DRIZZLE:Apache Spark的低延迟执行技术
需积分: 5 144 浏览量
更新于2024-06-21
收藏 3.36MB PDF 举报
“藏经阁-DRIZZLE_ Low latency execution for apache spark.pdf”
这篇PDF文档聚焦于DRIZZLE项目,这是一个针对Apache Spark优化的低延迟执行框架。由Shivaram Venkataraman、Aurojit Panda和Kay Ousterhout等人提出,他们都是在大规模机器学习系统设计领域有深厚背景的专家。其中,Shivaram Venkataraman是UC Berkeley AMPLab的博士研究生,他的研究方向涵盖了Spark核心、MLlib、SparkR以及低延迟的Spark Streaming。
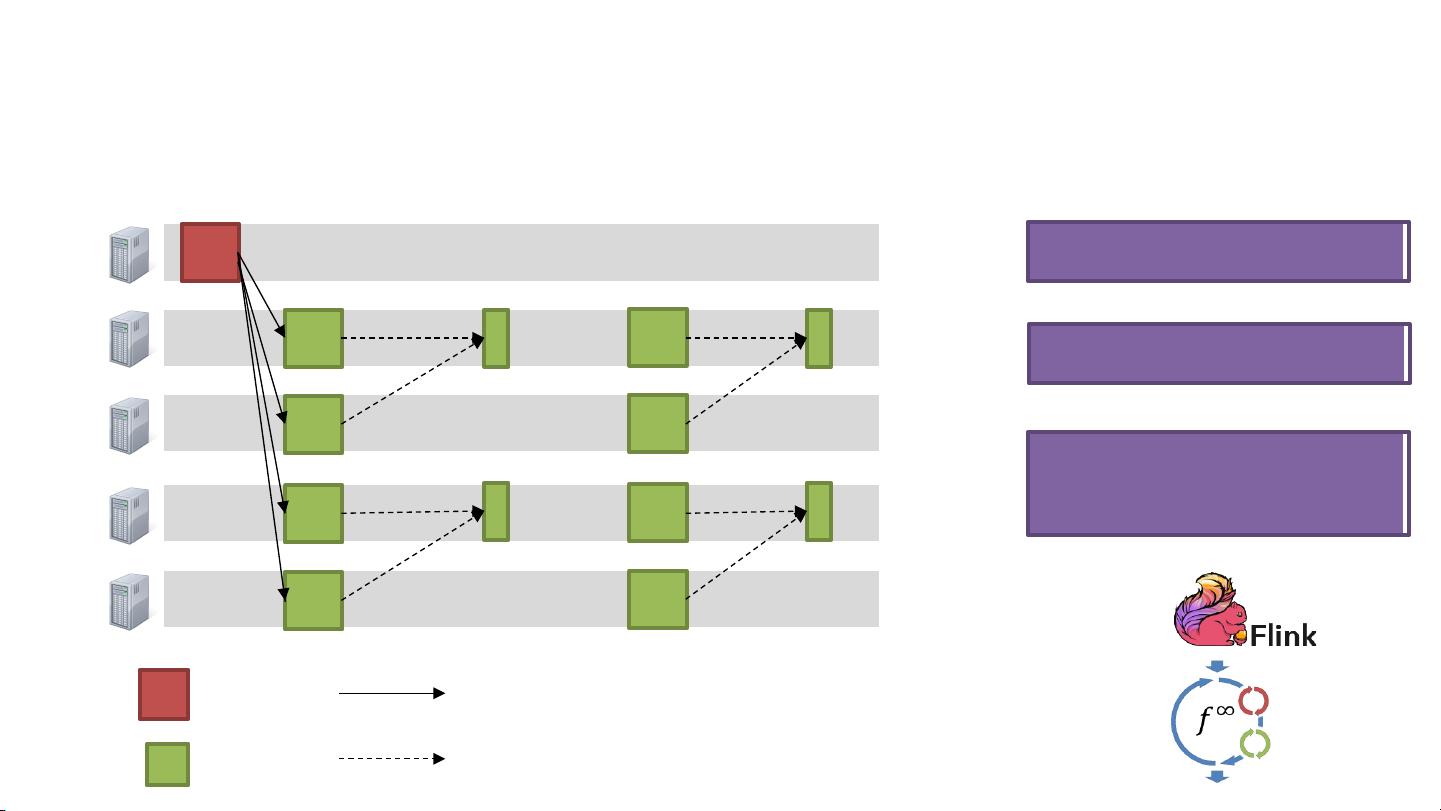
Apache Spark是一个流行的分布式计算框架,广泛用于大数据处理和实时流处理。然而,Spark Streaming虽然提供了高吞吐量,但在低延迟和稳定性方面存在挑战。根据文中引用的内容,目前的测试表明,Spark Streaming难以同时实现低延迟、高吞吐量和稳定性。例如,一个链接中提到,在选择DStream(Discretized Stream)的批处理间隔时,需要权衡这三个特性,因为过于频繁的批处理可能导致延迟增加,而批处理间隔过大会影响系统的响应速度。
为了改善这一情况,DRIZZLE项目致力于解决Spark Streaming中的低延迟问题。它可能通过更有效地利用集群资源,减少每个数据批次的处理时间,以及调整批处理大小来实现这一目标,确保数据能够在接收到后尽快被处理。文档中还提到了大规模流处理的一些关键目标,包括维护状态、低延迟和高吞吐量。
在大规模流处理中,性能是一个重要的考量因素,特别是在处理海量实时数据时。此外,适应性也是必要的,因为系统需要能够应对集群中的“拖尾节点”(straggler nodes),即处理速度较慢的节点,这些节点可能会导致整体处理延迟增加。因此,DRIZZLE可能采用了某种策略来减轻拖尾节点的影响,提高整个系统的效率和可靠性。
DRIZZLE项目旨在通过改进Apache Spark的执行模式,提供一种能同时兼顾低延迟、高吞吐量和稳定性的解决方案,这对于实时数据分析和大规模流处理应用至关重要。这可能涉及到优化调度算法、资源分配策略以及容错机制等方面,以确保在复杂的分布式环境中实现高性能的流处理。在实际应用中,这样的优化对于诸如金融交易分析、物联网(IoT)数据处理、社交媒体分析等实时性强的场景具有重大价值。

Execution Models!
剩余35页未读,继续阅读
2022-09-24 上传
2017-12-31 上传
2022-11-21 上传
2021-05-01 上传
2021-02-17 上传
2021-05-12 上传
2021-03-09 上传

weixin_40191861_zj
- 粉丝: 83
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握压缩文件管理:2工作.zip文件使用指南
- 易语言动态版置入代码技术解析
- C语言编程实现电脑系统测试工具开发
- Wireshark 64位:全面网络协议分析器,支持Unix和Windows
- QtSingleApplication: 确保单一实例运行的高效库
- 深入了解Go语言的解析器组合器PARC
- Apycula包安装与使用指南
- AkerAutoSetup安装包使用指南
- Arduino Due实现VR耳机的设计与编程
- DependencySwizzler: Xamarin iOS 库实现故事板 UIViewControllers 依赖注入
- Apycula包发布说明与下载指南
- 创建可拖动交互式图表界面的ampersand-touch-charts
- CMake项目入门:创建简单的C++项目
- AksharaJaana-*.*.*.*安装包说明与下载
- Arduino天气时钟项目:源代码及DHT22库文件解析
- MediaPlayer_server:控制媒体播放器的高级服务器
