Elasticsearch分布式搜索实战:亿条数据检索与优化解析
需积分: 23 144 浏览量
更新于2024-07-20
收藏 221KB DOCX 举报
"这篇文档是关于Elasticsearch (ES) 的实战技术分享,基于作者在处理亿条数据检索的公司项目经验,涵盖了从理论基础到实际应用,再到性能调优的全过程。文档主要关注ES 1.6版本,强调了其分布式、高可靠性的特性,并介绍了核心概念如集群(cluster)、分片(shards)、副本(replicas)、数据恢复(recovery)、river(数据源)、gateway(索引快照存储)以及自动发现节点机制(discovery.zen)。"
在深入探讨Elasticsearch之前,我们需要理解一些基本概念:
1. 集群(Cluster): 集群是由多个节点组成的,其中一个作为主节点负责协调任务。ES的设计使得集群对外表现为单一实体,无论与哪个节点交互,都能访问到整个集群的数据。
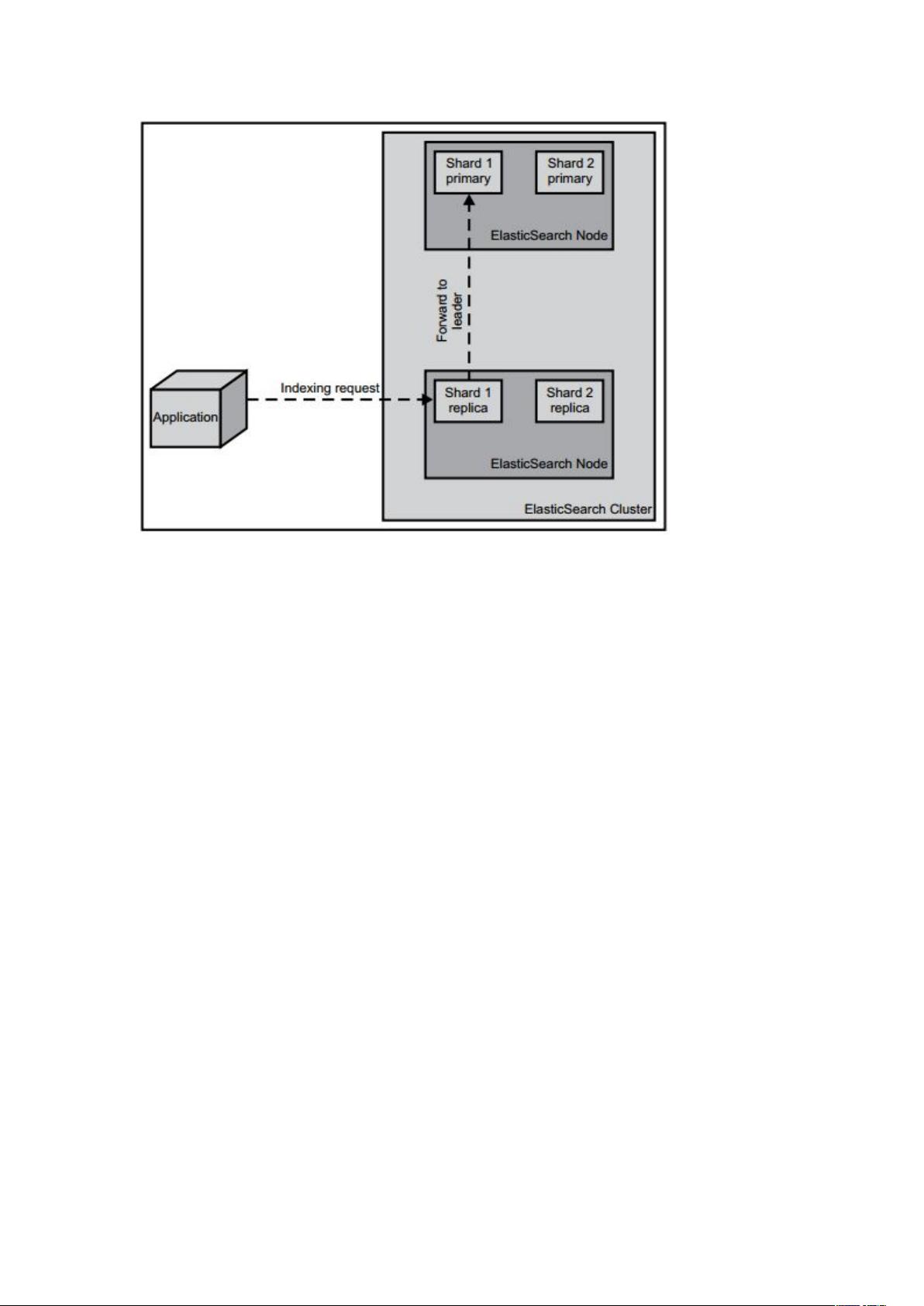
2. 分片(Shards): 分片是索引的组成部分,允许将大型索引拆分为较小、更易管理的部分,分布到不同节点上,实现分布式搜索。分片数量在索引创建时预设,之后不可更改。
3. 副本(Replicas): 副本用于提高系统容错性和查询效率。如果某个节点或分片失效,可以从副本中恢复,同时,搜索请求可以被分发到副本上,实现负载均衡。
4. 数据恢复(Recovery): 当节点加入、退出或重启时,ES会调整分片分布,确保数据完整性。这包括数据的重新分布和故障节点的数据恢复。
5. River: River是一个数据同步工具,用于将数据从其他存储系统(如数据库、消息队列等)实时同步到ES。尽管在较新版本中已被废弃,但在早期版本中,如ES 1.6,它是数据集成的重要部分。
6. Gateway: Gateway负责保存索引的快照,当集群重启时,从这些快照中恢复数据。ES支持多种类型的Gateway,包括本地文件系统、分布式文件系统、HDFS和S3。
7. 自动发现节点机制(Discovey.zen): 这是ES如何找到和通信其他节点的方式,通过广播和多播协议确保节点间的通信,并能应对节点动态增减的情况。
这份实战文档不仅介绍了这些核心概念,还可能涵盖了设置、配置、优化和问题排查等方面的内容,这对于理解和操作大规模ES部署非常有价值。读者可以期待了解到如何在实际项目中应用这些理论,包括如何处理海量数据、如何设计适合的索引结构、如何配置副本以优化容错性和性能,以及如何利用ES的自动发现机制来维持集群的稳定性。此外,文档可能还会涉及监控、日志分析、查询优化等高级主题,帮助开发者更好地管理和利用ES的潜力。
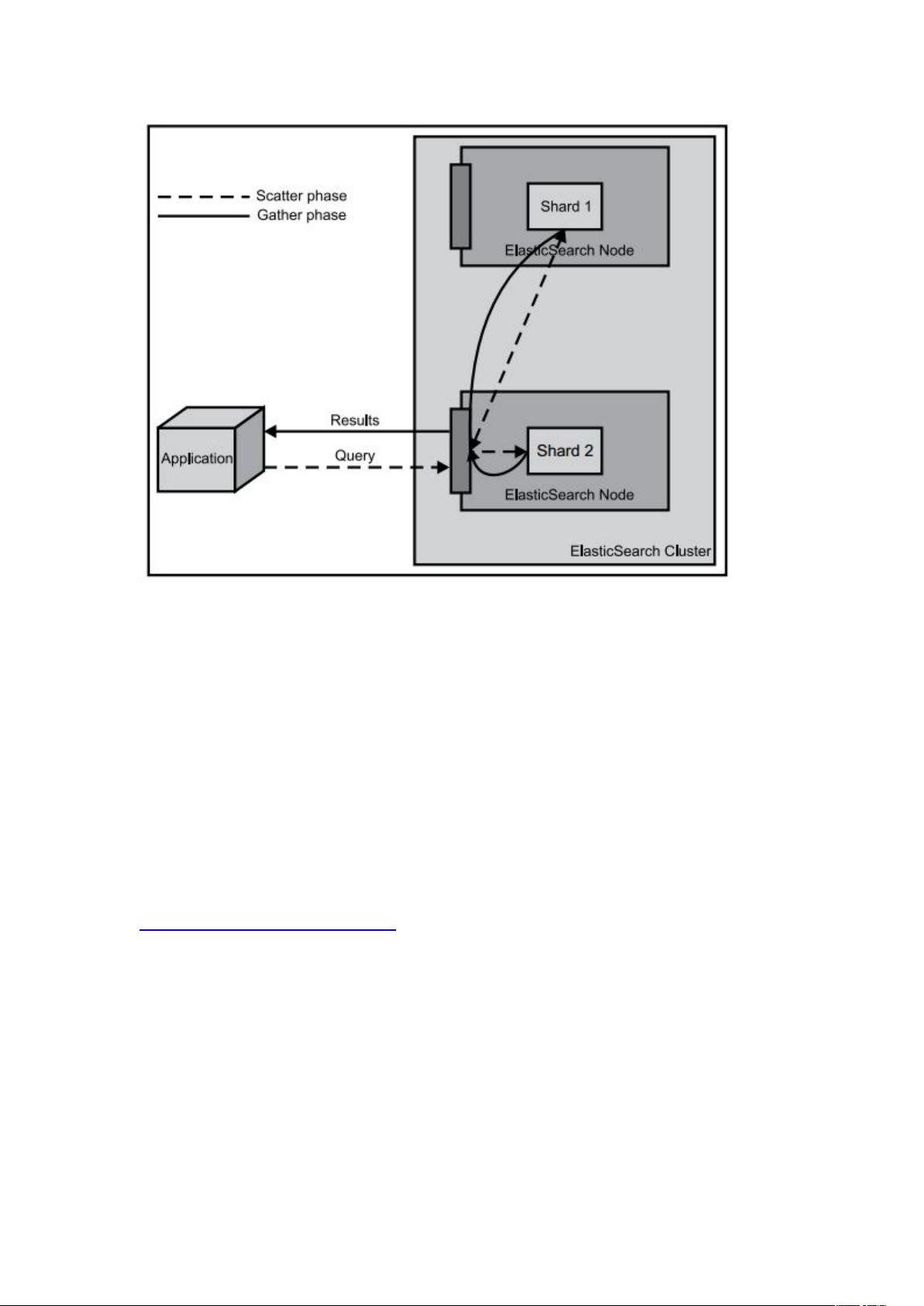
1.3.4 数据查询
使 用各 种类 型的 查询 方式 , 包括 :简 单 的 关 键 词 查 询 短 语 区 间
、布尔、模糊、跨度、通配符、地理位置等其
他查询方式;
使用各种类型的查询构建出复杂的查询;
通过 构建动态的导航和数据统计。
使用 而且找到匹配文档的查询语句。
数据搜索方式 种可选值。
剩余31页未读,继续阅读
点击了解资源详情
点击了解资源详情
9774 浏览量
811 浏览量
473 浏览量
2024-06-07 上传
158 浏览量
106 浏览量
974 浏览量

blackoon88
- 粉丝: 651
- 资源: 26
 我的内容管理
展开
我的内容管理
展开







最新资源
- Excel模板价格敏感度分析.zip
- Prova-2019-01-topicos-1-revisao:节目提要(Prova deTópicosdeprogramaçãoweb 1)
- DuetSetup-1-6-1-8_2.rar
- 行业文档-设计装置-大深度水下采油平台控制器.zip
- laughing-octo-train
- AD7798-99官方驱动程序.rar
- mathgenerator:数学问题生成器,其创建目的是使自学的学生和教学组织能够轻松地访问高质量的生成的数学问题以适应他们的需求
- instagram-ruby-gem, Instagram API的官方 gem.zip
- lodash-sorted-pairs:使用lodash从对象中获取排序对(键,值)
- 19-ADC模数转换实验.zip
- Hercules_FEE_2.rar
- talk-2-group2
- DragView:Android库,用于根据类似于上一个YouTube New图形组件的可拖动元素创建出色的Android UI
- comfortable-mexican-sofa, ComfortableMexicanSofa是一款功能强大的Rails 4/5 CMS引擎.zip
- mysql-5.6.5-m8-winx64.zip
- Audiovisualizer-web-app:基于画布的音频可视化器web应用程序。 控件密集的界面使用户能够调整应用程序的许多特性
