Python编程:朴素贝叶斯分类详解
42 浏览量
更新于2024-08-31
收藏 176KB PDF 举报
"本文主要探讨了Python编程中的朴素贝叶斯分类方法,涉及概率论的基础概念,特别是贝叶斯定理和条件概率,并简要解释了朴素贝叶斯的原理。"
朴素贝叶斯分类器是一种基于概率的分类模型,其核心理论源于统计学中的贝叶斯定理。贝叶斯定理描述了在给定一些证据或特征的情况下,对假设(或类别)的后验概率如何更新。在分类问题中,朴素贝叶斯方法假设特征之间相互独立,这被称为"朴素"假设,尽管在实际应用中这种假设往往过于简化,但在许多情况下仍能表现出良好的性能。
1. 贝叶斯定理
贝叶斯定理是概率论中的一个基本工具,用于计算事件A在已知另一个事件B发生时的概率。用公式表示为:
P(A|B) = P(B|A) * P(A) / P(B)
这里的P(A|B)是后验概率,即在B发生的条件下A发生的概率;P(B|A)是似然概率,即在A发生的条件下B发生的概率;P(A)是A的先验概率;P(B)是B的边缘概率。
2. 条件概率
条件概率是计算在已知某一事件发生的情况下,另一事件发生的概率。如上文所述,条件概率P(white|bucketB)表示在知道石头来自B桶的情况下,取出白色石头的概率。计算公式为:
P(A|B) = P(A and B) / P(B)
3. 朴素贝叶斯分类器原理
朴素贝叶斯分类器利用贝叶斯定理和特征之间的独立性假设进行分类。对于一个新的观测数据,分类器计算每个类别的后验概率,然后将其分配到具有最高后验概率的类别。这个过程涉及到计算每个特征在每个类别下的条件概率。
在实际的Python编程中,可以使用诸如`sklearn`库的`GaussianNB`、`MultinomialNB`或`BernoulliNB`等模型来实现朴素贝叶斯分类。这些模型分别对应于高斯分布、多项式分布和伯努利分布的朴素贝叶斯分类。
例如,使用`sklearn`库实现朴素贝叶斯分类的一段代码可能如下:
```python
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 假设X是特征矩阵,y是目标变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建并训练朴素贝叶斯分类器
gnb = GaussianNB()
gnb.fit(X_train, y_train)
# 预测
y_pred = gnb.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
```
朴素贝叶斯分类器在文本分类、垃圾邮件检测、情感分析等领域有广泛应用,因其高效且易于实现而受到欢迎。尽管其假设可能过于简单,但在某些情况下,它能够与更复杂的机器学习模型相媲美,甚至在某些数据集上表现更好。
Python编程之基于概率论的分类方法:朴素贝叶斯编程之基于概率论的分类方法:朴素贝叶斯
主要介绍了Python编程之基于概率论的分类方法:朴素贝叶斯,简单介绍了其概述,贝叶斯理论和条件概率,
以及朴素贝叶斯的原理等相关内容,具有一定参考价值,需要的朋友可以了解下。
概率论啊概率论,差不多忘完了。
基于概率论的分类方法:朴素贝叶斯
1. 概述概述
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本章首先介绍贝叶斯分类算法的
基础——贝叶斯定理。最后,我们通过实例来讨论贝叶斯分类的中最简单的一种: 朴素贝叶斯分类。
2. 贝叶斯理论贝叶斯理论 & 条件概率条件概率
2.1 贝叶斯理论贝叶斯理论
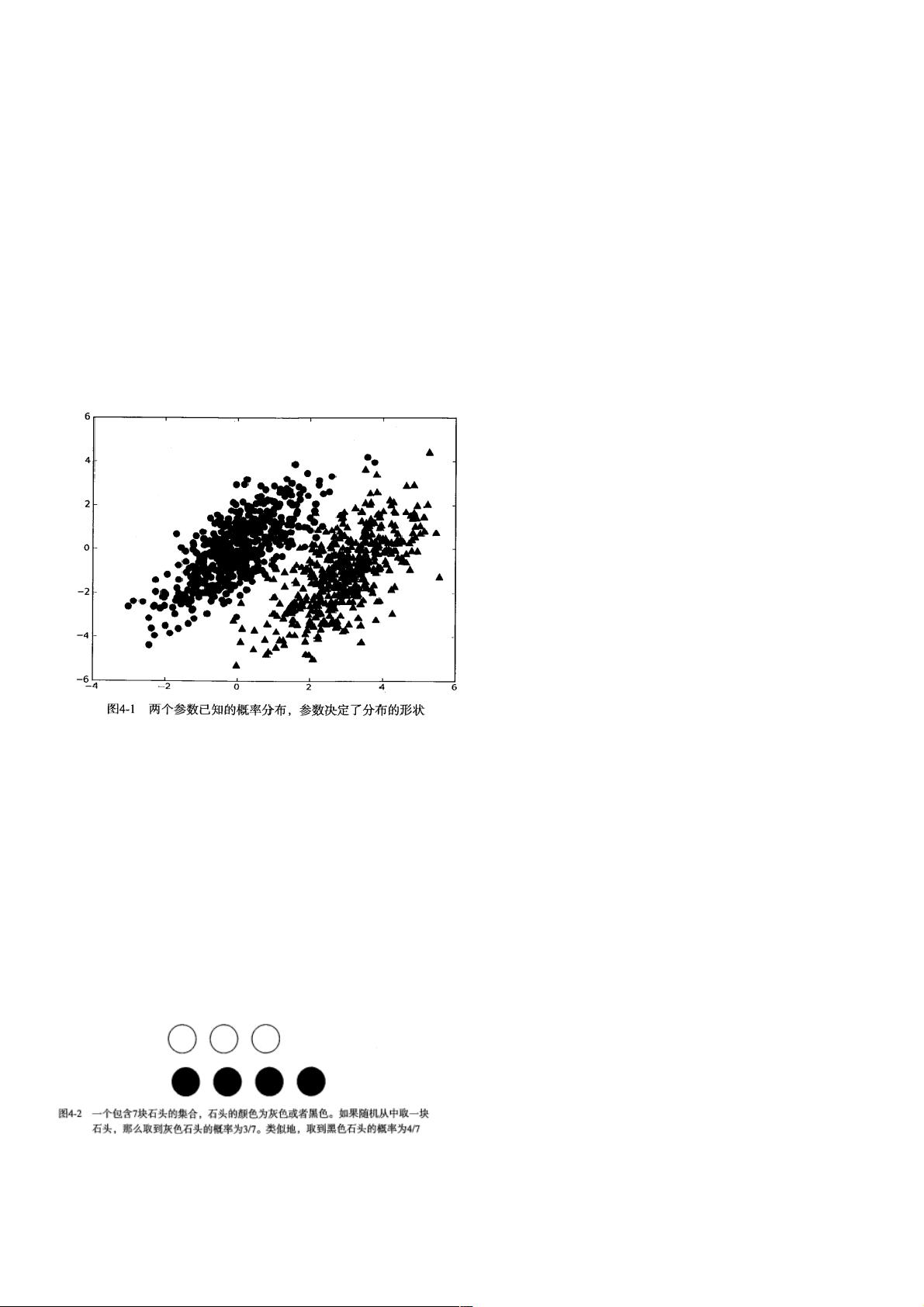
我们现在有一个数据集,它由两类数据组成,数据分布如下图所示:
我们现在用 p1(x,y) 表示数据点 (x,y) 属于类别 1(图中用圆点表示的类别)的概率,用 p2(x,y) 表示数据点 (x,y) 属于类别
2(图中三角形表示的类别)的概率,那么对于一个新数据点 (x,y),可以用下面的规则来判断它的类别:
如果 p1(x,y) > p2(x,y) ,那么类别为1
如果 p2(x,y) > p1(x,y) ,那么类别为2
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
2.1.2 条件概率条件概率
如果你对 p(x,y|c1) 符号很熟悉,那么可以跳过本小节。
有一个装了 7 块石头的罐子,其中 3 块是白色的,4 块是黑色的。如果从罐子中随机取出一块石头,那么是白色石头的可能性
是多少?由于取石头有 7 种可能,其中 3 种为白色,所以取出白色石头的概率为 3/7 。那么取到黑色石头的概率又是多少
呢?很显然,是 4/7 。我们使用 P(white) 来表示取到白色石头的概率,其概率值可以通过白色石头数目除以总的石头数目来
得到。
如果这 7 块石头如下图所示,放在两个桶中,那么上述概率应该如何计算?
下载后可阅读完整内容,剩余4页未读,立即下载
2012-12-20 上传
2022-08-04 上传
2023-03-01 上传
2023-09-23 上传
2023-09-05 上传
2023-03-28 上传
2023-05-20 上传
2023-04-30 上传
2023-11-16 上传

weixin_38557980
- 粉丝: 7
- 资源: 925
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++标准程序库:权威指南
- Java解惑:奇数判断误区与改进方法
- C++编程必读:20种设计模式详解与实战
- LM3S8962微控制器数据手册
- 51单片机C语言实战教程:从入门到精通
- Spring3.0权威指南:JavaEE6实战
- Win32多线程程序设计详解
- Lucene2.9.1开发全攻略:从环境配置到索引创建
- 内存虚拟硬盘技术:提升电脑速度的秘密武器
- Java操作数据库:保存与显示图片到数据库及页面
- ISO14001:2004环境管理体系要求详解
- ShopExV4.8二次开发详解
- 企业形象与产品推广一站式网站建设技术方案揭秘
- Shopex二次开发:触发器与控制器重定向技术详解
- FPGA开发实战指南:创新设计与进阶技巧
- ShopExV4.8二次开发入门:解决升级问题与功能扩展
