CUDA加速图像缩放技术:MATLAB实现与优化
需积分: 13 146 浏览量
更新于2024-07-15
收藏 10.52MB PPTX 举报
"CUDA图像缩放展示.pptx"
这篇报告主要探讨了使用CUDA并行加速技术在图像缩放中的应用。报告由戚林通在中科大的一门谭立湘教授的课程中完成,并且提供了在MATLAB平台上实现CUDA加速图像缩放的方案。如果你需要完整的源代码,可以通过私信联系作者。
**图像缩放算法简述**
图像缩放的基本任务是根据原始图像的像素值,通过特定规则计算出目标图像的像素值。关键在于选择原图中的哪些像素并确定它们的权重。报告中提到了三种常见的处理方法:最近邻插值、双线性插值和双三次插值。本次演示选择了最简单的最近邻插值算法。在图像放大时,新位置的像素值由其最近的原始像素值决定。
**普通串行程序中的算法实现**
在串行程序中,最近邻插值算法通过for循环遍历目标图像的所有像素,计算其对应的源图像像素值。例如,目标图像的像素索引(i, j)对应源图像的像素索引(pX, pY)。如果处理的是1024x512的图像,并将其宽高放大两倍,循环次数会显著增加,导致计算速度变慢。
**利用CUDA进行优化**
CUDA优化的目标是提高图像缩放的速度。以下列出了几种优化策略:
1. **优化一:无需for循环,GPU上用线程处理像元** - 在GPU上,线程可以并行处理像素,避免了CPU上的for循环,极大地提高了效率。
2. **优化二:减少block个数,增加每个block中thread个数** - 减少CUDA的block数量,同时增加每个block中的线程数量,可以进一步提升并行效率。报告展示了不同block尺寸下的速度提升,例如Dim3block(32, 32)提高了约40.74倍,而Dim3block(16, 16)提高了约60.14倍。
3. **优化三:增加thread处理的数据量,grid、block降为一维** - 将grid和block维度降至一维,可以使得数据处理更高效,例如Dim3block(1024, 1)和Dim3grid(1024, 1)组合实现了约59倍的加速。
4. **优化四:使用纹理内存** - 利用CUDA的纹理内存可以提升读取像素的速度,因为它们被优化用于快速的二维访问模式,尤其适合图像处理。
**运行结果展示**
通过对不同block配置的测试,报告给出了具体的性能提升数据,表明通过CUDA优化,图像缩放的速度得到了显著提升,特别是在调整block大小和利用纹理内存后,性能提升可达数十倍。
CUDA并行计算在图像处理,尤其是图像缩放中显示出了巨大的优势。通过优化算法设计和合理利用GPU的并行计算能力,可以显著加快处理速度,尤其对于处理大量或高分辨率图像的任务,这种加速效果尤为明显。
图像缩放算法简述
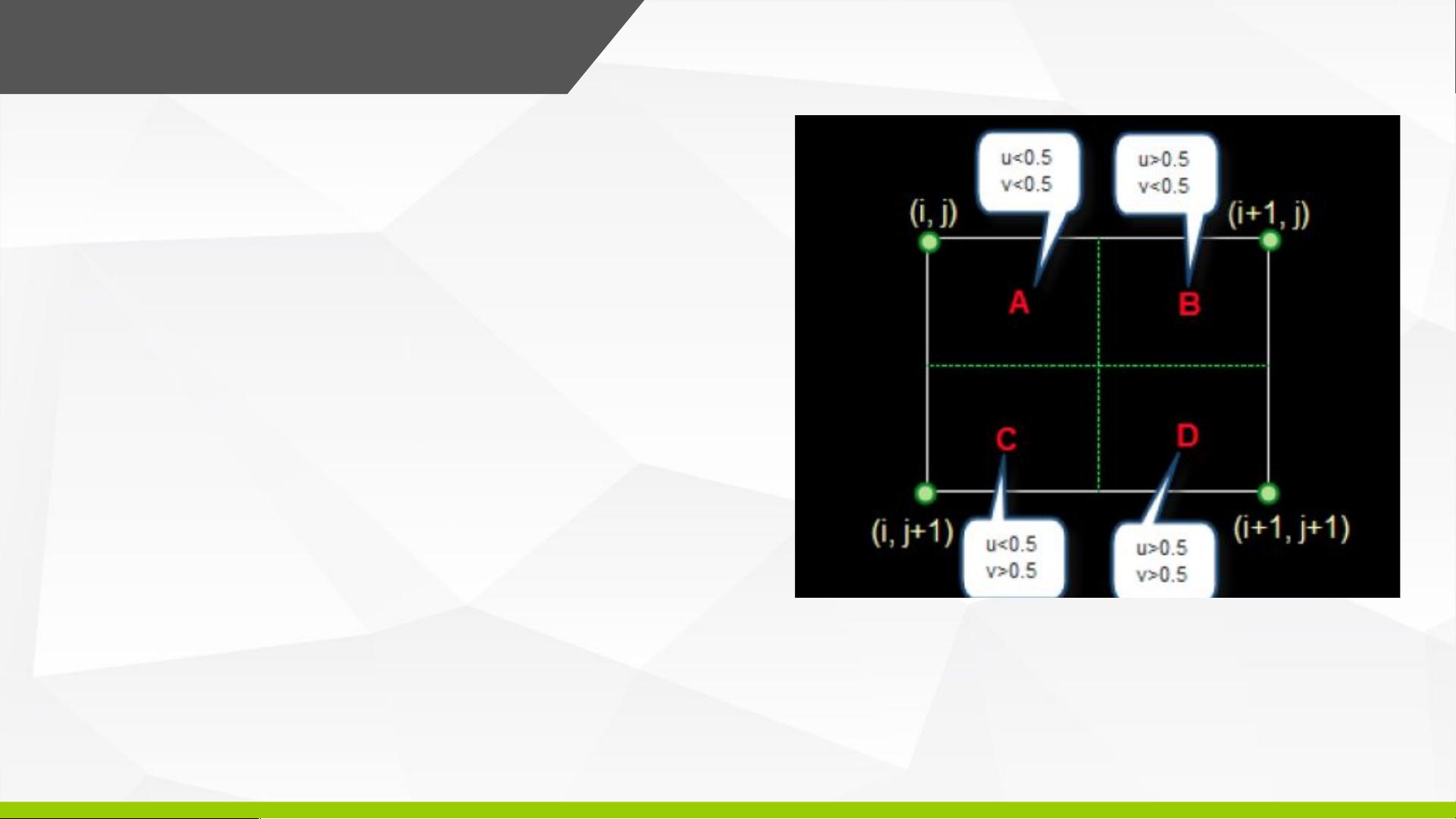
最近邻内插值算法概述:
这是最简单的一种插值算法,当图
片放大时,缺少的像素通过直接使用与之
最近原有颜色生成,在待求像素的四邻像
素中,将距离待求像素最近的邻灰度赋给
待求像素。
剩余21页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情

70tong
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







