GPU并行计算详解:CUDA编程与线程模型
需积分: 12 176 浏览量
更新于2024-09-11
收藏 94KB PPTX 举报
"本文档详细介绍了GPU并行计算,特别是NVIDIA公司的CUDA技术,适合对GPU计算感兴趣的读者作为参考。内容涵盖了CPU与GPU的结构对比、CUDA编程模型、线程组织、内存管理以及同步机制等核心概念。"
并行计算是计算机科学中的一种重要技术,尤其在处理大规模数据和高性能计算时,GPU并行计算展现了巨大的潜力。NVIDIA公司的CUDA(Compute Unified Device Architecture)是一种广泛使用的GPU编程框架,使得开发者能够利用GPU的强大计算能力进行高效编程。
CPU(中央处理器)主要包括控制单元、逻辑运算单元和存储单元,而GPU(图形处理器)设计的目标是处理大量并行的图形计算任务。相比CPU,GPU拥有更多的执行单元,专为并行计算优化,能够同时处理大量简单的计算任务。
在CUDA编程模型中,GPU的计算单元被称为Core,多个Core集成在流多处理器(SM)中。线程是计算任务的基本执行单元,它们可以被组织成线程块,并进一步分解为线程束。每个线程束由一个SM执行,采用SIMT(Single Instruction Multiple Threads)模式,即单指令多线程,让所有线程同时执行同一指令。
CUDA提供了特殊的函数标识符,如`__global__`、`__device__`和`__host__`,用于区分函数在CPU或GPU上的执行位置。在GPU上运行的代码需要通过`cudaMalloc`、`cudaMemcpy`和`cudaFree`等函数管理内存,以在CPU和GPU之间传输数据。
线程的组织结构在CUDA中十分关键,可以是1D、2D或3D形式,由线程块和线程格构成。线程ID是每个线程的唯一标识,可用于定位和区分不同的线程。线程块内的线程可以通过共享内存进行通信和协作,共享内存速度较快,但容量有限。为了确保线程间的同步,可以使用CUDA提供的同步函数,如`__syncthreads()`,以确保特定操作在所有相关线程执行完毕后再继续。
深度学习和性能优化等领域常常利用GPU的并行计算能力,嵌入式系统也逐渐开始采用GPU进行加速计算。理解并掌握GPU并行计算和CUDA编程,对于提升计算效率、优化算法性能具有重要意义。
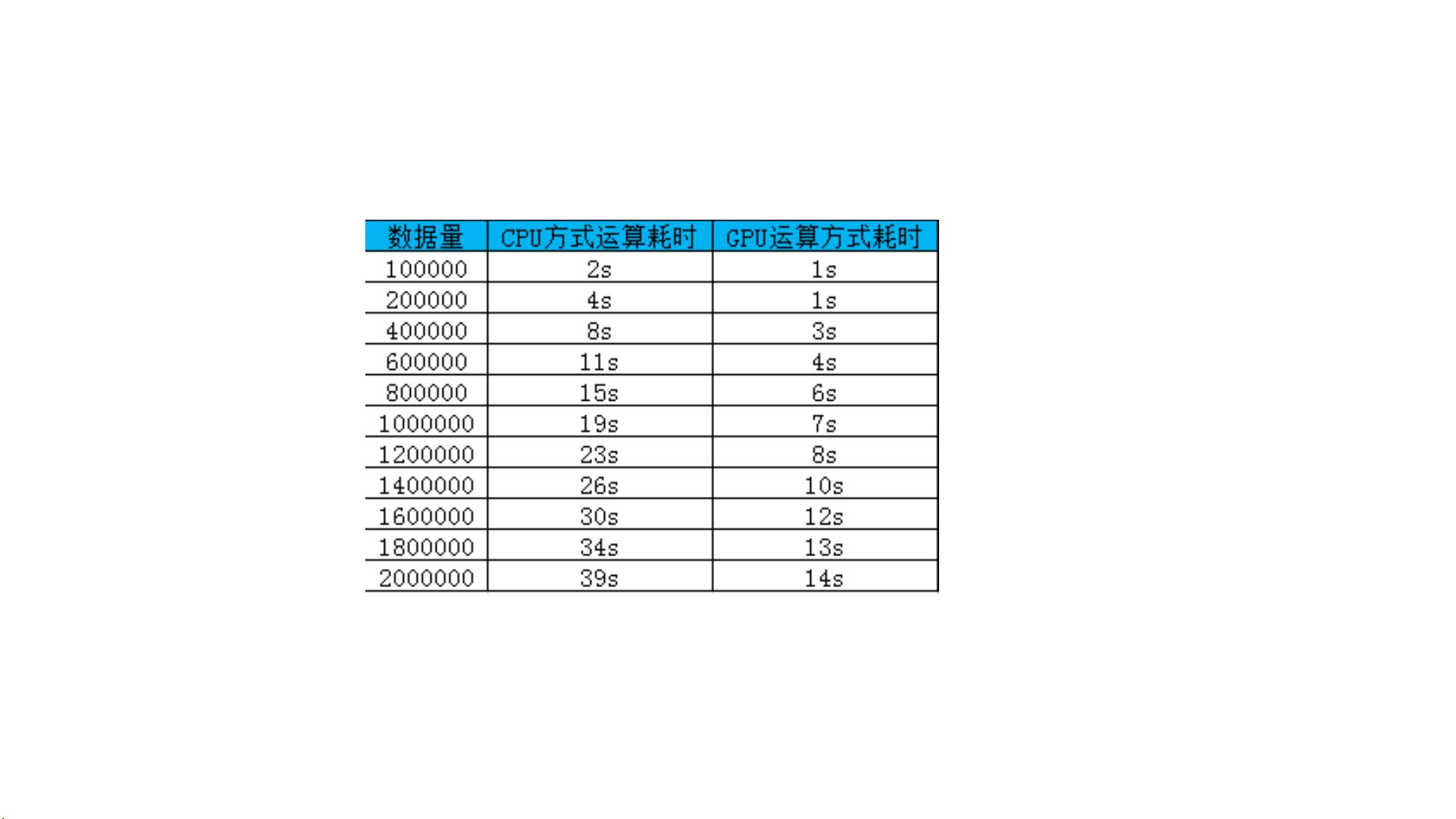
CPU 与 GPU 的对比
剩余10页未读,继续阅读
574 浏览量
1854 浏览量
256 浏览量
540 浏览量
点击了解资源详情
263 浏览量
438 浏览量

manbusongbo
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Apache Flink流处理技术详解及应用操作
- VB计时器软件开发与源代码分析
- FW300网卡驱动最新下载与安装指南
- Altium Designer9原理及PCB库指南:涵盖STM32F103/107封装
- Colton Ogden开发的pongGame游戏教程
- 龙族rmtool服务器管理工具源码开放
- .NET反汇编及文件处理工具集下载使用介绍
- STM32 EEPROM I2C中断DMA驱动实现
- AI122/AI123可编程自动化控制器详细数据手册
- 触控笔LC谐振频率测试程序实现与展示
- SecureCRT 7.3.3 官方原版下载指南
- 力反馈功能增强:Arduino游戏杆库使用指南
- 彼岸鱼的GitHub项目HiganFish概述与统计
- JsonUtil工具类:实现对象与Json字符串间转换
- eNSP企业网络拓扑设计:全网互通与带宽优化策略
- 探索3D Lindenmayer系统在3D建模中的应用
