诺信热熔胶机ProBlue系列用户使用手册
需积分: 50 147 浏览量
更新于2024-07-09
1
收藏 1.92MB PDF 举报
"诺信热熔胶机用户使用手册"
诺信热熔胶机是一款由诺信公司生产的专业设备,广泛应用于各种行业的粘接和封装工艺。诺信公司在全球享有盛誉,尤其在精密流体控制领域有深厚的技术积累。本用户手册详细介绍了诺信的ProBlue系列胶机,包括P4、P7以及P10等多种机型,旨在为客户提供全面的操作指导和维护建议。
1. ProBlue系列胶机介绍:
ProBlue系列是诺信热熔胶机的核心产品,适用于不同生产环境和需求。这些胶机设计精良,具备高效、精准的胶水分配能力,能够在连续作业中保持稳定的胶液流量,确保生产线的高效运行。
2. 机型特点:
- P4机型:可能是一款入门级的热熔胶机,适合小型企业或轻型生产需求,具备基本的胶水熔化和分配功能。
- P7机型:可能具有更先进的控制和调节功能,适合中等规模的生产线,提供更精确的胶量控制。
- P10机型:作为高端机型,可能具备更高的产能和更复杂的工作模式,适合大规模生产和高精度应用。
3. 客户使用手册:
客户使用手册是用户操作和维护诺信热熔胶机的重要参考文献,包含了设备的安装步骤、操作指南、故障排查方法和保养维护建议。通过详细阅读手册,用户可以学习如何安全、有效地使用设备,避免误操作,延长设备寿命。
4. 技术支持与服务:
诺信公司提供了多渠道的技术支持,用户可以通过官方网站(www.nordson.com)获取信息,或者直接致函客户服务部门获取帮助。诺信鼓励用户反馈问题、建议和意见,以持续改进产品和服务。
5. 版权与商标声明:
手册强调了诺信公司对其出版物的版权保护,并指出未经许可,不得擅自复制或翻译。同时,手册列出了诺信公司一系列的注册商标,彰显了公司的知识产权和品牌价值。
6. 信息更新:
诺信公司保留对出版物中包含的信息进行修改的权利,用户应关注最新的技术更新和安全提示,以确保设备的正确使用。
诺信热熔胶机用户使用手册不仅提供了详细的设备操作指南,还体现了诺信公司对产品质量和服务的承诺。对于任何使用诺信热熔胶机的用户来说,理解和掌握这份手册的内容都是至关重要的。

安全 1-10
A1EN-01-[XX-安全]-10
E 2002 诺信公司
4–02手册
一般安全提警告
一般安全提警告一般安全提警告
一般安全提警告
(继续)
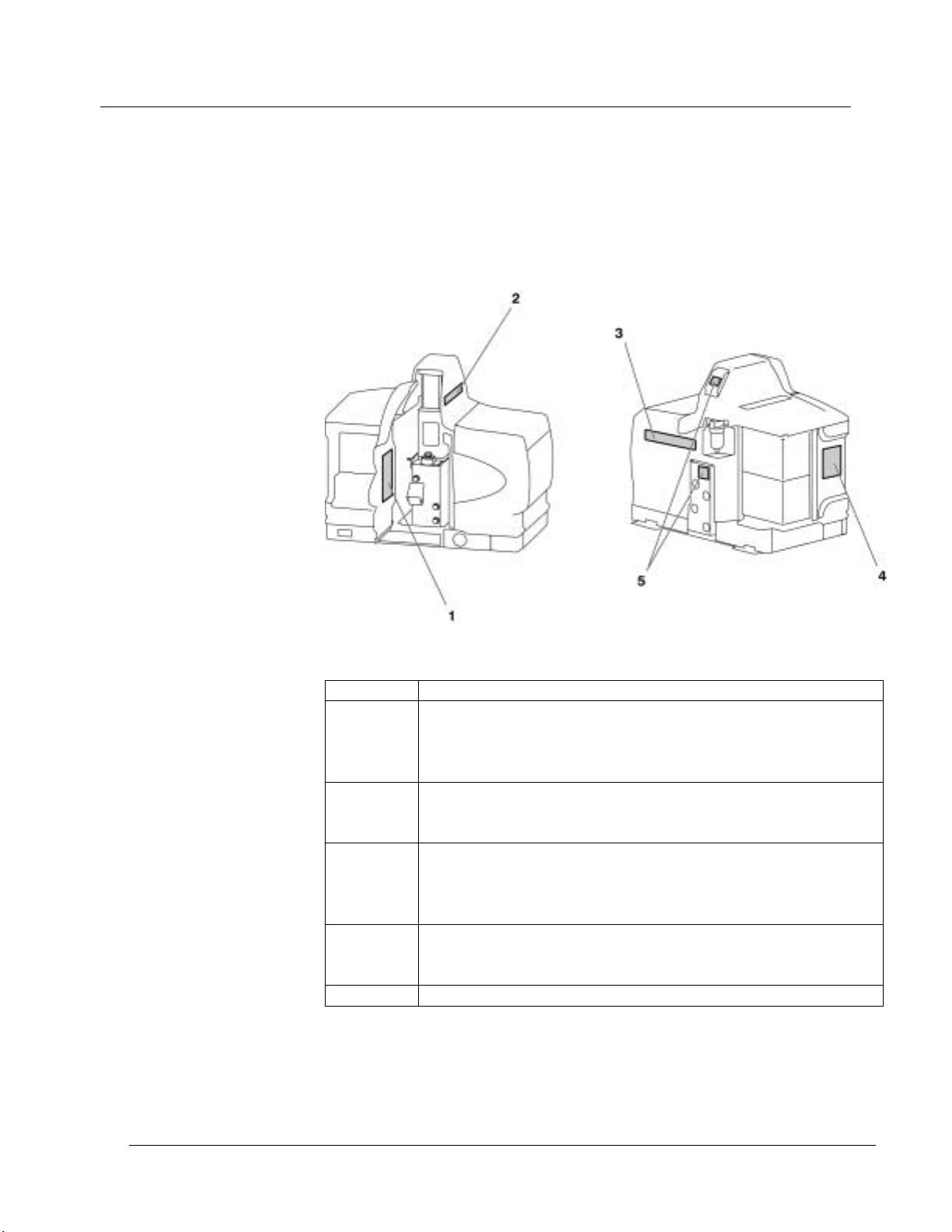
表1-1 一般安全警告(继续)
设备类型
设备类型设备类型
设备类型
警告
警告警告
警告
HM, PC
警告:设备自动开机!远程触发装置用于控制自动热熔胶喷枪。在喷枪
上或者其附近开始工作前,关闭喷枪触发装置,切断至喷枪电磁阀的空
气供应。如果没有关闭喷枪触发装置或者没有切断到喷枪电磁阀的空气
供应,可能会导致人身伤害。
HM, CA, PC
警告:有触电死亡的危险!即使设备已经关闭,断路开关或者电路断路
器已经断开,设备仍旧可能连接在活跃的辅助装置上。在维护设备前,
要断电,并且断开所有辅助设备电气连接。在维护设备前,如果没有正
确切断辅助设备的电源,可导致人身伤害,包括死亡。
CA
警告:着火或爆炸的危险!诺信公司的冷胶设备不适合在易爆炸的环境
中使用,不应当使用易产生爆炸的溶剂型黏合剂。参考粘合剂的
MSDS,以确定其处理特点和限制。使用不兼容的溶剂型黏合剂或处理
不当,可导致人身伤害,包括死亡。
HM, CA, PC
警告:只允许受过适当培训和有经验的人员操作或者维护设备。没有培
训过或者没有经验的人员操作或维护设备,可导致对其本身和他人的人
身伤害,包括死亡,还可能损坏设备。
延续
..



剩余131页未读,继续阅读
2020-04-05 上传
点击了解资源详情
2023-10-21 上传
2023-07-18 上传
2013-07-12 上传
2017-03-02 上传
2023-07-18 上传

快码加编2023
- 粉丝: 4
- 资源: 44
 我的内容管理
展开
我的内容管理
展开







最新资源
- MD5加密文档,包括原理及代码
- Rampant.TechPress.Oracle.SQL.Internals.Handbook
- ext中文手册整理版
- 电子商务大赛资料2-试题下面有
- java2实用教程(第3版例子代码).doc
- mapinfo开发的三种方法
- 技术资料下载\嵌入式软件编程的论文30篇\ERA2000成像测井地面仪器硬件的设计与实现.pdf
- Advanced_Python_programming
- Struts常见错误汇总.txt
- 酒店管理系统可行性分析
- VHDL基础教程学习
- max232 pdf
- emule 源码分析
- 基于J2EE的Ajax宝典
- eclipse中文使用文档
- 浅谈Java的输入输出流.pdf
