Python爬虫基础与反爬策略解析
 已收录资源合集
已收录资源合集
下载需积分: 0 | PDF格式 | 2.54MB |
更新于2024-06-27
| 119 浏览量 | 举报
"Python爬虫入门必会"
Python爬虫技术是互联网数据挖掘的重要工具,它允许开发者通过编程方式自动抓取网页信息。本资源详细介绍了编写Python爬虫所需的基础知识,包括理解反爬机制、HTTP/HTTPS协议、请求与响应头以及数据解析等关键概念。
1. 反爬虫机制:
门户网站常常设置反爬机制来保护其数据不被滥用。爬虫程序可以采用多种策略应对,如模拟浏览器行为、动态IP代理、设置延时等,以绕过这些限制。了解并遵循`robots.txt`君子协议也是避免侵权的重要步骤。
2. HTTP与HTTPS协议:
- HTTP(超文本传输协议)是服务器与客户端之间进行数据交换的标准,但通信过程不加密,存在安全风险。
- HTTPS(安全的超文本传输协议)是在HTTP基础上加入了SSL/TLS加密,增强了通信的安全性。加密方式包括对称密钥和非对称密钥,以及用于身份验证的证书密钥。
3. 请求与响应头:
- 请求头(Request Headers)中的`User-Agent`字段用来标识请求的来源,`Connection`字段用于指示请求完成后是否保持连接。
- 响应头(Response Headers)中的`Content-Type`字段告知客户端服务器返回数据的类型。
4. Python网络请求模块:
- `urllib`是Python的内置库,提供了一系列基础的网络请求功能。
- `requests`是一个更高级且易用的库,支持GET、POST等多种请求方法,并方便地处理请求头、数据和响应。
5. 发起请求与获取响应:
- 使用`requests.get()`发起GET请求,参数包括URL、params(查询参数)和headers(请求头)。
- 使用`requests.post()`发起POST请求,参数包括URL、data(发送数据)和headers。
- 响应数据可通过`.text`获取字符串形式,`.content`获取二进制,`.json()`解析为JSON对象。
6. 数据解析:
- HTML解析:可以使用`BeautifulSoup`库,它提供了便利的方法如`find()`、`find_all()`等进行HTML元素的查找、提取。
- 正则表达式:通过`re`模块配合`re.findall()`等函数,可以匹配和提取特定模式的字符串。
7. 环境安装与使用:
- 首先确保安装了必要的库,如`requests`和`beautifulsoup4`。
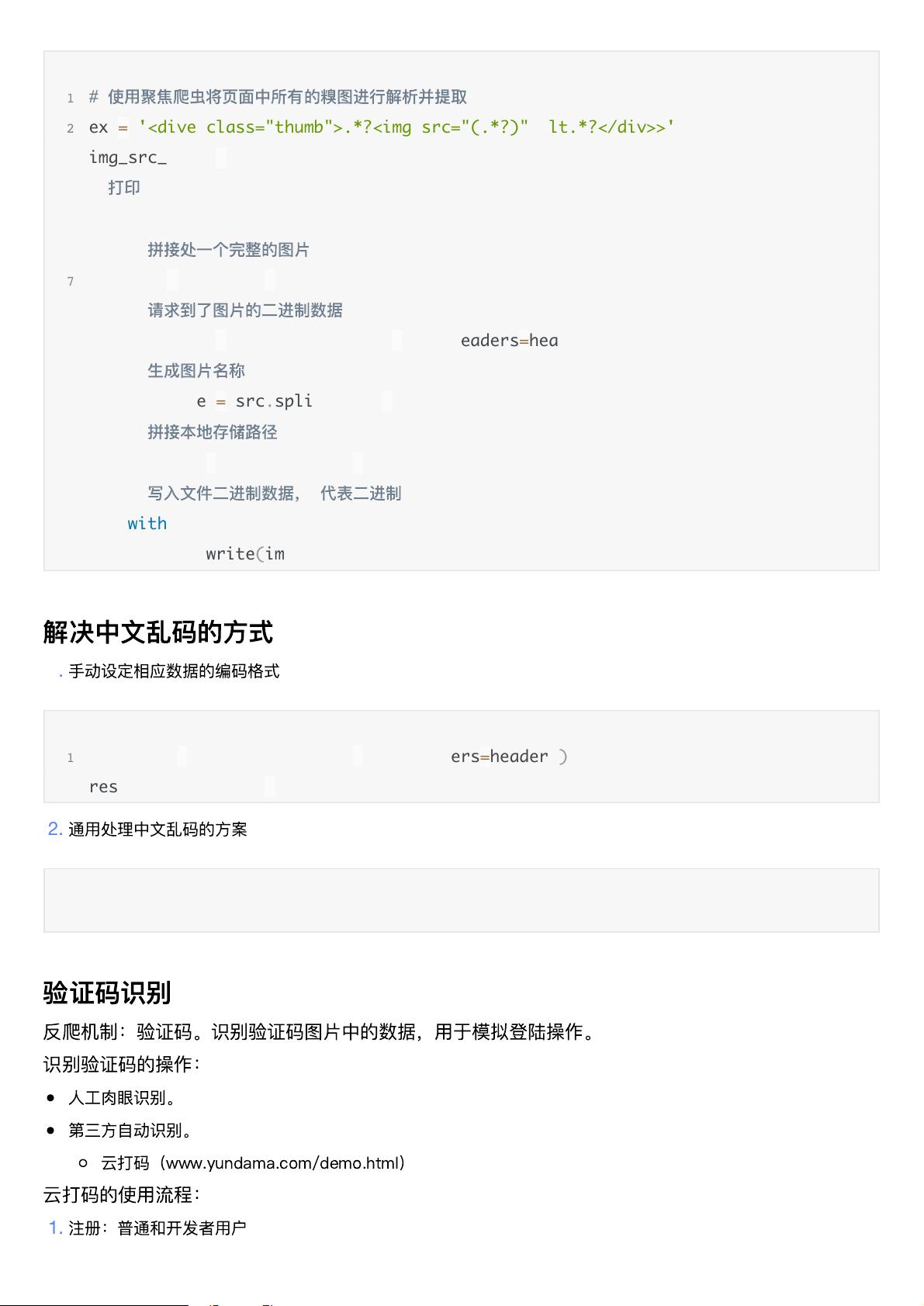
- 实例化`BeautifulSoup`对象,然后利用其提供的方法解析HTML,如聚焦爬虫的例子中,可找出所有包含图片的`<div class="thumb">`元素并提取图片源。
通过以上知识的学习,初学者可以掌握Python爬虫的基本技能,逐步实现从简单的网页抓取到复杂的数据分析。在实际操作中,还应注意遵守法律法规,尊重网站的版权和用户隐私,合理、合法地使用爬虫技术。
反
爬
机
制
:
验
证
码
。
识
别
验
证
码
图
⽚
中
的
数据
,
⽤
于
模
拟
登
陆
操
作
。
识
别
验
证
码的
操
作
:
云
打
码的
使
⽤
流
程
:
#
使
⽤
聚
焦爬
⾍
将
⻚⾯
中
所
有
的
糗
图
进
⾏解
析
并
提
取
1
ex = '<dive class="thumb">.*?<img src="(.*?)" alt.*?</div>>'2
img_src_list = re.findall(ex, page_test, re.S)3
#
打
印
img_src_list4
for src in img_src_list:5
#
拼
接
处
⼀个
完
整
的
图
⽚
url6
src = 'https:'+src7
#
请
求
到
了
图
⽚
的
⼆
进
制
数据
8
img_data = requests.get(url=src, headers=headers).content9
#
⽣
成
图
⽚
名
称
10
img_name = src.split('/')[-1]11
#
拼
接
本
地
存
储
路
径
12
imgPath = './qiutuLibs'+img_name13
#
写⼊
⽂
件⼆
进
制
数据
,
b
代
表
⼆
进
制
14
with open(imagPath, 'wb') as fin:15
fin.write(img_data)16
解
决
中
⽂
乱
码的
⽅
式
⼿
动
设
定
相
应
数据
的
编
码
格
式
response = requests.get(url=url, headers=headers)1
response.encoding = 'utf-8'2
通
⽤
处
理
中
⽂
乱
码的
⽅
案
img_name.encode('iso-8859-1').decode('gbk')1
验
证
码
识
别
⼈
⼯
⾁
眼
识
别
。
第
三
⽅
⾃
动
识
别
。
云
打
码
(
www.yundama.com/demo.html
)
注
册
:
普
通
和
开
发
者
⽤
户
1.
2.
1.
剩余23页未读,继续阅读
相关推荐








MattTian
- 粉丝: 390
 我的内容管理
展开
我的内容管理
展开







最新资源
- 微信小程序开发教程源码解析
- Step7 v5.4仿真软件:s7-300最新版本特性和下载
- OC与HTML页面间交互实现案例解析
- 泛微OA官方WSDL开发文档及调用实例解析
- 实现C#控制佳能相机USB拍照及存储解决方案
- codecourse.com视频下载器使用说明
- Axis2-1.6.2框架使用指南及下载资源
- CISCO路由器数据可视化监控:SNMP消息的应用与解析
- 白河子成绩查询系统2.0升级版发布
- Flutter克隆Linktree:打造Web应用实例教程
- STM32F103基础之MS5单片机系统应用详解
- 跨平台分布式Minecraft服务端:dotnet-MineCase开发解析
- FileZilla FTP服务器搭建与使用指南
- VB洗浴中心管理系统SQL版功能介绍与源码分析
- Java环境下的meu-grupo-social-api虚拟机配置
- 绿色免安装虚拟IE6浏览器兼容Win7/Win8
