精通Apache Spark高级分析
需积分: 8 84 浏览量
更新于2024-07-18
收藏 10.35MB PDF 举报
"Mastering Advanced Analytics With Apache Spark"
Apache Spark 是一个强大的开源大数据处理框架,以其高效、易用和适用于大规模数据处理的特性而备受推崇。本资料“Mastering Advanced Analytics with Apache Spark”聚焦于Spark 1.4版本中的高级分析特性,旨在帮助用户深入理解Spark的各个组件以及它们在不同应用场景下的功能。
Spark的核心组件包括Spark Core、Spark SQL、Spark Streaming、MLlib(机器学习库)和GraphX(图计算库)。在Spark 1.4版本中,这些组件得到了进一步的优化和增强:
1. Spark Core:作为基础架构,Spark Core提供了分布式任务调度、内存管理、错误恢复和与存储系统的接口。1.4版可能包含了性能优化和新的API改进,以提升整体处理效率。
2. Spark SQL:这是Spark用于结构化数据处理的部分,允许用户使用SQL查询或DataFrame API操作数据。在1.4版中,它可能强化了对多种数据源的支持,提高了查询性能,并引入了更多的SQL兼容性。
3. Spark Streaming:该组件处理实时数据流,支持微批处理模型。1.4版可能增强了稳定性,提升了处理速率,并提供了更丰富的数据源连接选项。
4. MLlib:Spark的机器学习库包含多种算法,如分类、回归、聚类、协同过滤等。在1.4版中,可能更新了算法实现,提升了预测准确性和训练速度,同时增加了模型调优和评估工具。
5. GraphX:针对图数据处理,GraphX提供了高效的图操作和算法。在1.4版,它可能增强了图的创建、查询和分析能力,支持了更复杂的图算法。
此外,Databricks博客的亮点还可能涵盖了以下主题:
- 数据科学和数据分析的最佳实践,包括如何有效地利用Spark进行数据探索、清洗和预处理。
- 大规模机器学习工作流,包括数据准备、模型训练、验证和部署。
- 集群管理和资源调度优化,以提高Spark应用在分布式环境中的性能。
- 容器化和云集成,使Spark更容易在Docker或Kubernetes等平台上运行。
- 安全性与隐私保护,讨论了如何在Spark中实现数据加密和访问控制。
通过这份资料,读者不仅可以掌握Spark 1.4的关键改进,还能了解到来自业界专家的实际案例和经验分享,从而提升自己的大数据分析技能。无论是数据科学家、开发人员还是系统管理员,都能从中受益,将Apache Spark的强大功能应用于复杂的数据分析任务。
Scalable Collaborative Filtering
with Spark MLlib
July 23, 2014 | by Burak Yavuz, Xiangrui Meng and Reynold Xin
Recommendation systems are among the most popular applications of
machine learning. The idea is to predict whether a customer would like a
certain item: a product, a movie, or a song.Scale is a key concern for
recommendation systems, since computational complexity increases
with the size of a company’s customer base. In this blog post, we discuss
how Spark MLlib enables building recommendation models from billions
of records in just a few lines of Python (Scala/Java APIs also available).
What’s Happening under the Hood?
Recommendation algorithms are usually divided into:
(1) Content-based filtering: recommending items similar to what users
already like. An example would be to play a Megadeth song aer a
Metallica song.
(2) Collaborative filtering: recommending items based on what similar
users like, e.g., recommending video games aer someone purchased a
game console because other people who bought game consoles also
bought video games.
Spark MLlib implements a collaborative filtering algorithm called
Alternating Least Squares (ALS), which has been implemented in many
machine learning libraries and widely studied and used in both academia
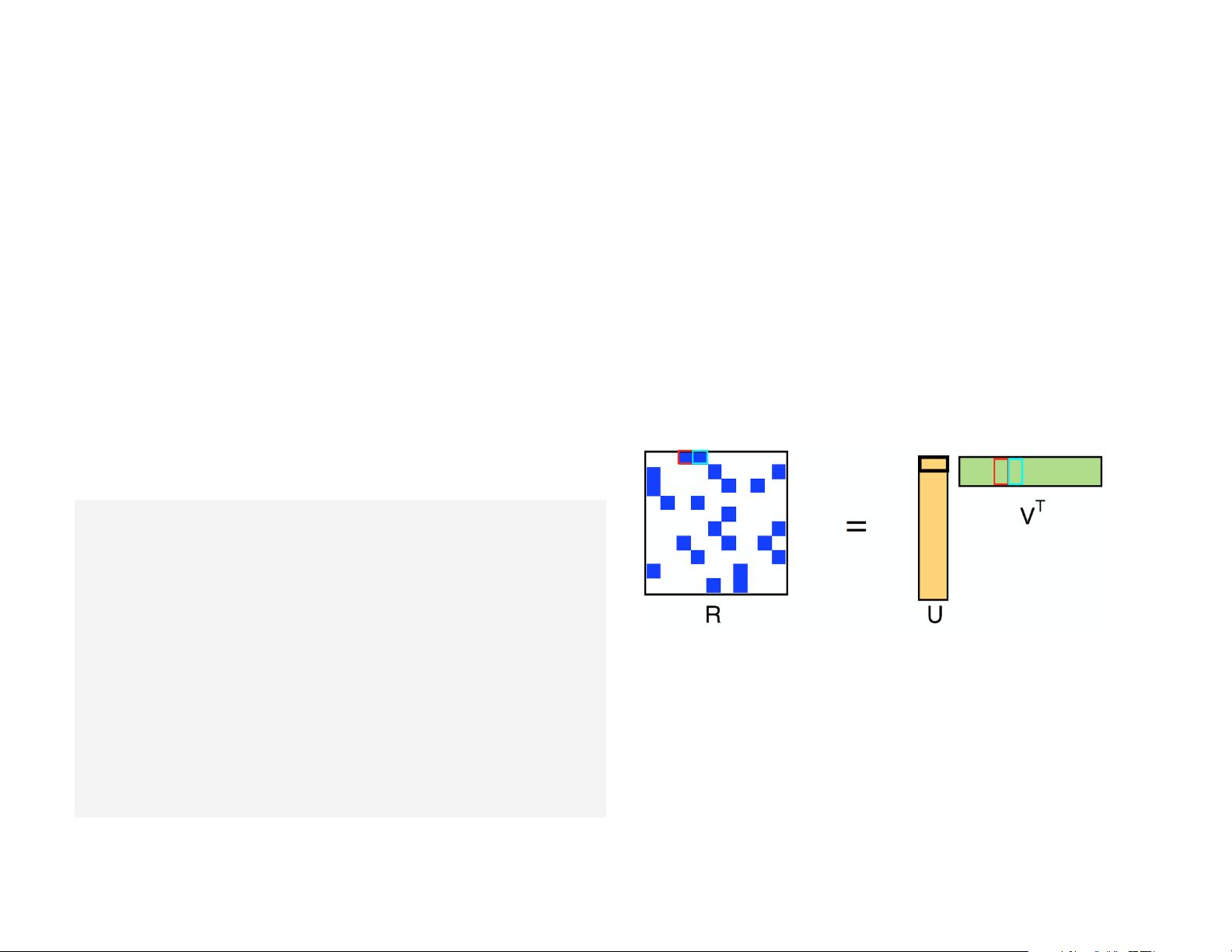
and industry. ALS models the rating matrix (R) as the multiplication of
low-rank user (U) and product (V) factors, and learns these factors by
minimizing the reconstruction error of the observed ratings. The
unknown ratings can subsequently be computed by multiplying these
Scalable Collaborative Filtering with Spark MLlib
13
from pyspark.mllib.recommendation import ALS
!
# load training and test data into (user, product, rating) tuples
def parseRating(line):
!!fields = line.split()
!!return (int(fields[0]), int(fields[1]), float(fields[2]))!!
training = sc.textFile("...").map(parseRating).cache()
test = sc.textFile("...").map(parseRating)
!
# train a recommendation model
model = ALS.train(training, rank = 10, iterations = 5)
!
# make predictions on (user, product) pairs from the test data
predictions = model.predictAll(test.map(lambda x: (x[0], x[1])))

剩余74页未读,继续阅读
2017-08-22 上传
2019-08-15 上传
2023-10-31 上传
2023-07-27 上传
2023-07-28 上传
2023-03-27 上传
2023-05-18 上传
2023-04-03 上传
2023-05-31 上传

zhaozhentao
- 粉丝: 1
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
