QAConv:信息性对话的问答数据集与模型提升
121 浏览量
更新于2024-06-19
收藏 22.71MB PDF 举报
QAConv是一项重要的研究,它聚焦于信息性对话的问答数据集和模型开发。相较于开放领域的闲聊和任务导向对话,信息性对话如商务邮件、在线会议和工作聊天室具有独特的特性,如长篇幅、复杂性、非实时性和涉及深厚的专业知识。研究者们从10,259个多样化的对话中提炼出34,204个问答对,这些问题涵盖了不同类型的挑战,如跨段落的问题、自由形式提问和难以回答的问题,其中包括人工设计和机器自动生成的问题。
数据集的收集过程中,通过将长对话划分为可管理的块,并利用问题生成器和对话摘要生成器工具来创建多跳问题,旨在模拟真实世界的信息查询场景。数据集提供了两种测试模式:块模式和完整模式,前者要求模型仅依赖当前对话块中的信息,后者则允许模型利用整个对话历史。这反映了实际应用中可能遇到的不同情景。
实验结果显示,目前最先进的QA系统在面对信息性对话的零样本迁移学习时表现不佳,往往无法准确处理这类对话中的问题。通过在QAConv数据集上进行微调,可以显著提升系统的性能,例如在块模式和完整模式下分别提高了23.6%和13.6%的准确率。
QAConv的研究填补了对话理解和文档理解之间的空白,强调了对话数据格式和语言风格对模型训练的重要性。尽管对话AI领域的研究先前更多关注于对话问答,但QAConv的数据集和研究方法为更深入地探究信息性对话的问答问题提供了有价值的资源。这对于构建能够适应各种情境,特别是需要综合运用领域知识的智能问答系统具有重要意义,有助于推动人工智能技术在实际商业应用中的发展。
4
0
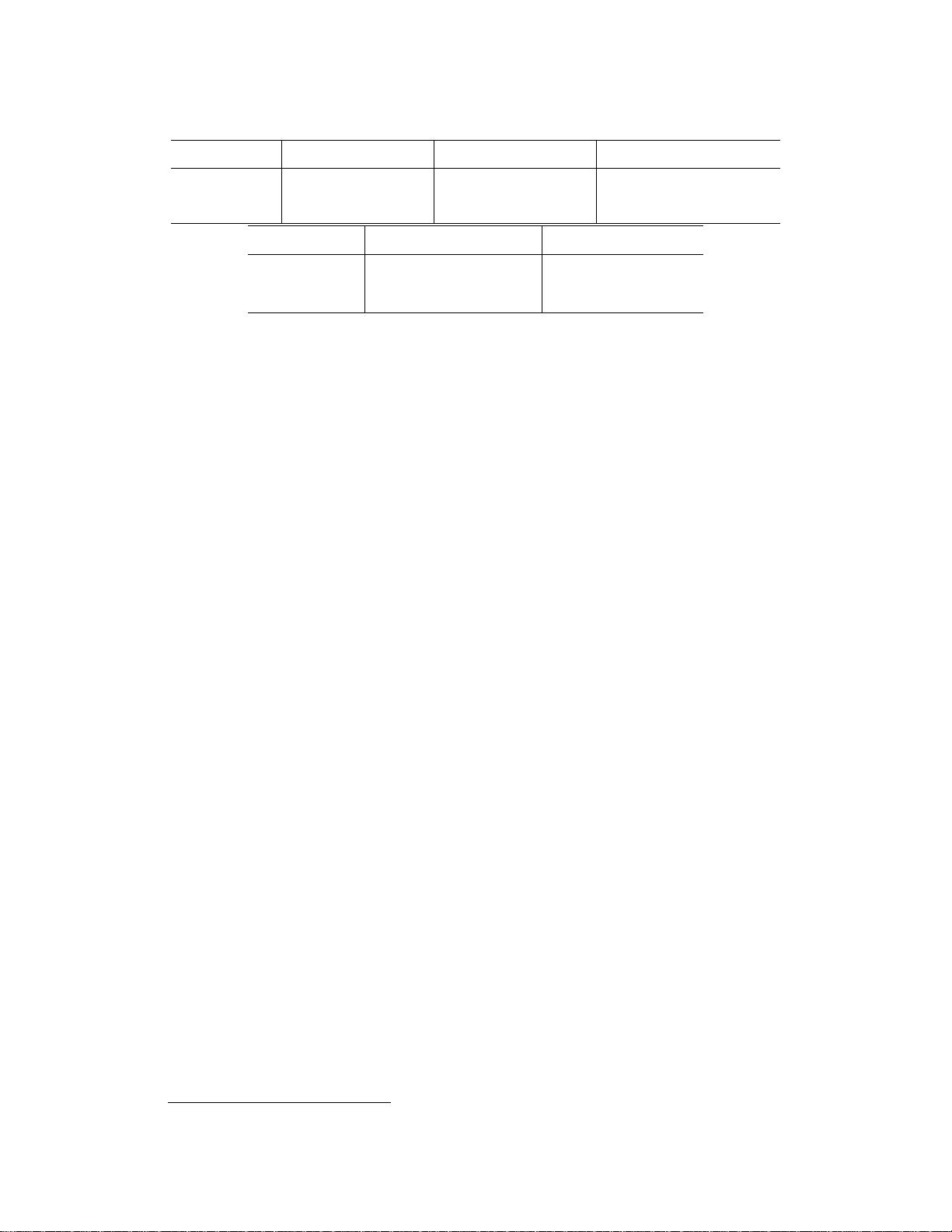
表2:不同对话来源的数据集统计信息。
0
BC3EnronCourt
0
完整块完整块完整块
0
问题16480969456对话40843,2574,2201254,923平均/最大单词数514.9/1,236245.2/593383.6/69,13
285.8/6,78713,143.4/19,917330.7/1,551平均/最大发言者数4.8/82.7/62.7/102.2/810.3/142.7/7
0
媒体Slack
0
完整块完整块
0
问题9,1555,599对话6994,8126,1384,689平均/最大单词数2,009.6/11,851
288.7/537247.2/4,777307.2/694平均/最大发言者数4.4/322.4/112.5/
154.3/14
0
提取的实体。我们假设这些问题是可以轻松找到答案的平凡问题,因此对于我们的数据集来说并不有
趣。
0
2.1.3众包QA对
0
我们使用两种策略来收集QA对,即人类作者和机器生成器。我们首先要求众包工作者阅读部分对话
,然后我们随机分配设置,要么让他们自己编写QA对,要么选择一个推荐的机器生成的问题来回答
。我们应用了几个即时约束条件来控制收集到的QA对的质量:1)问题应该有超过6个单词,并以问
号结尾,至少有10%的单词必须出现在源对话中;2)问题和答案不能包含第一人称和第二人称代词
(例如,我,你等);3)答案必须少于15个单词,并且所有单词必须出现在源对话中,但不一定来
自同一文本片段。
0
我们从问题池中随机选择四个MG问题,并要求众包工作者回答,不提供我们的预测答案。他们可以
根据需要修改问题。为了收集无法回答的问题,我们要求众包工作者编写至少提及给定对话中的三个
实体但无法回答的问题。我们向众包工作者支付大约每小时8-10美元的报酬,平均阅读和编写一个Q
A对的时间约为4分钟。
0
2.1.4质量验证和数据拆分
0
我们设计了一种基于不同答案的过滤机制:人类作者的答案、现有QA模型的答案以及QG问题的答案
。如果所有答案的配对模糊匹配比(FZ-R)得分都低于75%,我们将进行另一轮众包调查,并要求
众包工作者选择以下选项之一:A)QA对看起来不错,B)问题无法回答,C)问题的答案错误,D)
问题的答案正确,但我更喜欢另一个答案。我们在大约40%的不确定样本上运行此步骤。我们过滤(
C)选项的问题,并将(D)选项的答案添加到真实答案中。对于标记为(B)选项的问题,我们将它
们与我们收集到的无法回答的问题结合起来。此外,我们还将1%的随机问题(从其他对话中抽样的
问题)包含在相同的数据收集批次中,并且如果众包工作者未能将此类问题标记为(B)选项,则过
滤其结果。最后,我们根据每个对话源内的抽样将数据分为80%的训练集,10%的验证集和10%的
测试集,结果为27,287个训练样本,3,414个验证样本和3,503个测试样本。在训练、验证和测试集中
,无法回答的问题分别占4.7%、4.8%和5.8%。
0
2.2QA分析
0
在本节中,我们分析了我们收集的问题和答案。我们首先调查问题类型的分布,并比较人工编写的问
题和机器生成的问题。然后,我们通过现有的命名实体识别(NER)模型和成分解析器分析答案。
0
2https://pypi.org/project/fuzzywuzzy
0
+v:mala2277获取更多论文
剩余16页未读,继续阅读
2021-05-15 上传
点击了解资源详情
2024-12-20 上传
2024-12-20 上传
2024-12-20 上传
2024-12-20 上传
2024-12-20 上传
2024-12-20 上传
2024-12-20 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易语言-易语言超级模块9.0开源
- pygarena:GSMArena的5G电话数据库
- Kollective SE Helper-crx插件
- Note-On-MassZeroSABR:Py的“关于期权价格的注释和“不相关的SABR模型中的零质量和隐含波动率渐近”的Py实现
- vscode配置cc++环境.zip
- mvnmon:在您的GitHub存储库中自动更新Maven依赖项
- nova-fields:可自定义的Nova字段的集合
- kobe24:用于学习和教授基础编程的编程语言
- 浮云E绘图高级Demo_业务配置化_复合图元动态更新_电路原理图更新
- 易语言-御风超级列表框模块
- Web上的帮助选项要求
- company-website:tenxtend的第一个版本
- JAVA爬虫项目实战源码+实战案例+源码分享+案例库
- audiotest
- php-aws-iot-manager
- python-exe-commandline-example:可执行应用程序的 Python 命令行示例
