查询结果发送给名为 NormalLookup 的查找工作台。查找 工作台将缓存查询结果并根据 OrderID 输入链接中的订
单 ID 对缓存的订单详细信息执行查找操作。结果将发送给输出链接 OrderDetails。此作业要求一次完整的表数据库查询。
下载后可阅读完整内容,剩余8页未读,立即下载
524 浏览量
235 浏览量
182 浏览量
242 浏览量
367 浏览量
点击了解资源详情

weixin_38740130
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- MakeCode项目教程:new-fall-guys-8-bit-v80
- JavaScript实现剪刀石头布游戏解析
- LabVIEW制作中国象棋游戏实例教程
- MD5_Check与SUN_MD5Check:文件完整性校验工具解析
- 西门子SITRANS LG240探头操作与维护手册下载
- 免费下载 HelveticaNeueLTStd-Roman 字体文件
- lambdex:扩展Python lambda功能实现多行代码执行
- 深入理解前端算法:JS版剑指offer题解全解析
- HiJson - 高效Json格式化与多标签操作工具
- 传智播客Android智慧北京第4日视频教程
- 李春葆《数据结构教程》实验题答案解析
- 西门子SITRANS LG270探针操作与维护指南
- 掌握theposhery-devcontainer:开发顶级容器的简便方法
- 基于MERNG堆栈开发的Sick Fits网络商店介绍
- Qt4全面教程:图形设计与嵌入式系统开发
- Braspag GitHub站点:API文档与FAQ全解析
