MySQL索引优化:选择合适索引与覆盖索引策略
"VIP-mysql索引优化实战一.pdf"
MySQL是一个广泛使用的开源关系型数据库管理系统,其性能在很大程度上取决于有效的索引策略。本资源主要探讨了如何在MySQL中选择合适的索引,以及如何通过优化索引来提升查询效率。下面我们将深入分析相关知识点。
首先,我们来看创建的`employees`表结构。表中包含了`id`(主键),`name`(姓名),`age`(年龄),`position`(职位)和`hire_time`(入职时间)等字段,并创建了一个名为`idx_name_age_position`的联合索引,该索引基于`name`,`age`和`position`字段,使用了B树算法。
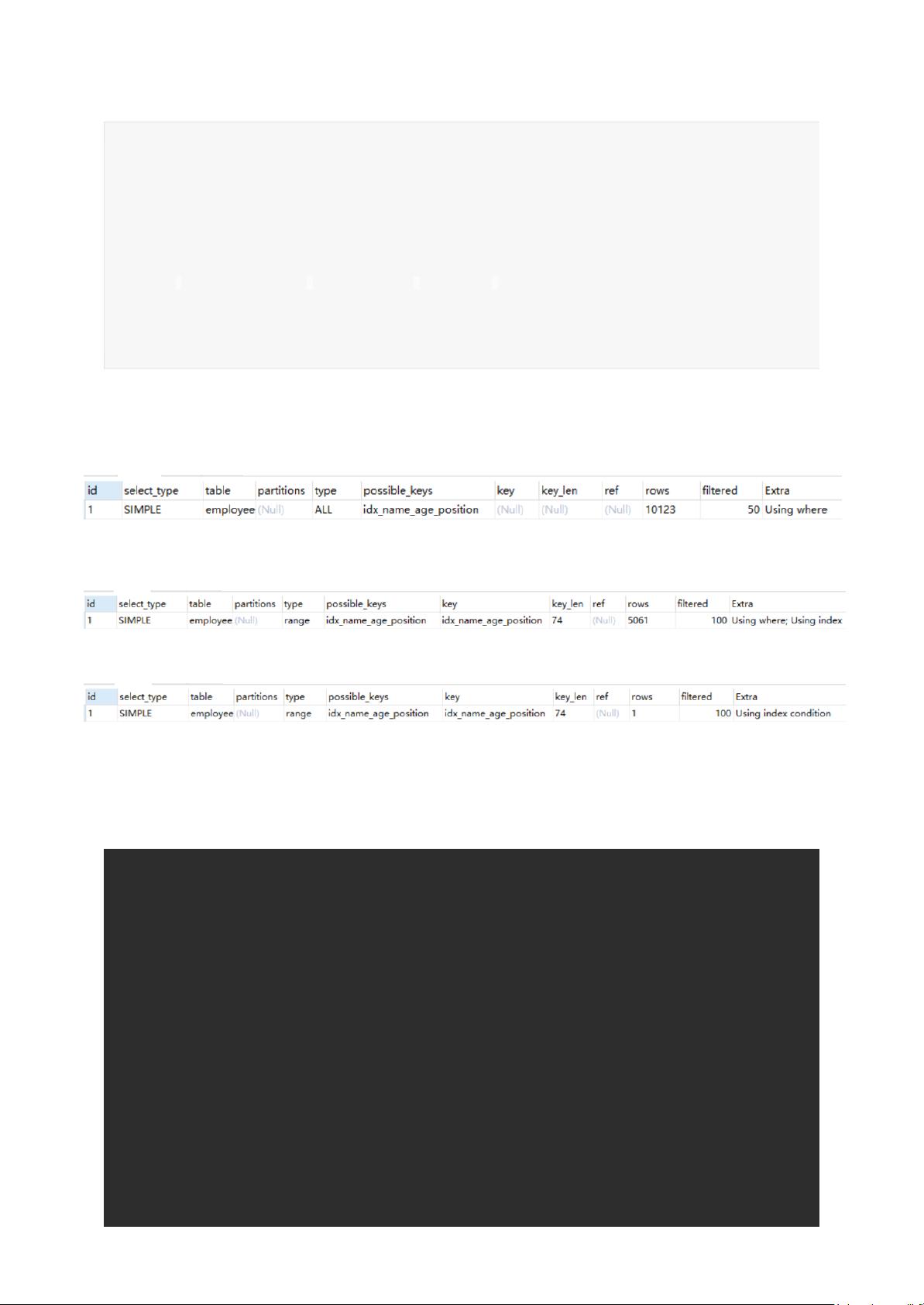
当执行查询时,MySQL会根据查询条件来决定是否使用索引以及如何使用。例如,查询所有名字大于`'a'`的员工信息:
```sql
mysql> EXPLAIN select * from employees where name > 'a';
```
在这个查询中,虽然`idx_name_age_position`索引存在,但因为查询返回所有列,MySQL需要在找到索引中的匹配项后,回表查询主键`id`以获取其他列的数据。这种被称为“回表”的操作实际上增加了查询的开销,导致使用索引可能比全表扫描更慢。
然而,如果我们只选择索引中的列,就可以利用“覆盖索引”(covering index)来优化查询:
```sql
mysql> EXPLAIN select name, age, position from employees where name > 'a';
```
在这个优化后的查询中,MySQL仅需遍历`idx_name_age_position`索引,就可以获取到所有需要的数据,而无需回表。这大大降低了查询成本。
另外,对于查询条件`name > 'zzz'`,如果表中大部分人的名字都在`'a'`到`'zzz'`之间,那么这个查询将返回大量数据,此时即使使用了索引,效果也可能不佳,因为返回的数据量太大,索引的优势被稀释。在这种情况下,全表扫描可能会更快,尤其是当数据量不大,且索引占用空间较大时。
优化索引的关键在于理解查询需求和索引的工作原理。应尽可能让索引覆盖查询所需的列,避免全表扫描和不必要的回表操作。同时,考虑数据分布情况和查询条件的筛选性也是选择合适索引的重要因素。在设计索引时,可以结合EXPLAIN语句来预估查询性能,以便做出最佳决策。此外,定期分析查询性能,根据实际情况调整索引策略,也是数据库维护的重要环节。
示例表
1 CREATETABLE`employees`(
2 `id`int(11)NOTNULLAUTO_INCREMENT,
3 `name`varchar(24)NOTNULLDEFAULT''COMMENT'姓名',
4 `age`int(11)NOTNULLDEFAULT'0'COMMENT'年龄',
5 `position`varchar(20)NOTNULLDEFAULT''COMMENT'职位',
6 `hire_time`timestampNOTNULLDEFAULTCURRENT_TIMESTAMPCOMMENT'入职时间',
7 PRIMARYKEY(`id`),
8 KEY`idx_name_age_position`(`name`,`age`,`position`)USINGBTREE
9 )ENGINE=InnoDBAUTO_INCREMENT=1DEFAULTCHARSET=utf8COMMENT='员工记录表';
10
11 INSERTINTOemployees(name,age,position,hire_time)VALUES('LiLei',22,'manager',NOW());
12 INSERTINTOemployees(name,age,position,hire_time)VALUES('HanMeimei',23,'dev',NOW());
13 INSERTINTOemployees(name,age,position,hire_time)VALUES('Lucy',23,'dev',NOW());
Mysql如何选择合适的索引
mysql>EXPLAINselect*fromemployeeswherename>'a';
如果用name索引需要遍历name字段联合索引树,然后还需要根据遍历出来的主键值去主键索引树里再去查出最终数据,成本比全表扫描
还高,可以用覆盖索引优化,这样只需要遍历name字段的联合索引树就能拿到所有结果,如下:
mysql>EXPLAINselectname,age,positionfromemployeeswherename>'a';
mysql>EXPLAINselect*fromemployeeswherename>'zzz';
对于上面这两种name>'a'和name>'zzz'的执行结果,mysql最终是否选择走索引或者一张表涉及多个索引,mysql最
终如何选择索引,我们可以用trace工具来一查究竟,开启trace工具会影响mysql性能,所以只能临时分析sql使用,用完
之后立即关闭
trace工具用法:
1 mysql>setsessionoptimizer_trace="enabled=on",end_markers_in_json=on;‐‐开启trace
2 mysql>select*fromemployeeswherename>'a'orderbyposition;
3 mysql>SELECT*FROMinformation_schema.OPTIMIZER_TRACE;
4
5 查看trace字段:
6 {
7 "steps":[
8 {
9 "join_preparation":{‐‐第一阶段:SQL准备阶段
10 "select#":1,
11 "steps":[
12 {
13 "expanded_query":"/*select#1*/select`employees`.`id`AS`id`,`employees`.`name`AS`name`,`empl
oyees`.`age`AS`age`,`employees`.`position`AS`position`,`employees`.`hire_time`AS`hire_time`from
`employees`where(`employees`.`name`>'a')orderby`employees`.`position`"
14 }
15 ]/*steps*/
16 }/*join_preparation*/
下载后可阅读完整内容,剩余9页未读,立即下载
2018-01-19 上传
2012-10-24 上传
2024-11-25 上传
2023-08-16 上传
2024-02-03 上传
2023-06-20 上传
2023-12-14 上传
2024-11-12 上传
2023-08-02 上传

runException1
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- phutbol_APITESTING:API测试
- git-course
- The-Utopian-Tree:计算树木在Spring和夏季生长周期中的高度
- spring-mybatis-jetty:基于Spring+Mybatis+Jetty实现简单的用户信息接口
- 管理系统系列--中医药管理系统后台.zip
- ProjetSiteRabaste
- 物联网智能家居方案-基于Nucleo-STM32L073&机智云-电路方案
- DataStructure-Algrithims:实现多种语言的DS和算法的存储库
- tuchong-daily-android:土冲日报安卓应用
- 基于opencv的水下图像增强与修复
- html5exercise
- 管理系统系列--智能广告机管理系统.zip
- SheenWood.github.io:ddfgfggdh
- mynewfavs
- 毕业设计分享-智能家居控制系统电路图&PCB图、程序-电路方案
- activemq-in-action:从 code.google.compactivemq-in-action 自动导出
