NVIDIA CUDA深度探讨:Fermi架构与高级调度策略
68 浏览量
更新于2024-07-14
收藏 2.47MB PDF 举报
Advanced Topics in CUDA - 2011年的这些幻灯片由NVIDIA的Cliff Woolley提供,涵盖了CUDA编程高级概念,特别是针对NVIDIA Fermi架构的GPU技术。该课程详细讨论了以下关键知识点:
1. **Scheduling**: 在CUDA编程中,调度是至关重要的,它涉及到如何在GPU的流多处理器(Stream Multiprocessor, SM)上安排和管理任务。SM中的工作负载被分发到不同的执行单元,如线程块和线程,以实现高效的并行计算。
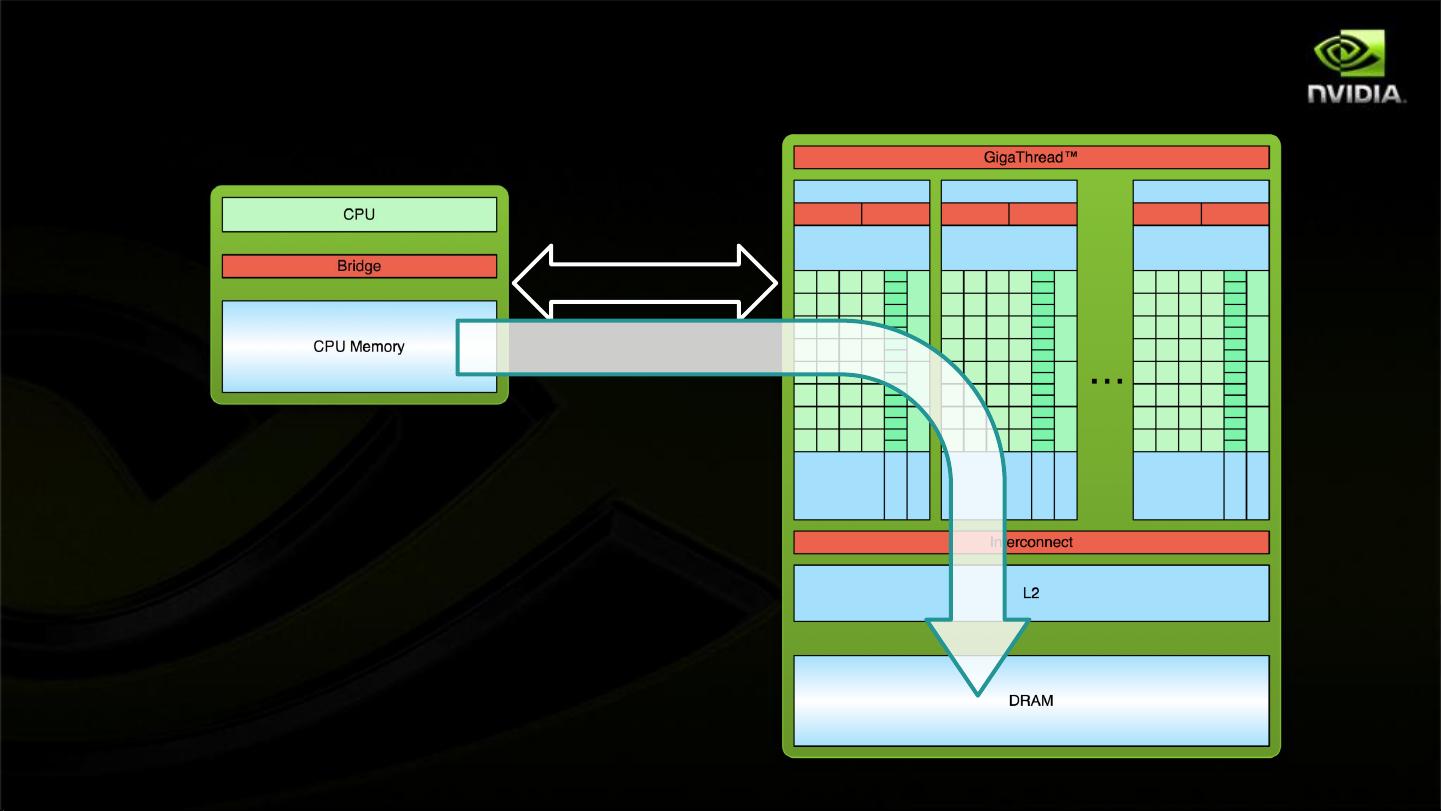
2. **GPU Architecture - Fermi**: 这部分着重于Fermi架构的设计,它包括CUDA核心(CUDACore),这是GPU的核心计算单元。CUDA核心支持浮点和整数运算,采用IEEE 754-2008标准,具备单精度和双精度的 fused multiply-add (FMA) 指令,提升计算性能。
3. **硬件组件**:
- **Floating Point Unit (FPUnit)**: 负责执行浮点运算,包括加、减、乘、除等操作。
- **Integer Unit (INTUnit)**: 处理整数运算,与浮点运算单元配合执行算术和逻辑操作。
- **Logic Unit**: 执行基本的逻辑操作,如比较和移动数据。
- **Branch Unit**: 管理分支控制流程,执行条件转移指令。
- **Register File**: 存储临时数据,提高计算速度,每个核心有其自己的寄存器。
- **Dispatch**: 从全局内存读取指令并将其分派到适当的执行单元。
- **Load/Store Units**: 处理内存访问,每个SM通常有16个这样的单元。
- **Special Function Units (SFUs)**: 用于特定数学或逻辑运算,如平方根、矩阵乘法等,这里有4个。
- **Interconnect Network**: GPU内的高速通信网络,用于不同部件之间的数据交换。
4. **Memory Hierarchy**: GPU有64KB的可配置缓存和共享内存,以及一个统一的缓存,用于快速访问。核心与缓存之间的交互是关键,决定着计算性能。
5. **Latency vs. Throughput**: CPU设计注重低延迟,每个核心专注于独立的任务;而GPU通过并行处理多个线程来隐藏延迟,追求高吞吐量。这反映了两种架构在设计上的主要区别,即针对不同的应用场景优化。
6. **Stream Multiprocessor vs. CPU Core**: GPU的SM作为高吞吐量处理器,能同时处理大量线程,适合数据密集型计算。相比之下,CPU的核心更倾向于低延迟,适合需要即时响应的任务。
这些幻灯片深入介绍了CUDA编程中的高级概念,特别关注NVIDIA Fermi架构下的GPU特性,有助于理解并利用GPU进行高效并行计算。对于开发者来说,理解这些细节对于充分利用CUDA进行大规模并行处理至关重要。
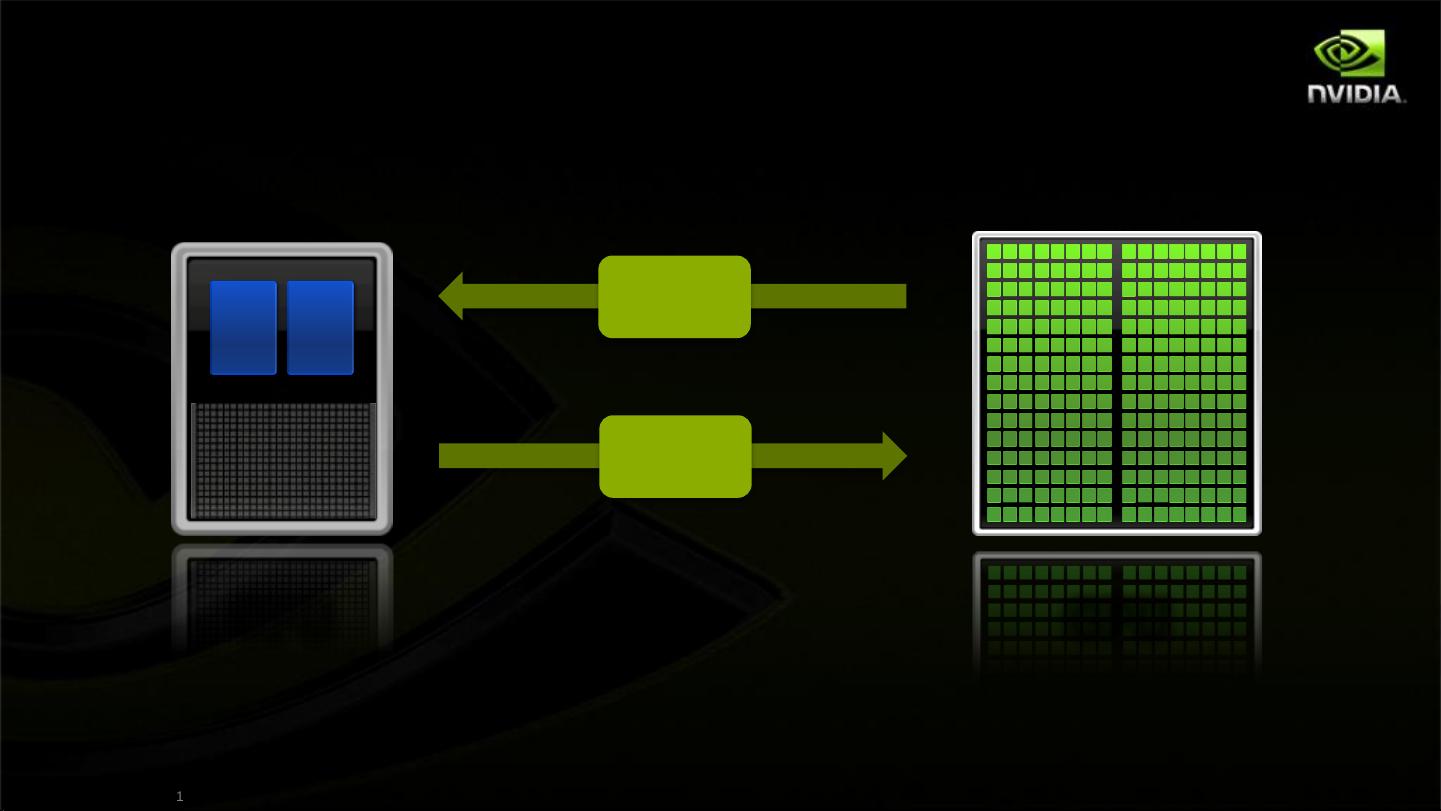
© NVIDIA Corporation 2011
Available engines
GPU
CPU
DMA
DMA
剩余43页未读,继续阅读
2021-10-25 上传
2021-04-22 上传
2021-04-22 上传
2021-04-22 上传
2021-04-22 上传
2021-04-22 上传
2021-04-22 上传
2021-04-22 上传

weixin_38657139
- 粉丝: 9
- 资源: 955
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
