Hadoop MapReduce:并行处理基因组数据与大规模模拟任务
需积分: 10 173 浏览量
更新于2024-07-19
收藏 11.64MB PDF 举报
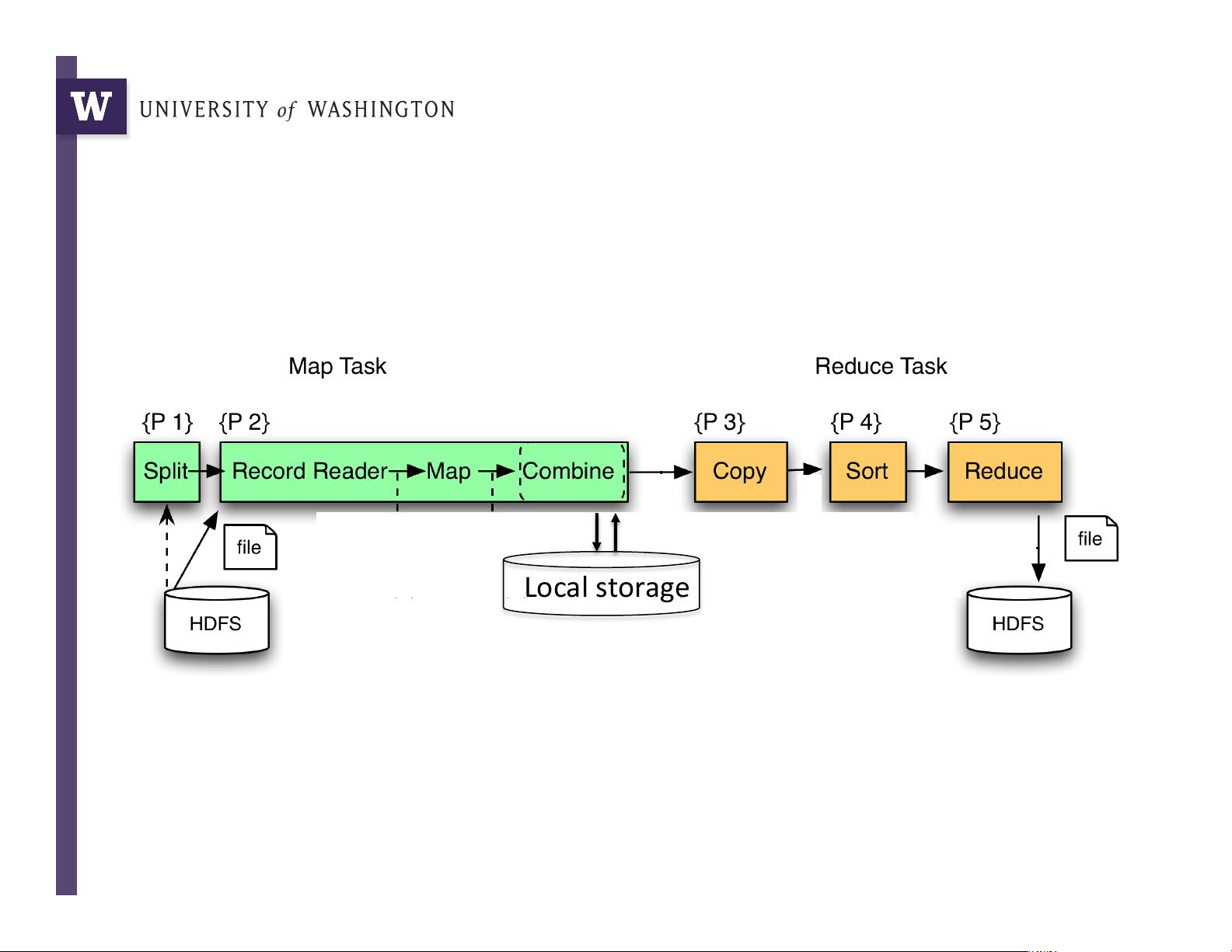
大数据--Hadoop MapReduce 是一种分布式计算框架,它在处理大规模数据集时尤其高效,特别是对于那些难以单机处理的任务。MapReduce 的核心思想是将复杂的问题分解成一系列简单的小任务,通过并行执行这些任务来提高计算效率。该框架由两个主要阶段组成:Map 和 Reduce。
1. Map阶段:
- 在给定的示例中,MapReduce被用于基因组数据处理,如短读序列(约35-75字符)的预处理。在这个阶段,将大量的短读序列分布到多台计算机上,每个计算机负责执行一个函数,即“read trimming”,即修剪掉序列中的低质量部分。这个过程实现了数据的分布式处理,使得每个节点可以独立地对数据进行初步处理,减少了整体处理时间。
2. Reduce阶段:
- 对于TIFF图像转为PNG,也是一个类似的例子。图像数据被分发到多个计算机,然后各自转换格式,并将结果汇总。这一步骤确保了图像处理的并行化,大大提升了图像转换的速度。
3. 参数模拟任务:
- 参数优化或模拟场景中,MapReduce同样发挥作用。成千上万的参数集被分散到不同的计算机上,每个节点运行特定的模拟,生成结果后再汇总。这有助于在大量实验中寻找最优参数组合,提高了模型训练的效率。
4. 文档分析:
- 最后,处理海量文档时,MapReduce用于分布式搜索,将文档分布在多台机器上,然后找出最频繁出现的关键词或者模式,用于文本挖掘、信息检索等应用场景。
MapReduce的设计使得数据处理可以利用多台计算机的并行能力,有效地处理海量数据,降低了处理时间和存储需求。这种架构适用于许多大数据场景,如基因组学、图像处理、科学仿真和信息检索,其优势在于通过简单接口提供了一种易于理解的方式来处理复杂的数据处理任务。同时,Hadoop MapReduce作为Apache Hadoop生态系统的核心组件,为大数据分析提供了强大的工具支持。
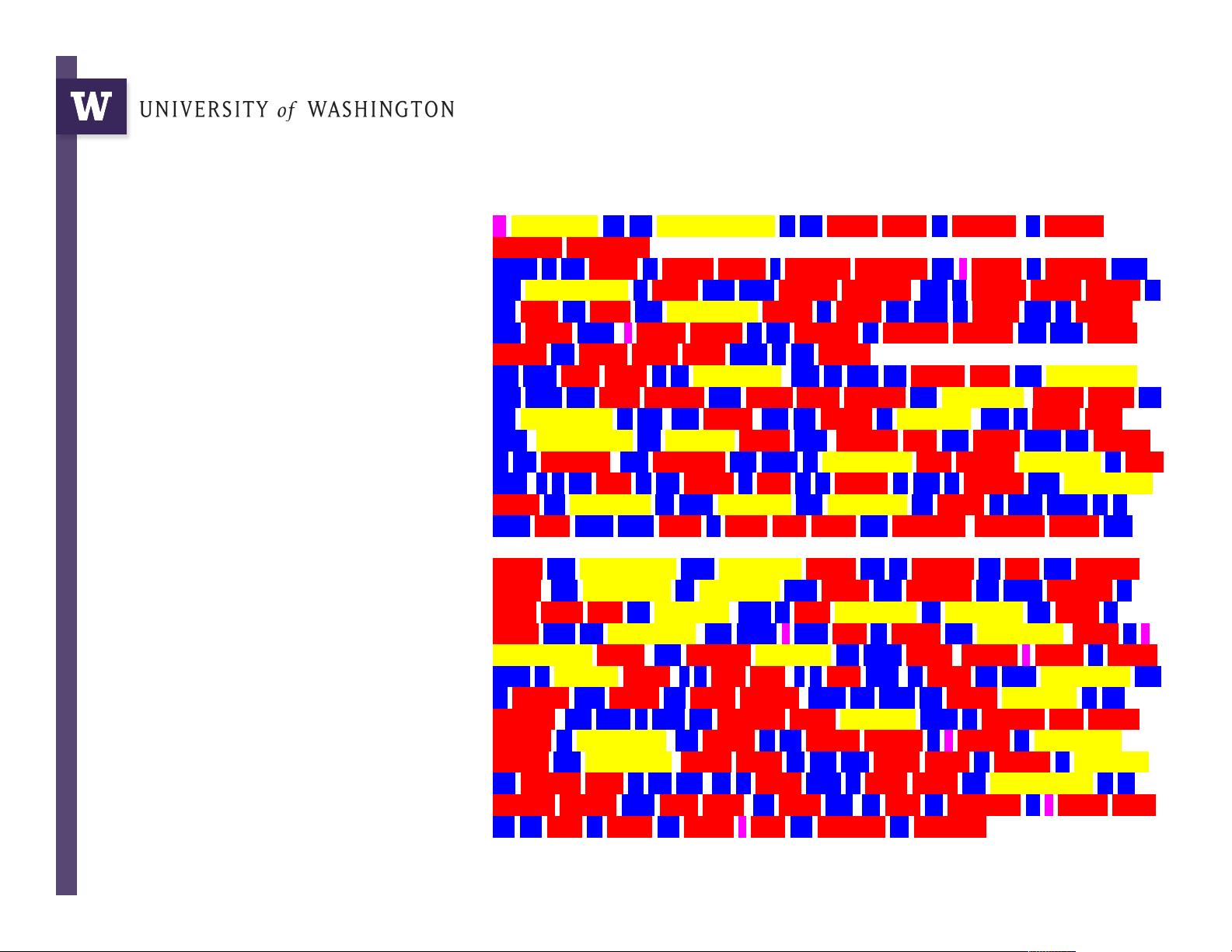
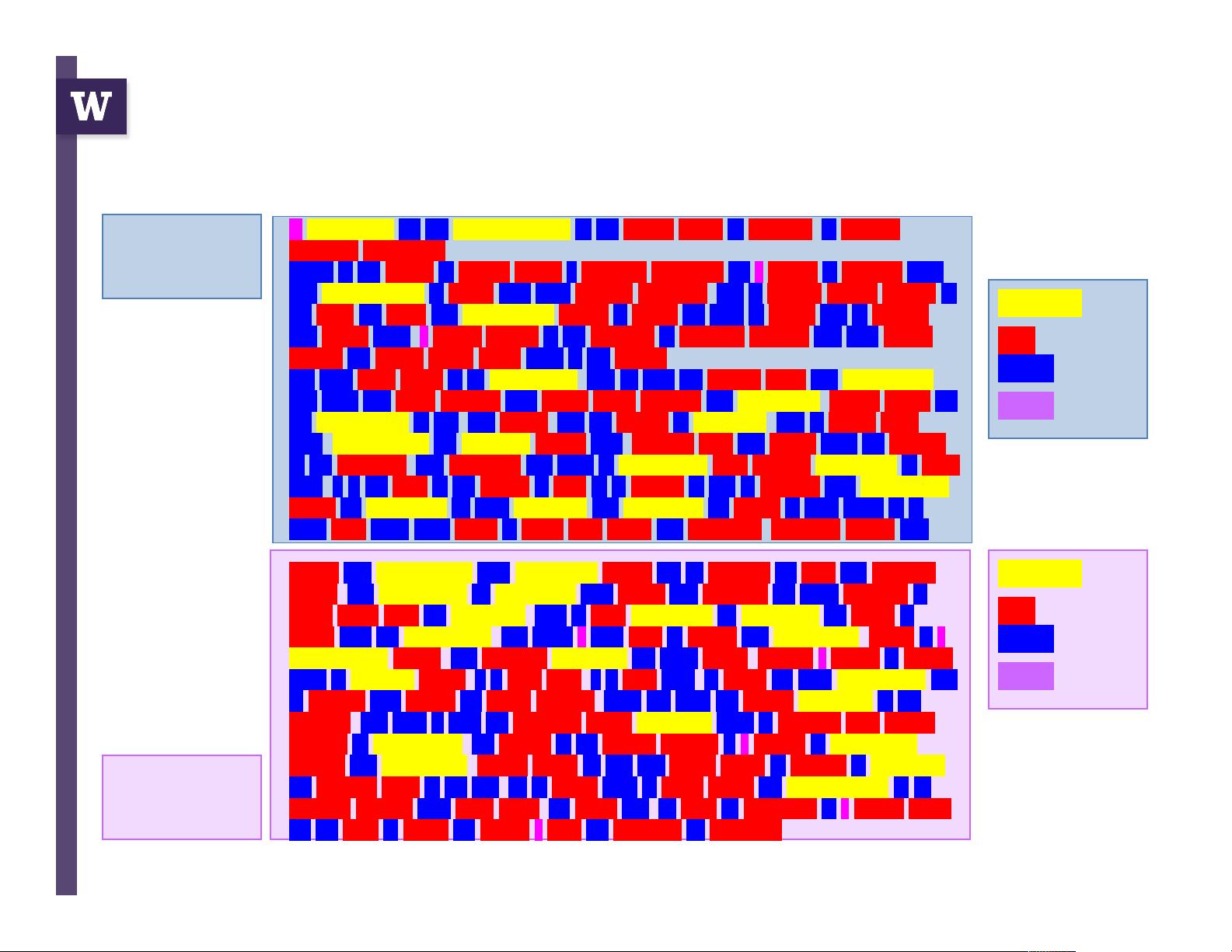
Abridged Declaration of Independence
A Declaration By the Representatives of the United States of America, in General
Congress Assembled.
When in the course of human events it becomes necessary for a people to advance from
that subordination in which they have hitherto remained, and to assume among powers of
the earth the equal and independent station to which the laws of nature and of nature's
god entitle them, a decent respect to the opinions of mankind requires that they should
declare the causes which impel them to the change.
We hold these truths to be self-evident; that all men are created equal and independent;
that from that equal creation they derive rights inherent and inalienable, among which are
the preservation of life, and liberty, and the pursuit of happiness; that to secure these
ends, governments are instituted among men, deriving their just power from the consent
of the governed; that whenever any form of government shall become destructive of these
ends, it is the right of the people to alter or to abolish it, and to institute new government,
laying it's foundation on such principles and organizing it's power in such form, as to
them shall seem most likely to effect their safety and happiness. Prudence indeed will
dictate that governments long established should not be changed for light and transient
causes: and accordingly all experience hath shewn that mankind are more disposed to
suffer while evils are sufferable, than to right themselves by abolishing the forms to
which they are accustomed. But when a long train of abuses and usurpations, begun at a
distinguished period, and pursuing invariably the same object, evinces a design to reduce
them to arbitrary power, it is their right, it is their duty, to throw off such government and
to provide new guards for future security. Such has been the patient sufferings of the
colonies; and such is now the necessity which constrains them to expunge their former
systems of government. the history of his present majesty is a history of unremitting
injuries and usurpations, among which no one fact stands single or solitary to contradict
the uniform tenor of the rest, all of which have in direct object the establishment of an
absolute tyranny over these states. To prove this, let facts be submitted to a candid world,
for the truth of which we pledge a faith yet unsullied by falsehood.
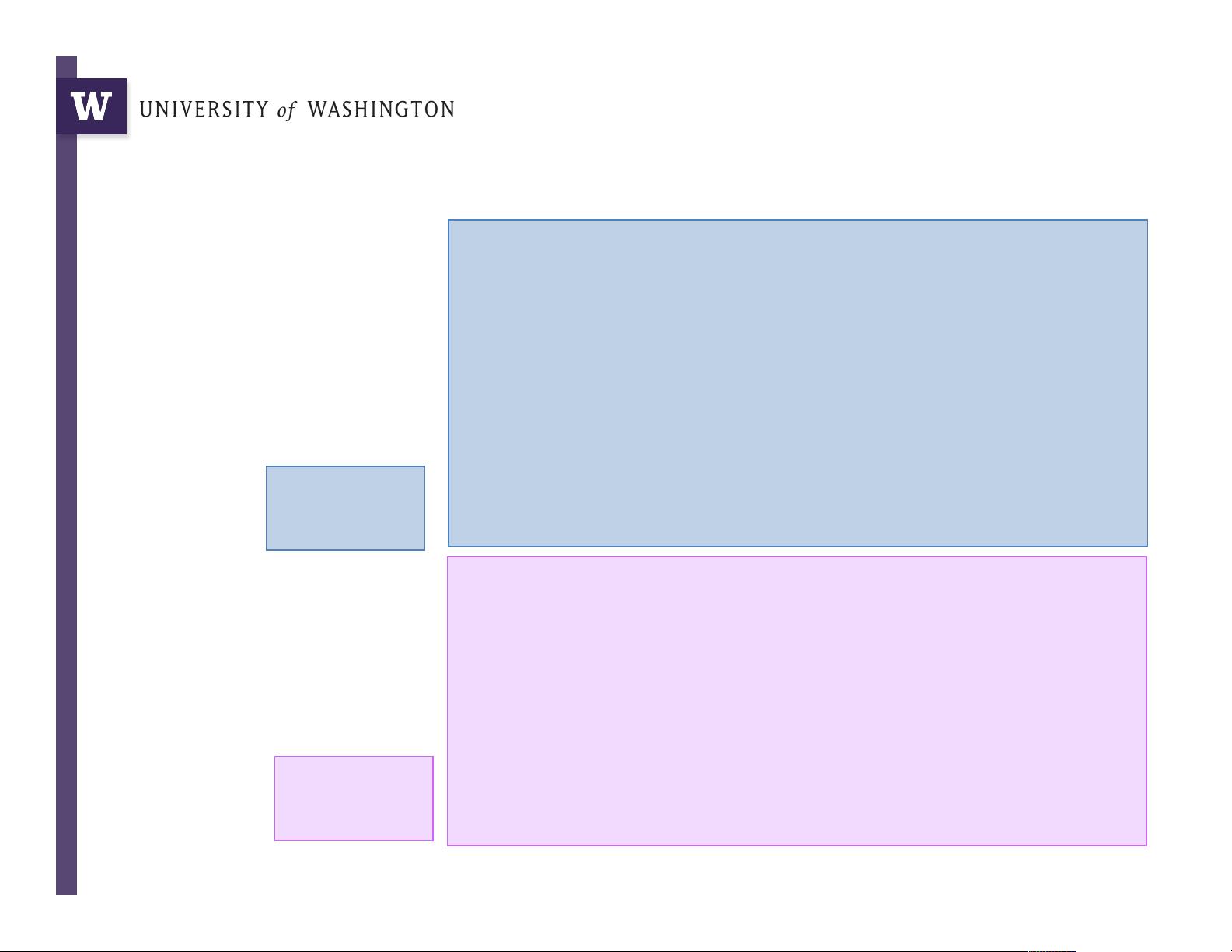
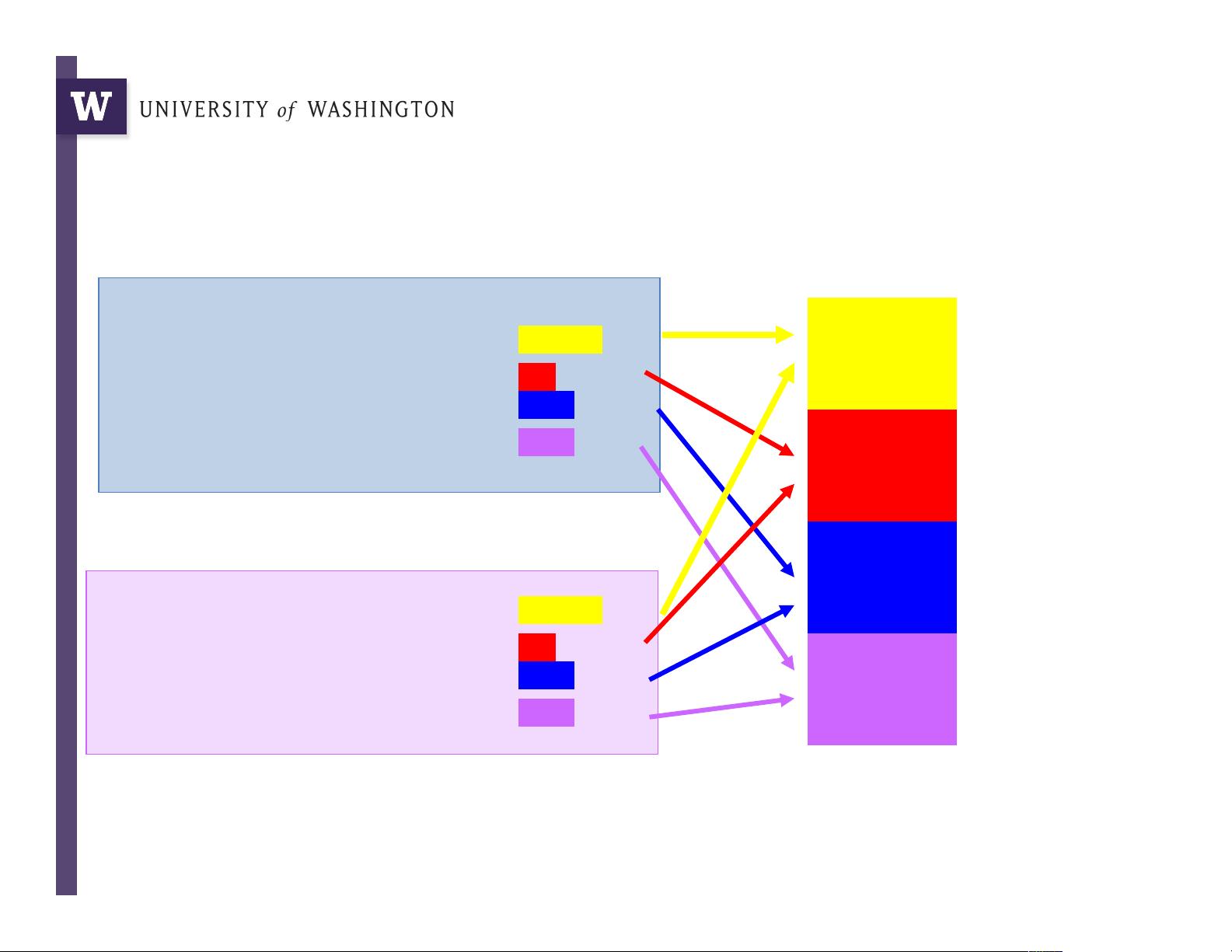
Big = Yellow = 10+ letters
Medium = Red = 5..9 letters
Small = Blue = 2..4 letters
Tiny = Pink = 1 letter
Example: Word length
histogram
剩余122页未读,继续阅读
2018-11-28 上传
2020-03-23 上传
2015-10-21 上传
2021-06-06 上传
2023-06-28 上传

m0_37635196
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- spring-data-orientdb:SpringData的OrientDB实现
- 施耐德PLC通讯样例.zip昆仑通态触摸屏案例编程源码资料下载
- Sort-Text-by-length-and-alphabetically:EKU的CSC 499作业1
- Resume
- amazon-corretto-crypto-provider:Amazon Corretto加密提供程序是通过标准JCAJCE接口公开的高性能加密实现的集合
- array-buffer-concat:连接数组缓冲区
- api-annotations
- 行业数据-20年春节期间(20年1月份24日-2月份9日)中国消费者线上购买生鲜食材平均每单价格调查.rar
- ex8Loops1
- react-travellers-trollies
- Bootcamp:2021年的训练营
- SpookyHashingAtADistance:纳米服务革命的突破口
- 蛇怪队
- address-semantic-search:基于TF-IDF余弦相似度的地址语义搜索解析匹配服务
- 摩尔斯键盘-项目开发
- Terraria_Macrocosm:空间
