HBase深度解析:分布式列式数据库实战
需积分: 10 171 浏览量
更新于2024-09-07
收藏 1.01MB DOCX 举报
"Hbase是Hadoop Database的简称,是一个分布式、面向列的开源数据库,它依赖于HDFS提供数据存储服务,并利用MapReduce进行高效计算。HBase支持三种运行模式:单机模式、伪分布式模式和分布式模式。系统内置Zookeeper以确保服务稳定性和故障转移。"
在深入探讨Hbase的相关知识点之前,首先需要理解Hbase的基本概念。Hbase是一个基于Google Bigtable设计思想的开源数据库,特别适合处理大规模数据。它主要设计用于非结构化数据的存储,尤其是在需要快速随机访问大量数据的场景下。
**Hbase的逻辑存储模型**
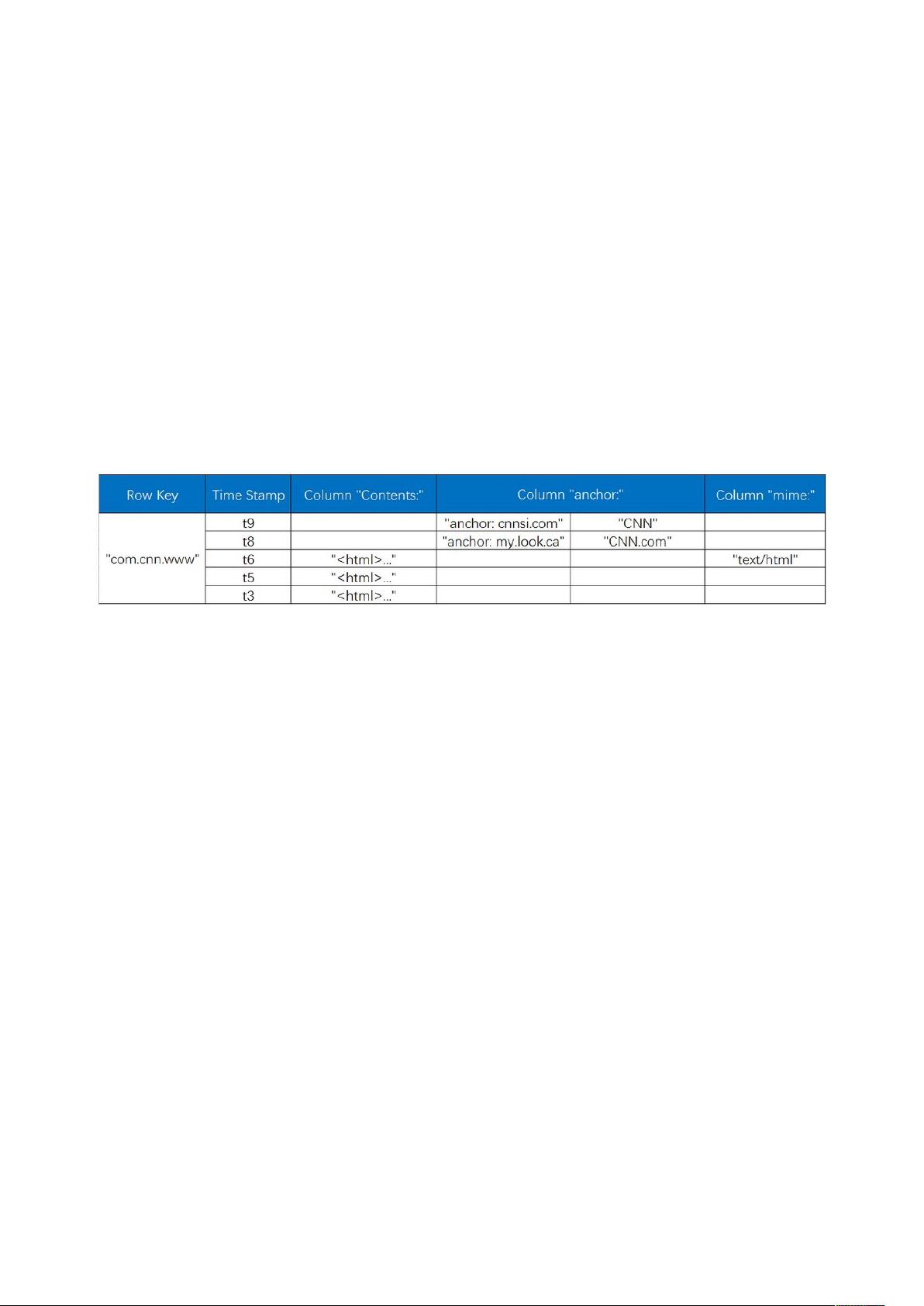
1. **RowKey(行键)**: 行键是Hbase中定位数据的主要方式,它是表中的唯一标识。通过指定的rowkey或rowkey的范围,可以快速查询数据。在插入数据时,rowkey会自动创建,并且在查询时起到关键作用。
2. **Timestamp(时间戳)**: 每个cell都有一个与之关联的时间戳,用于区分同一数据的不同版本。时间戳可以由系统自动分配(精确到毫秒的当前时间)或由用户自定义。Hbase提供了两种版本管理策略:保留最后n个版本或保留最近一段时间内的版本。
3. **Column Family(列族)**: 列族是Hbase的预定义Schema,所有的列都需要隶属于某个列族。列族管理权限、存储和内存使用。列族内的列可以动态添加,但列族本身必须在创建表时定义。
**Hbase的物理存储模型**
1. **HRegion**: 表在行方向上被分割成多个HRegion,每个HRegion由一个或多个RegionServer负责,这样可以实现数据的分布式存储。
2. **Store**: 每个HRegion由多个Store组成,每个Store对应一个列族。Store包含一个MemStore(内存组件)和零个或多个StoreFile(磁盘文件)。
3. **StoreFile(HFile)**: StoreFile是以HFile格式存储在HDFS上的数据文件,是Hbase持久化数据的基本单元。
**Hbase的架构组件**
1. **HDFS**: Hbase的数据存储在Hadoop的HDFS上,保证了数据的可靠性和容错性。
2. **MapReduce**: MapReduce为Hbase提供批量处理和计算能力,尤其适用于大数据量的分析任务。
3. **Zookeeper**: Zookeeper在Hbase中用于协调各个组件,确保服务的高可用性,例如在RegionServer故障时进行故障转移。
**Hbase的操作模式**
1. **单机模式**: 在本地机器上运行,不涉及分布式特性,主要用于开发和测试。
2. **伪分布式模式**: 在单台机器上模拟分布式环境,所有Hbase和Hadoop组件都在同一个JVM中运行。
3. **分布式模式**: 正式生产环境下的运行模式,所有组件分布在多台机器上,能够处理大规模数据并提供高可用性。
理解这些核心概念后,开发者可以有效地设计和管理Hbase表,优化查询性能,以及利用Hbase的分布式特性和列式存储优势来处理大规模数据问题。在实际应用中,Hbase常用于实时数据分析、日志存储、物联网(IoT)数据处理等领域。
Hbase(Reference 二)
1. 这是个什么玩意
Hbase 是 Hadoop Database 的简称
Hbase 是分布式、面向列的开源数据库
HDFS 为 Hbase 提供可靠的底层数据存储服务,MapReduce 为 Hbase 提供高性能的计算能力
HBase 运行模式:单机模式、伪分布式模式、分布式模式
Hbase 自带 Zookeeper,zk 为其提供稳定服务和故障转移机制。也可以使用独立的 zk
2. 主要原理介绍
1. 逻辑存储模型
RowKey:通过某个 rowkey 或某范围的 rowkey 查询数据的主键,插入数据时自动创建。
TimeStamp:HBase 中通过 row 和 columns 确定的为一个存储单元称为 cell。每个 cell 都保
存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64 位整型。时间戳可以由
HBase 在写入时自动赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显示赋值。
如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell 中在不同版本的
数据按照时间倒序排序,即最新的数据排在最前面。为了避免数据存在过多的版本造成的管理负担,
HBase 提供了两种数据版本回收方式。一是保存数据的最后 n 个版本,二是保存最近一段时间内的版
本比如最近七天)。用户可以针对每个列簇进行设置。
列族:HBase 表中的每个列,都归属于某个列族,列族是表的 schema 的一部分(而列不是),
必须在使用表之前定义。列名都以列族作为前缀。例如:courses:history, courses:math 都属于
courses 这个列族。访问控制,磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上
的控制权限能帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数据、一些应用可
以读取基本数据并创建继承的列族、一些应用则只允许浏览数据(设置可能因为隐私的原因不能浏览
所有数据)。
2. 物理存储模型
Table 在行的方向上分割为多个 HRegion,每个 HRegion 分散在不同的 RegionServer 中
下载后可阅读完整内容,剩余8页未读,立即下载
2018-09-03 上传
2023-09-10 上传
2023-06-07 上传
2023-05-19 上传
2024-10-15 上传
2023-06-11 上传
2023-06-07 上传
2023-04-27 上传

yoyoshaoye
- 粉丝: 99
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
