HBase入门教程:概念与实战解析
"HBase入门及使用"
HBase是一款开源的分布式数据库,主要设计用于处理海量数据,它构建在Hadoop的HDFS之上,是Google Bigtable的一种开源实现。HBase适用于那些需要随机读写、大数据量、低延迟的场景,如实时分析、大数据存储等。
1. HBase基本介绍:
HBase是一个非关系型数据库(NoSQL),它提供了对半结构化数据的强一致性存储。其核心特性是基于行的存储、列族存储、时间戳和版本控制。HBase的数据模型由表(Table)、行(Row)、列族(Column Family)和列限定符(Column Qualifier)组成,数据以键值对的形式存储。
2. HBase性能:
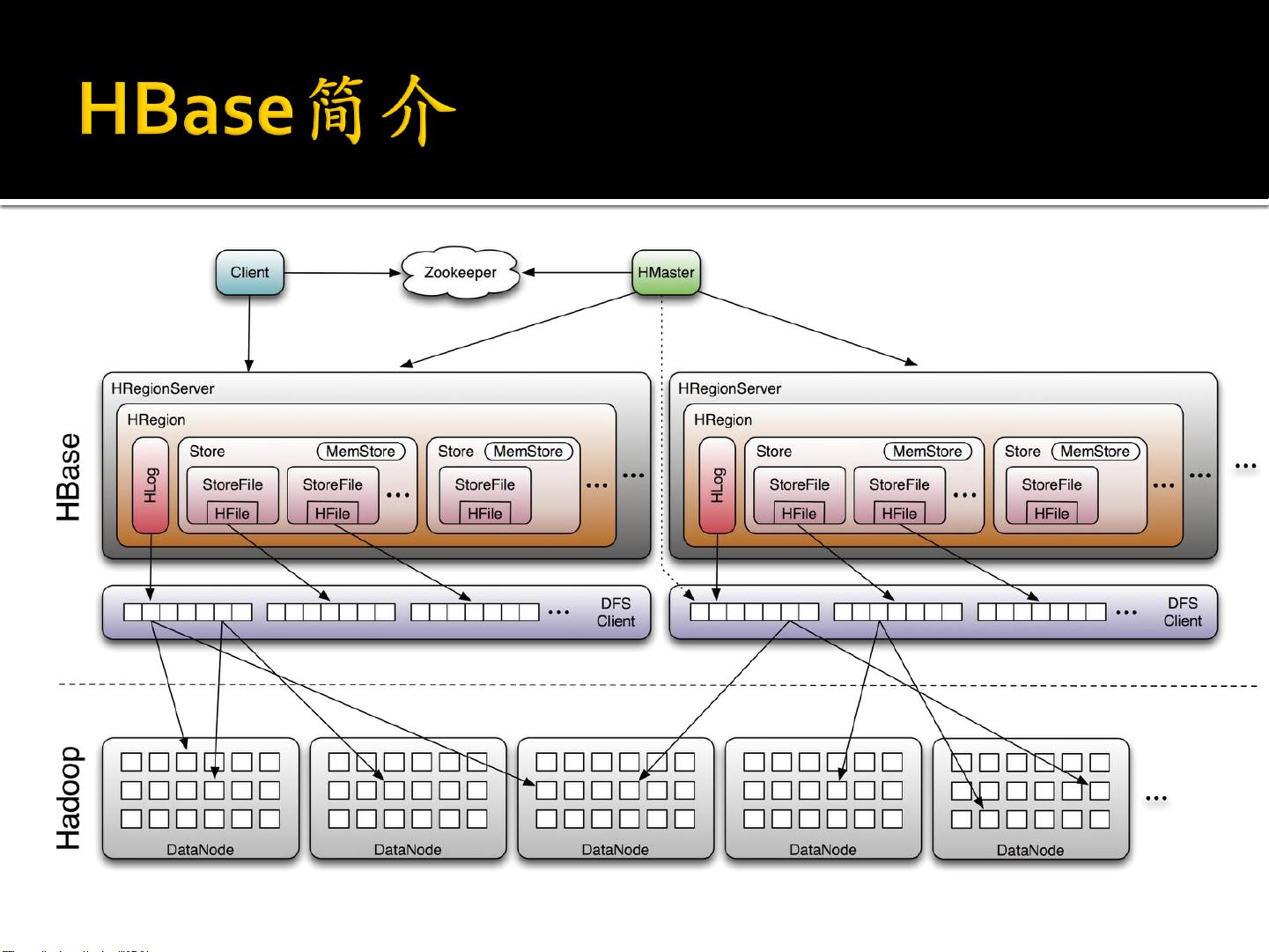
HBase的高性能来源于其列族存储、分布式架构和基于行的索引。通过RegionServer进行数据读写操作,Master节点负责Region的管理和负载均衡,确保系统的高效运行。此外,HBase利用HDFS提供数据冗余和容错性,保证了数据的可靠性。
3. HBase使用:
- 表(Table):HBase中的表由多个行构成,每个行都有一个唯一的行键(Row Key)。
- 列族(Column Family):列族是列的集合,每个列族下可以有任意数量的列,列名由列族名和列限定符组成。
- 列限定符(Column Qualifier):列族内的具体列,用于区分不同的数据。
- 版本(Version):每个值都带有时间戳,用于管理历史版本。
4. HBase@Taobao和YetAnotherNoSQL:
HBase在淘宝等大型互联网公司有广泛应用,例如在商品信息、用户行为分析等场景。YetAnotherNoSQL是HBase的一个社区项目,致力于改进和优化HBase。
5. Bigtable implementation:
HBase的设计灵感来自Google的Bigtable,但HBase是开源的,可以在Apache软件基金会的指导下持续发展。
6. Region管理:
- Region是表的逻辑分区,由起始和结束键定义。每个Region由一个RegionServer管理,随着数据增长,Region会自动分裂。
- RegionServer负责实际的数据读写,而Master则负责Region的分配和负载均衡。
7. 数据一致性与水平伸缩:
- 强一致性:同一行数据的读写只在一个RegionServer上进行,保证了读写操作的一致性。
- 水平伸缩:通过Region的自动分裂和Master的负载均衡,可以轻松增加或减少DataNode和RegionServer,实现容量和性能的扩展。
8. 行事务和查询支持:
- 行事务:HBase支持同一行内列的原子写入,但不支持跨行事务。
- 范围查询:通过Scanner可以执行范围扫描,获取特定范围内的一系列行数据。
总结起来,HBase是一个针对大规模数据集的高可用、高性能数据库,尤其适合实时数据处理和分析。其独特的数据模型、强大的分布式架构以及灵活的扩展性使其在大数据领域有着广泛的应用。学习和掌握HBase的使用,对于处理大规模的非结构化数据是非常有价值的。
剩余28页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2012-08-29 上传
2019-01-16 上传
2020-09-15 上传
2012-02-23 上传
2013-09-23 上传
235 浏览量

u010630996
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 编程之道全本 by Geoffrey James
- JBoss4.0 JBoss4.0 JBoss4.0 JBoss4.0 JBoss4.0
- DWR中文文档,DWR中文文档
- 汉诺塔问题 仅限11个盘子 效率较高
- 生化免疫分析仪——模数转换模块设计
- ajax基础教程.PDF
- symbian S60编程书
- 智能控制\BP神经网络的Matlab实现
- matlabziliao
- PowerBuilder8.0中文参考手册.pdf
- NNVVIIDDIIAA 图形处理器编程指南(中文)
- UMl课件!!!!!!!!!
- 电工学试卷及答案(电工学试卷2007机械学院A卷答案)
- 高质量C++编程指南.pdf
- 大公司的Java面试题集.doc
- 基于UBUNTU平台下ARM开发环境的建立
