WinBUGS用户手册:入门与MCMC方法解析
"WinBUGS用户手册,版本1.4,2003年1月。由David Spiegelhalter, Andrew Thomas, Nicky Best和Dave Lunn编写,主要来自英国剑桥MRC生物统计单位和伦敦帝国学院公共卫生学院。手册提供对WinBUGS的全面介绍,特别适合新手。"
WinBUGS是一款流行的概率编程软件,主要用于贝叶斯统计分析,特别是马尔科夫链蒙特卡洛(MCMC)方法。这个用户手册详细介绍了如何使用该软件,并给出了对新手的建议。
1. **WinBUGS简介**:
- WinBUGS是BUGS(Bayesian Inference Using Gibbs Sampling)的Windows版本,它提供了图形用户界面,便于用户输入模型代码和管理数据。
- 本手册是为初学者设计的,旨在帮助他们理解和操作WinBUGS进行贝叶斯分析。
2. **MCMC方法**:
- MCMC是WinBUGS的核心算法,用于在高维参数空间中模拟后验分布。它是解决复杂贝叶斯模型的关键工具。
- 手册会详细解释MCMC的工作原理,包括Gibbs采样和Metropolis-Hastings算法。
3. **WinBUGS语法与Classic BUGS的区别**:
- 说明书中会对比WinBUGS和经典BUGS的语法差异,这对于从其他版本或平台转用WinBUGS的用户尤其有用。
4. **注意事项**:
- 用户被警告使用WinBUGS进行严肃的统计分析时需要谨慎,因为软件可能会出现错误或异常,可能导致不准确的结果。
- 手册强调了报告任何成功或失败案例的重要性,以帮助改进软件。
5. **变更记录**:
- 内容中提到了“Changes”,这通常意味着手册包含了WinBUGS版本1.4相较于之前版本的更新和改进列表。
对于想要深入学习贝叶斯分析和WinBUGS的读者,这份手册提供了全面的指导,包括基本概念、编程语法、示例模型和实际应用。尽管是英文版,但对于有基础的读者来说,这是一个宝贵的资源,可以帮助他们掌握如何使用WinBUGS进行有效的贝叶斯建模和推断。

The BUGS language: stochastic nodes
Censoring and truncation
Constraints on using certain distributions
Logical nodes
Arrays and indexing
Repeated structures
Data transformations
Nested indexing and mixtures
Formatting of data
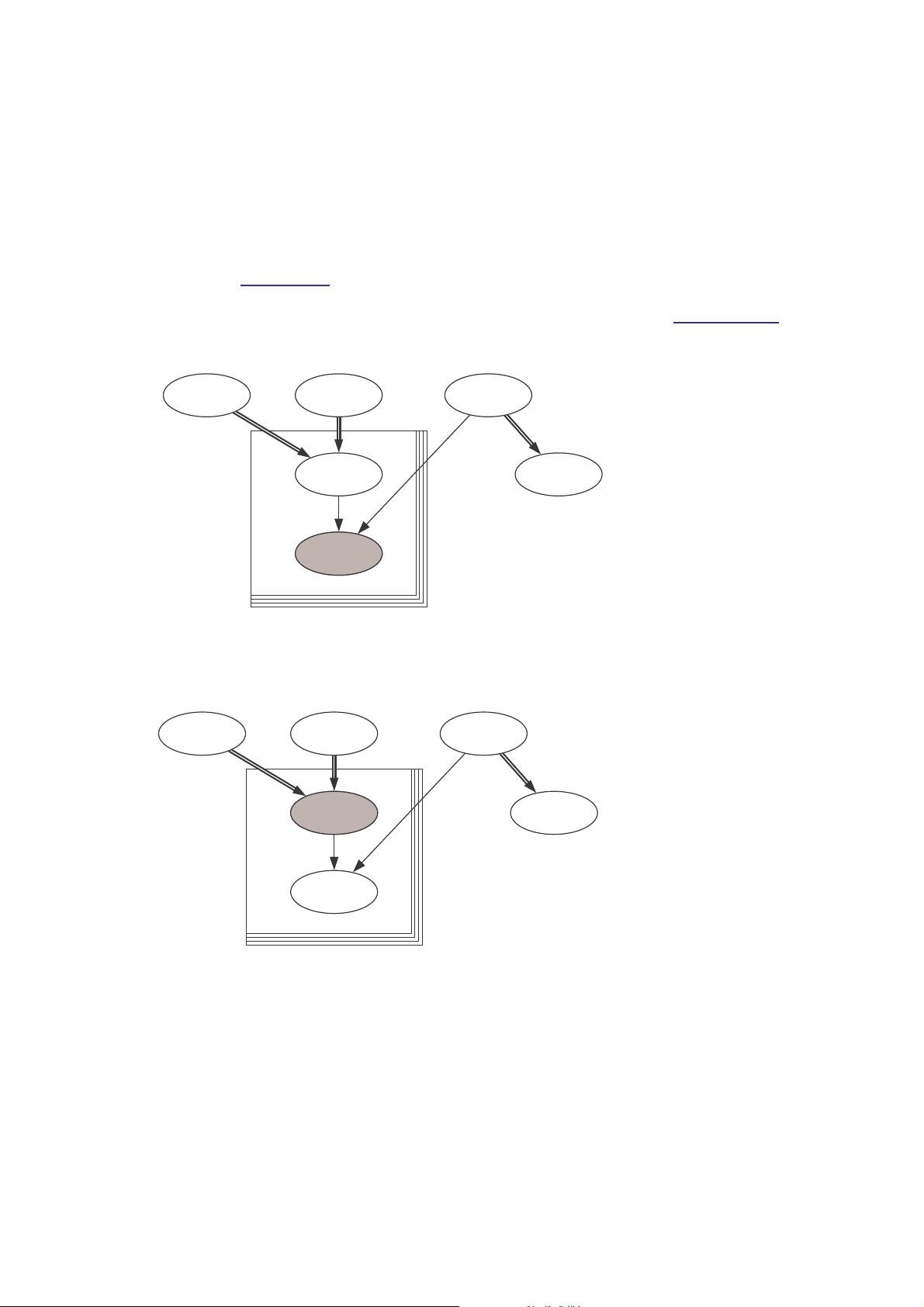
Graphical models [ top | home ]
We strongly recommend that the first step in any analysis should be the construction of a directed graphical
model. Briefly, this represents all quantities as nodes in a directed graph, in which arrows run into nodes from
their direct influences (parents). The model represents the assumption that, given its parent nodes pa[v], each
node v is independent of all other nodes in the graph except descendants of v, where descendant has the
obvious definition.
Nodes in the graph are of three types.
1. Constants are fixed by the design of the study: they are always founder nodes (i.e. do not have parents),
and are denoted as rectangles in the graph. They must be specified in a data file.
2. Stochastic nodes are variables that are given a distribution, and are denoted as ellipses in the graph;
they may be parents or children (or both). Stochastic nodes may be observed in which case they are
data, or may be unobserved and hence be parameters, which may be unknown quantities underlying a
model, observations on an individual case that are unobserved say due to censoring, or simply missing
data.
3. Deterministic nodes are logical functions of other nodes.
Quantities are specified to be data by giving them values in a data file, in which values for constants are also
given.
Directed links may be of two types: a solid arrow indicates a stochastic dependence while a hollow arrow
indicates a logical function. An undirected dashed link may also be drawn to represent an upper or lower
bound.
Repeated parts of the graph can be represented using a 'plate', as shown below for the range (i in 1:N).
A simple graphical model, where Y[i] depends on mu[i] and tau, with mu[i]
being a logical function of alpha and beta.
The conditional independence assumptions represented by the graph mean that the full joint distribution of all
quantities V has a simple factorisation in terms of the conditional distribution p(v | parents[v]) of each node
for(i IN 1 : N)
sigma
taubetaalpha
mu[i]
Y[i]
for(i IN 1 : N)
index: i from: 1 up to: N

剩余59页未读,继续阅读
2011-07-27 上传
2008-04-29 上传
2014-11-05 上传
2011-12-03 上传
2018-10-17 上传
2019-10-05 上传

veterinarian0
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新代数控API接口实现CNC数据采集技术解析
- Java版Window任务管理器的设计与实现
- 响应式网页模板及前端源码合集:HTML、CSS、JS与H5
- 可爱贪吃蛇动画特效的Canvas实现教程
- 微信小程序婚礼邀请函教程
- SOCR UCLA WebGis修改:整合世界银行数据
- BUPT计网课程设计:实现具有中继转发功能的DNS服务器
- C# Winform记事本工具开发教程与功能介绍
- 移动端自适应H5网页模板与前端源码包
- Logadm日志管理工具:创建与删除日志条目的详细指南
- 双日记微信小程序开源项目-百度地图集成
- ThreeJS天空盒素材集锦 35+ 优质效果
- 百度地图Java源码深度解析:GoogleDapper中文翻译与应用
- Linux系统调查工具:BashScripts脚本集合
- Kubernetes v1.20 完整二进制安装指南与脚本
- 百度地图开发java源码-KSYMediaPlayerKit_Android库更新与使用说明
