ODPS分布式关系型计算:大规模数据处理与集群优化
"分布式关系型计算是针对大规模数据处理的一种计算模型,主要应用于PB级别的数据处理场景。ODPS(Open Data Processing Service)是阿里云提供的一个关键组件,它设计用于支持分布式关系型计算,旨在解决海量数据存储和分析的问题。本资料可能包含了一个关于ODPS的演讲或讲座内容,涵盖了背景与概况、计算引擎、查询计划生成器以及数据安全等多个方面。
在背景与概况部分,分布式关系型计算的需求源于用户希望有一个与传统关系型数据库类似的学习曲线,以便处理PB级别的电商交易数据和日志分析。此外,它需要支持多集群跨地域协作,确保更高的数据安全性,并能够共享数据、算法和资源。面对亿级别的文件和大量作业,ODPS具备大规模集群能力,包括5000台机器、100000个CPU核心、500TB内存和100PB的磁盘容量。每天处理PB级别的IO操作,服务数百位数据开发工程师,不仅服务于阿里巴巴集团内部,也开始向第三方ISV和科研机构开放其存储和计算能力。
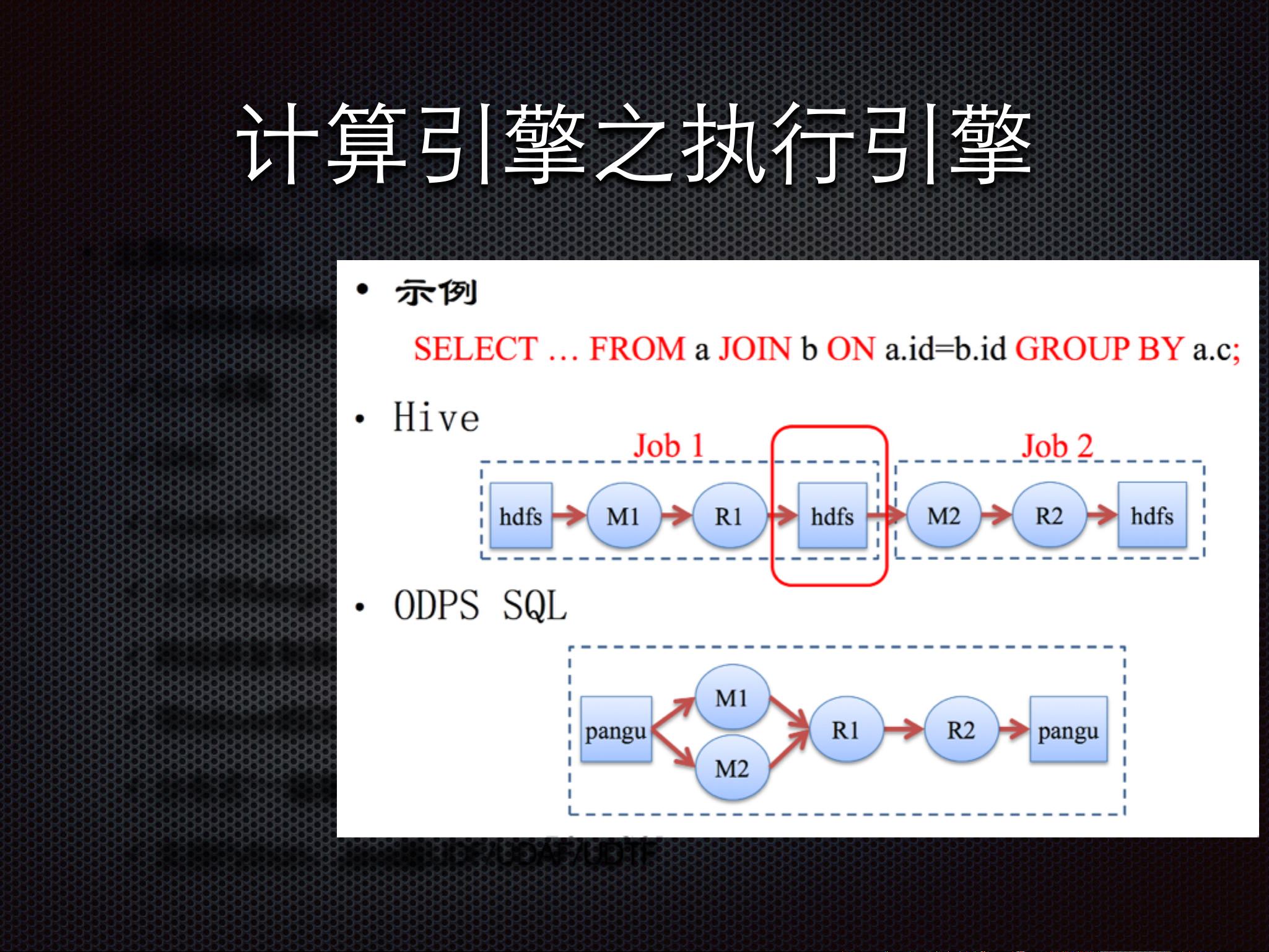
在计算引擎部分,ODPS支持全面的关系运算符和大部分SQL特性,其核心是C++实现的执行引擎,采用DAG(有向无环图)结构来优化任务调度。此外,还提及了可能的优化技术,如Code Generation,这可能涉及到动态生成优化的执行代码以提升计算效率。
查询计划生成器是ODPS的重要组成部分,负责将用户的SQL语句转化为执行计划。这个过程可能包括解析、优化和转换等步骤,确保高效地执行复杂的查询操作。系统可能通过控制集群来协调多个存储和计算集群的工作,每个集群都有自己的执行引擎来处理分配的任务。
在数据安全方面,ODPS可能提供了严格的访问控制、数据加密和审计功能,以保护用户的数据不被未授权的访问或篡改。这些安全措施对于处理敏感和大规模的企业数据至关重要。
Q&A环节可能涵盖了用户关心的具体问题,例如性能优化、故障恢复、扩展性和新功能的引入等。这部分未提供具体细节,但通常会涉及实际使用中的常见挑战和解决方案。
分布式关系型计算通过ODPS这样的平台,为企业提供了强大的大数据处理能力,支持灵活的计算需求,同时兼顾数据安全和协作效率,是现代大数据场景下的重要技术工具。"

计算引擎之执引擎
•
主要feature
✓
持所有的关系运算符,持部分的SQL特性
✓
C++实现
✓
DAG
✓
Code Gen
✓
件Merge
✓
跨级群复制和直读直写
✓
带failover的DDL
✓
分布式“级缓存”上的热点表和热点资源
✓
持Python、Java版UDF/UDAF/UDTF
剩余36页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-14 上传
2021-08-08 上传
2021-08-08 上传
2021-10-11 上传
2021-10-11 上传
2023-04-06 上传

亚洲家叔
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
