数据仓库粒度估算与设计策略
需积分: 9 72 浏览量
更新于2024-07-25
收藏 382KB PDF 举报
数据仓库的粒度和聚集是数据仓库设计中至关重要的环节,它们决定了数据组织的精细程度和查询效率。本章节主要探讨了以下几个关键知识点:
1. 粒度估算与划分:数据仓库开发者在设计初期面临的首要任务是确定粒度,即数据的细节程度。这涉及到预估未来数据行的数量以及可能需要的直接存取存储设备(DASD)。由于精确度难以保证,设计师通常需要进行粗略估计,以确定一个合理的数据量级。
2. 空间与行数计算:为了选择合适的粒度,需要对每张表的行数进行空间计算。包括估算一行数据的最大和最小占用字节数,以及在不同时间范围(如一年、五年)内的最大和最小行数。此外,还要考虑索引占用的空间。
3. 粒度划分的输入:基于空间估计结果,设计师需要考虑整个数据仓库环境的行数规模,决定采用双层或多层粒度。当行数较小(如10,000),可能任何设计都能应对;但随着行数增长至百万或千万级别,就需要更认真的设计策略,可能需要采用双重粒度级来平衡性能和存储需求。
4. 粒度级别决策:粒度级别的选择不是一次性的,而是需要反复分析和调整的过程。建议的方法包括快速构建小规模数据仓库原型、收集用户反馈、参考行业实践、与经验丰富的用户合作以及利用模拟输出进行团队协作。
5. 粒度阈值与时间周期:设计时还需要设定粒度的阈值,比如一年期和五年期,以适应不同的业务场景和查询需求。根据实际的数据变化和业务活动,可能需要在长期和短期粒度之间进行权衡。
通过这些步骤,数据仓库设计师能够更有效地规划数据结构,确保数据仓库能够支持高效的数据分析和报表生成,同时兼顾存储成本和查询性能。在实际操作中,细致的粒度设计和合理的聚集方式是实现数据仓库效益的关键。
2006-10 weizhidong@yahoo.com.cn 5
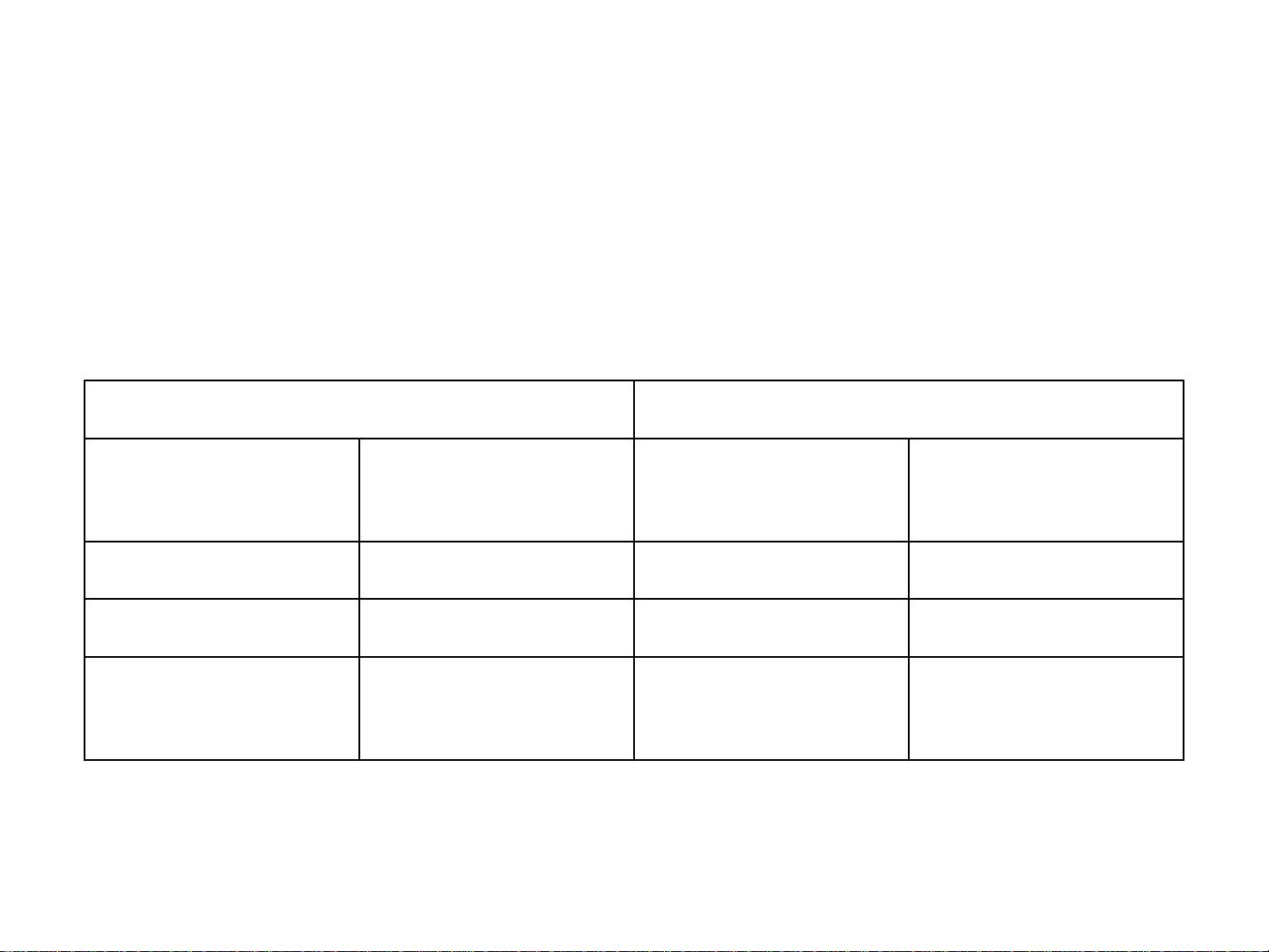
5.3 双重或单一的粒度?
根据数据仓库环境中将具有的总的行数的大小,设计和
开发必须采取不同的方法。
实际上任何设计
都行
100,000实际上任何设计
都行
10,000
认真设计1,000,000认真设计100,000
双重粒度级10,000,000双重粒度级1,000,000
双重粒度级且认
真设计
20,000,000双重粒度级且认
真设计
10,000,000
五年期一年期
粒度的阈值
剩余22页未读,继续阅读
2019-07-19 上传
2021-10-03 上传
2022-07-15 上传
2021-09-30 上传
2022-08-04 上传

allenchenlj
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握压缩文件管理:2工作.zip文件使用指南
- 易语言动态版置入代码技术解析
- C语言编程实现电脑系统测试工具开发
- Wireshark 64位:全面网络协议分析器,支持Unix和Windows
- QtSingleApplication: 确保单一实例运行的高效库
- 深入了解Go语言的解析器组合器PARC
- Apycula包安装与使用指南
- AkerAutoSetup安装包使用指南
- Arduino Due实现VR耳机的设计与编程
- DependencySwizzler: Xamarin iOS 库实现故事板 UIViewControllers 依赖注入
- Apycula包发布说明与下载指南
- 创建可拖动交互式图表界面的ampersand-touch-charts
- CMake项目入门:创建简单的C++项目
- AksharaJaana-*.*.*.*安装包说明与下载
- Arduino天气时钟项目:源代码及DHT22库文件解析
- MediaPlayer_server:控制媒体播放器的高级服务器
