大规模信息检索系统构建中的挑战与语言建模
需积分: 9 97 浏览量
更新于2024-07-18
收藏 2.06MB PDF 举报
"这篇笔记探讨了构建大规模信息检索系统时所面临的挑战,由Google的Jeff Dean撰写。主要涉及了N-gram、语言建模以及它们在搜索技术中的应用,如机器翻译、拼写纠正、语音识别等。"
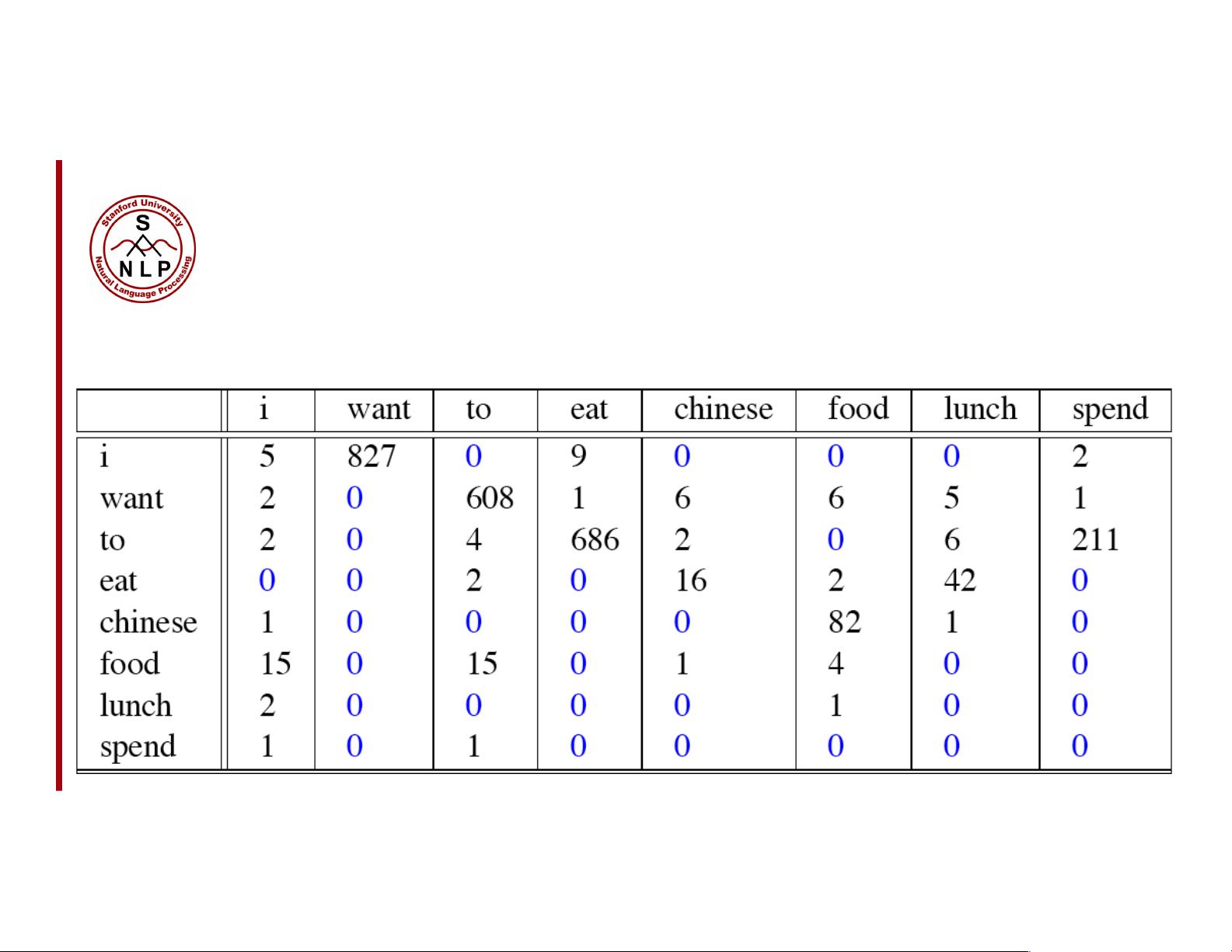
在构建大规模信息检索系统的过程中,N-gram是一个重要的概念。N-gram是自然语言处理中的一种统计方法,用于预测文本序列中的下一个词或字符。基本思想是将连续的n个词(或字符)视为一个单元,通过分析这些单元在语料库中出现的频率来预测后续的词。例如,二元模型(bigram)会考虑当前词与前一个词的组合,而三元模型(trigram)则考虑当前词及其前两个词的组合。这种技术在搜索引擎的查询建议、文本生成、语音识别等领域都有广泛应用。
语言建模则是计算一个句子或单词序列概率的过程。它在现代信息检索系统中扮演着核心角色,因为理解语言的概率分布可以帮助系统更好地理解和生成自然语言。Dan Jurafsky提出的概率语言模型旨在为一个句子或一系列单词赋予权重,即计算P(W) = P(w1, w2, w3, w4, w5…wn)。此外,还有一种相关任务是预测给定前缀情况下下一个词的概率,即P(w5|w1, w2, w3, w4)。能够计算这两个概率之一的模型就被称为语言模型。
一个良好的语言模型能够捕捉到语言的语法和语义规则,这对于提高信息检索的准确性和效率至关重要。例如,在机器翻译中,语言模型可以帮助选择更符合目标语言习惯的翻译;在拼写纠正中,它可以根据上下文概率判断错误拼写的可能性;而在语音识别中,它可以降低识别错误率,使系统更准确地理解用户的语音输入。
构建大规模信息检索系统时,除了N-gram和语言模型,还需要解决其他挑战,如数据的高效存储和索引,处理海量数据的能力,实时性需求,以及应对用户多样化和复杂的查询需求。Jeff Dean作为Google的专家,他的见解对于理解和克服这些挑战具有很高的价值。有效的信息检索系统需要综合运用多种技术,包括但不限于分布式计算、倒排索引、近似搜索算法等,以实现快速、准确的信息检索。同时,随着深度学习的发展,神经网络语言模型(如Transformer和BERT)正在成为语言建模的新趋势,它们能更好地捕捉上下文信息,进一步提升检索效果。

1.#!2(%.3045!
Es1ma1ng!bigram!probabili1e s!
• 6?=!>.b:/(/!i:4=8:?&&'!h0*/.$=!
!
P(w
i
| w
i"1
) =
count(w
i"1
,w
i
)
count(w
i"1
)
!
P(w
i
| w
i"1
) =
c(w
i"1
,w
i
)
c(w
i"1
)


剩余87页未读,继续阅读
2021-09-10 上传
2021-03-09 上传
2021-12-04 上传
2021-05-26 上传
2021-12-04 上传
2018-05-26 上传
2021-08-28 上传
2021-08-21 上传
2021-07-06 上传

legend0011
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机串口通信仿真与代码实现详解
- LVGL GUI-Guider工具:设计并仿真LVGL界面
- Unity3D魔幻风格游戏UI界面与按钮图标素材详解
- MFC VC++实现串口温度数据显示源代码分析
- JEE培训项目:jee-todolist深度解析
- 74LS138译码器在单片机应用中的实现方法
- Android平台的动物象棋游戏应用开发
- C++系统测试项目:毕业设计与课程实践指南
- WZYAVPlayer:一个适用于iOS的视频播放控件
- ASP实现校园学生信息在线管理系统设计与实践
- 使用node-webkit和AngularJS打造跨平台桌面应用
- C#实现递归绘制圆形的探索
- C++语言项目开发:烟花效果动画实现
- 高效子网掩码计算器:网络工具中的必备应用
- 用Django构建个人博客网站的学习之旅
- SpringBoot微服务搭建与Spring Cloud实践
