CarbonData:打造万亿级数据仓库解决方案
“基于CarbonData构建万亿级数据仓库.pdf”描述了如何使用CarbonData技术来构建一个能够处理万亿级数据的数据仓库。CarbonData是一款开源的大数据存储和分析框架,旨在提供高性能、低延迟的数据处理能力,尤其适用于大规模数据分析场景。
Apache CarbonData是一个在Apache软件基金会下的孵化项目,自2016年6月开始,已经发布了多个稳定版本。它设计的目标是统一存储,以满足多种业务需求,并能与大数据生态系统无缝集成,支持包括详单过滤、海量数据仓库、数据集市等多种分析场景。
在构建万亿级数据仓库的过程中,CarbonData有以下几个关键特性:
1. **适用场景**:CarbonData适用于需要高效分析和处理海量数据的场景,如商业智能、批处理和机器学习。它可以处理各种类型的数据,包括结构化、半结构化和非结构化的数据,如呼叫详单记录(CDR)、交易数据、网络日志等。
2. **4个使用层次**:CarbonData提供了四个主要的使用层次,分别是:
- **BigTable**:用于存储大规模数据,支持复杂查询和分析。
- **SmallTable**:针对小规模数据进行快速访问和操作。
- **Unstructured Data**:处理非结构化数据,如文本、图片等。
- **Data Product**:数据产品层,将处理后的数据转化为可消费的服务供各个业务系统使用。
3. **核心诉求**:CarbonData的设计考虑了大数据处理的关键需求,包括:
- **稳定性**:能够稳定地处理PB级别的数据。
- **多工作负载支持**:支持增量加载、更新、编程和SQL查询等不同工作负载。
- **性能**:快速的数据入库和分析能力。
- **数据源对接**:兼容开源生态,传统数据库和其他数据源。
4. **高性能特性**:为了实现高性能,CarbonData采用了以下技术:
- **复杂SQL优化**:优化SQL查询性能,尤其是对于复杂查询的处理。
- **特殊索引**:如全文索引、图索引、位图索引等,提高数据检索速度。
- **易用性**:提供标准SQL接口,简化开发过程。
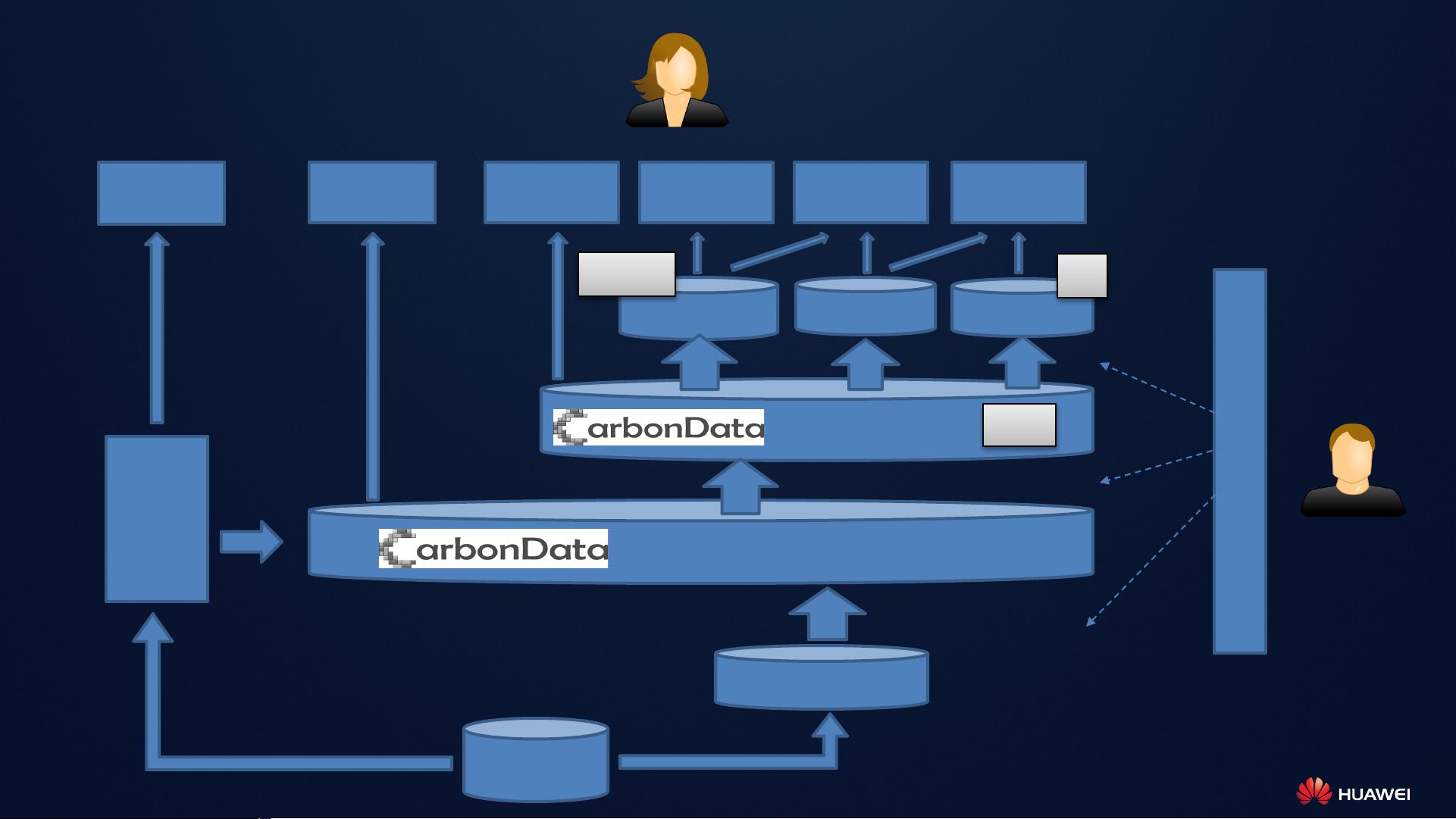
5. **数据处理流程**:数据从源头经过流处理,进入全量历史库,然后进行批量或流式写入,更新和实时更新。在主题库或业务库中进行明细数据查询,通过批量计算进行机器学习和汇总统计。同时,支持特殊索引以处理海量多租户场景,保证数据的快速访问。
6. **版本更新**:CarbonData持续进行版本迭代,例如计划在2018年9月发布1.5.0版本。
CarbonData通过其独特的设计理念和先进技术,为企业构建万亿级数据仓库提供了一个高效、灵活且易于使用的解决方案,满足了大数据时代对快速数据分析和处理的需求。
方案对比
全量历史库
批量
写入
流写
入
批量
更新
实时
更新
明细数
据查询
批量
计算
机器
学习
海
量
多
租
主题库/业务库
汇总
统计
批量
写入
机器
学习
特殊
索引
标准
SQL
HDFS
+PQ
Kudu
MPP
HBase
ES
不支持或很弱
中规中矩
擅长
HDFS
+CB

剩余50页未读,继续阅读
2018-10-15 上传
2018-10-09 上传
2022-08-04 上传
2023-09-04 上传
2018-12-26 上传
2021-10-08 上传
2021-03-05 上传
2021-03-05 上传

lin502
- 粉丝: 108
- 资源: 218
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
