支持向量机(SVM)入门详解
需积分: 42 87 浏览量
更新于2024-07-19
收藏 2.33MB PDF 举报
"支持向量机通俗导论(理解SVM的三层境界)"
支持向量机(SVM,Support Vector Machine)是一种强大的监督学习算法,尤其在分类和回归任务中表现出色。该算法由Vladimir Vapnik和他的同事们在20世纪90年代提出,基于统计学习理论,旨在通过最小化结构化风险来提高模型的泛化能力。
在第一层理解SVM时,我们需要了解其基本概念。SVM的核心在于分类,它寻找一个最优的超平面来将不同类别的数据分开。这个超平面是具有最大边际的,也就是说,它离最近的数据点(称为支持向量)最远。支持向量是决定超平面的关键,因为它们定义了分类边界。SVM的目标是找到一个能最大化这些边界距离的决策边界,这样可以降低对新数据错误分类的风险。
SVM属于监督学习,这意味着它需要已标记的训练数据来学习一个函数,该函数可以将输入映射到正确的输出类别。与传统的线性分类器相比,SVM能够处理非线性数据,通过使用核技巧(如高斯核或多项式核),它可以将数据映射到高维空间,在那里原本难以区分的数据可能变得线性可分。
在更深层次的理解中,SVM涉及到优化问题和软间隔的概念。优化问题旨在找到最佳超平面,这通常通过解决一个凸二次规划问题来实现。软间隔允许一部分训练数据被误分类,引入了惩罚项,使得模型在保持分类效果的同时,对噪声和异常值有一定的容忍度。
此外,SVM还可以用于回归任务,称为支持向量回归(SVR)。在这里,目标是找到一个函数,使预测值尽可能接近真实值,同样利用支持向量的概念来确定预测的边界。
在学习SVM时,理解和掌握数学基础,如最大间隔、拉格朗日乘子法、核函数以及凸优化,是非常关键的。为了更好地理解SVM,读者可以结合书中的公式和定理进行推导,并通过实践应用加深理解。同时,使用合适的工具,如Chrome浏览器,可以更方便地查看和理解涉及的数学表达式。
SVM是一种强大的机器学习工具,通过寻找最佳的决策边界和利用核方法处理非线性问题,能够在有限的样本下实现高效的学习。深入理解SVM的原理,包括其背后的数学基础和实际应用,对于任何数据科学从业者来说都是非常有价值的。
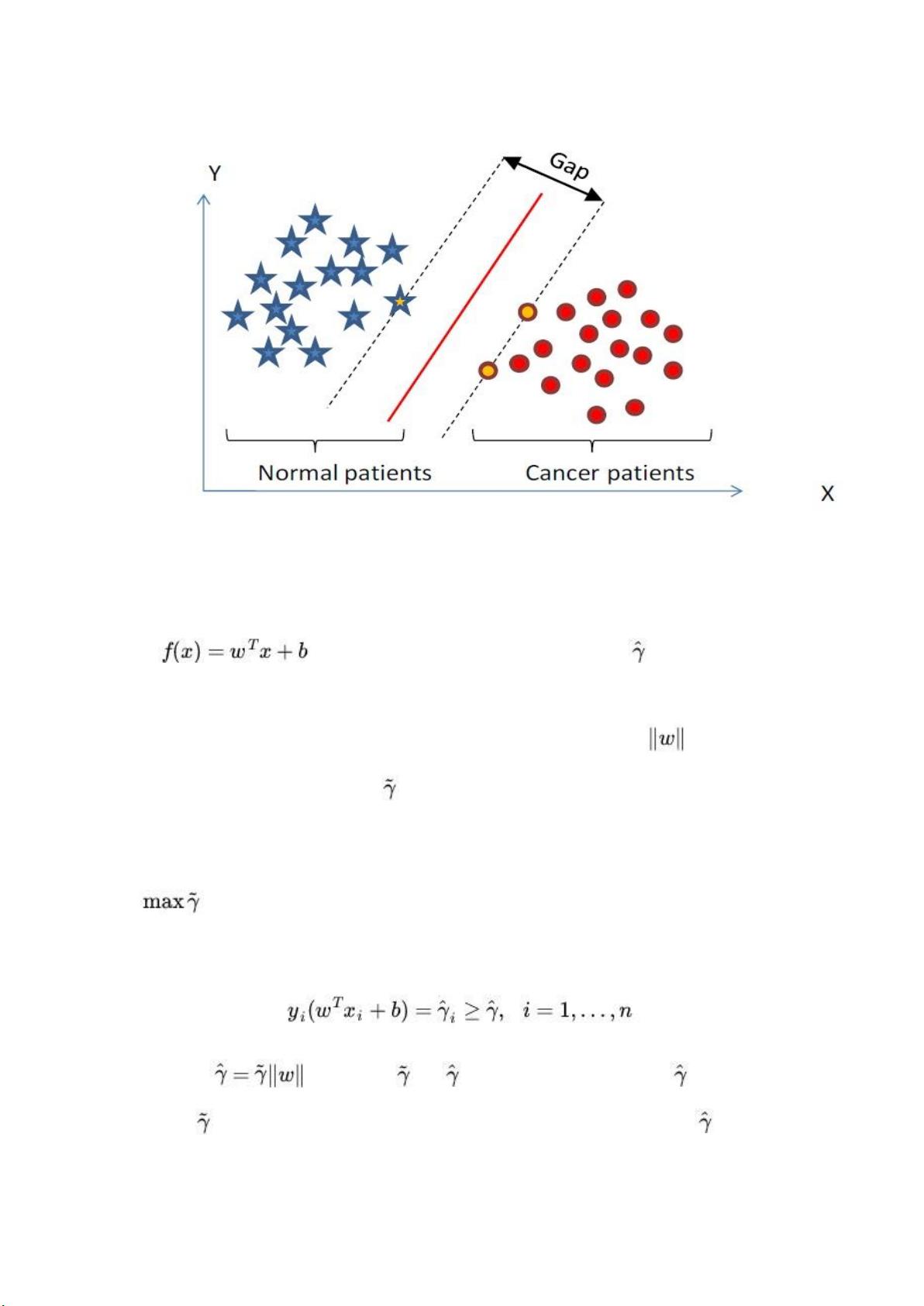
通过上节,我们已经知道:
1、functional margin 明显是不太适合用来最大化的一个量,因为在 hyper
plane 固定以后,我们可以等比例地缩放 w 的长度和 b 的值,这样可以使
得 的值任意大,亦即 functional margin 可以在 hyper
plane 保持不变的情况下被取得任意大,
2、而 geometrical margin 则没有这个问题,因为除上了 这个分母,
所以缩放 w 和 b 的时候 的值是不会改变的,它只随着 hyper plane 的
变动而变动,因此,这是更加合适的一个 margin 。
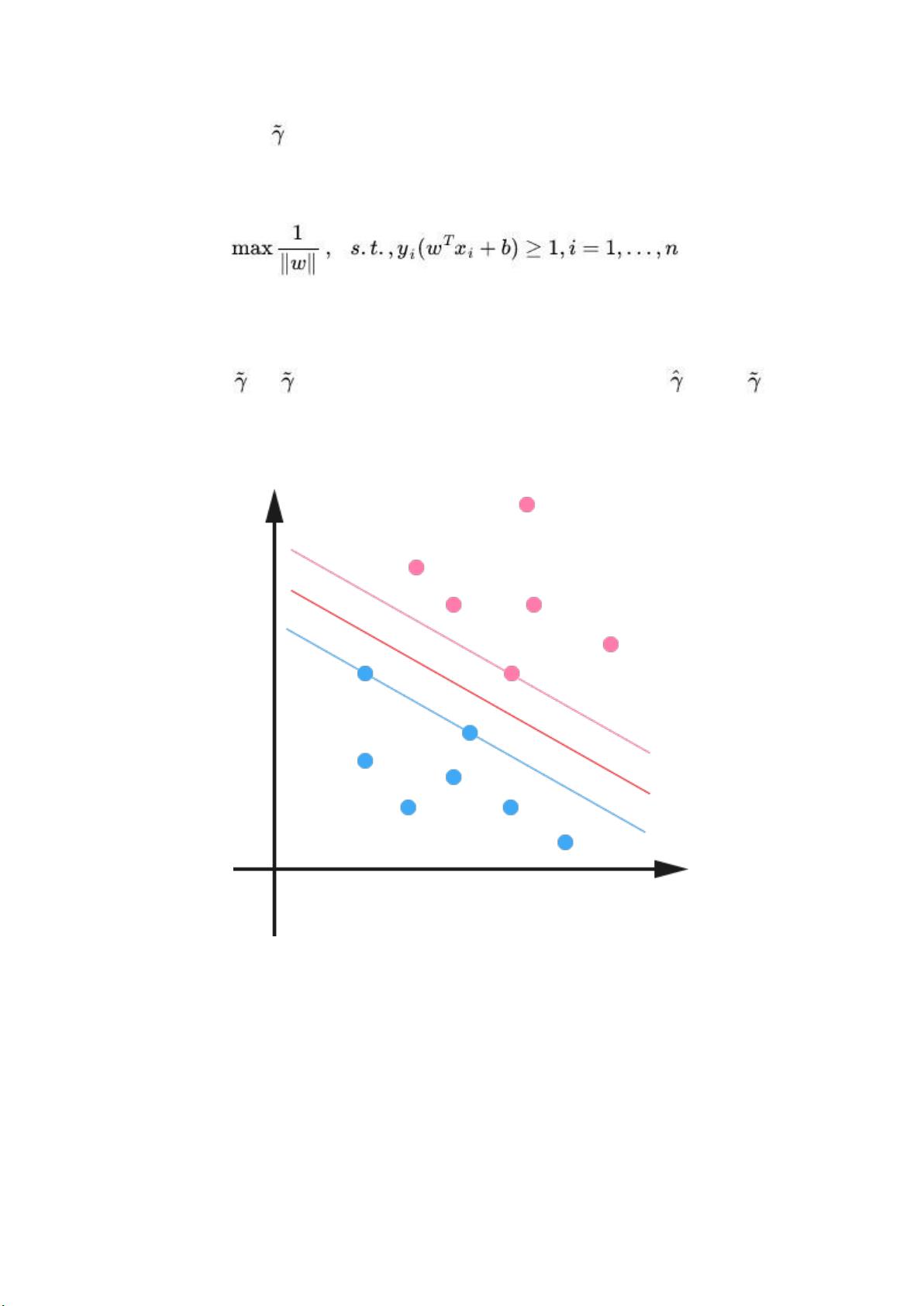
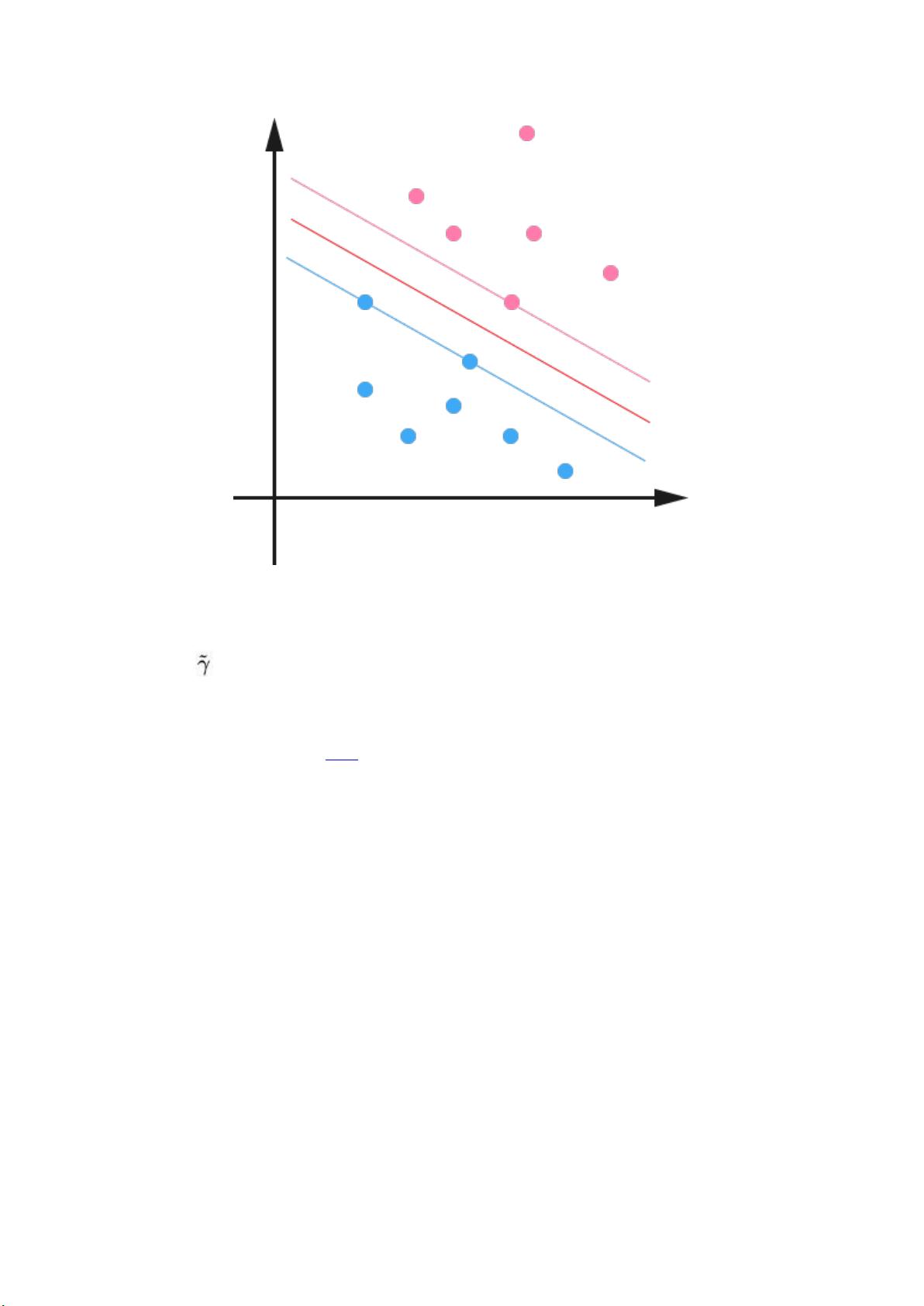
这样一来,我们的 maximum margin classifier 的目标函数可以定义为:
当然,还需要满足一些条件,根据 margin 的定义,我们有
其中 (等价于 = /||w||,故有稍后的 =1
时, = 1 / ||w||),处于方便推导和优化的目的,我们可以令 =1(对目
标函数的优化没有影响,至于为什么,请见本文评论下第 42 楼回复) ,此时,
剩余61页未读,继续阅读
2018-10-12 上传
2021-10-02 上传
2022-07-14 上传

mylovers_3000codes
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
