基于代码相似性的VulPecker:自动漏洞检测系统
需积分: 16 119 浏览量
更新于2024-09-03
收藏 539KB PDF 举报
VulPecker是一种基于代码相似性分析的自动化漏洞检测系统,它旨在解决软件漏洞导致的安全问题。在当前的数字环境中,软件漏洞是诸多攻击的根本原因,尽管维护者努力通过快速补丁修复,但实际操作中,相同类型的漏洞可能出现在各种不同的软件副本中,如不同版本的库和应用,这使得漏洞追踪变得复杂。为了有效应对这一挑战,VulPecker的设计目标是开发一个能够自动搜索特定漏洞在各类软件中是否存在并进行检测的工具。
该系统的核心原理是利用代码相似性分析技术。通过对软件源代码进行深度比较,VulPecker能够识别出具有潜在安全风险的相似代码片段,这些片段可能隐藏着相同的漏洞。通过这种方式,它不仅提高了漏洞检测的效率,还扩大了覆盖范围,能够检测到那些在表面上看似不同的软件实例中的潜在威胁。
VulPecker的工作流程包括以下几个步骤:
1. **代码收集**:系统首先从各种来源收集大量软件代码,包括开源库、应用程序和网络上可用的代码库。
2. **代码预处理**:对收集的代码进行清理和标准化处理,以便于后续的相似性分析。
3. **代码相似性分析**:通过算法(如哈希函数、序列比对或语义分析)找出代码片段之间的相似性,特别是查找与已知漏洞相关的模式。
4. **漏洞匹配**:将预处理后的代码与已知漏洞数据库进行匹配,如果发现相似度较高的代码段,则认为可能存在类似漏洞。
5. **风险评估**:根据相似度和漏洞的历史影响程度,对检测到的疑似漏洞进行风险评估。
6. **报告生成**:生成详细的报告,包括漏洞位置、可能的影响范围以及建议的修复策略。
VulPecker的优势在于它能有效地弥补人工检查的局限性,节省大量时间和资源,并且可以及时发现那些因代码重复或继承而未被广泛注意到的漏洞。然而,系统的准确性和完整性依赖于所使用的代码相似性算法的质量以及漏洞数据库的全面性。此外,为了保持其有效性,VulPecker需要不断更新数据库以适应新的威胁和代码变化。
VulPecker作为一种创新的自动化漏洞检测工具,为提高软件安全性提供了有力支持,但也需要与持续改进的技术和不断更新的威胁情报相结合,以确保其在不断演变的网络安全环境中保持领先地位。
tion [15, 20], bug detection [18], and vulnerability detection
[25].
Comparison method. There are two kinds of compar-
ison methods: vector comparison and approximate/exact
matching. The vector comparison method first converts the
representation of a vulnerability and the representation of a
target program into vectors, and then compares these vec-
tors for detecting vulnerabilities [12, 25, 29, 30]. The ap-
proximate/exact matching method searches the representa-
tion of a vulnerability in the code representation of a target
program via containment [13, 17, 19], substring matching
[16], full subgraph isomorphism matching [18], or approxi-
mate γ-isomorphism matching [20].
Finally, it is worth mentioning that exploit signatures are
sometimes called vulnerability signatures, although they are
actually used to recognize exploits [4, 6]. These signatures
characterize the inputs that can be used to exploit vulnera-
bilities [6]. Exploit signatures are orthogonal to the vulner-
ability signatures we study in the present paper.
3. DESIGN
3.1 Overview
Vulnerability
Patch Database
(VPD)
Target programs
Vulnerability
diff hunk feature
generator
Code-similarity algorithm selection
Algorithm
selection
engine
Vulnerability signature generation
Patched/
unpatched diff
code extraction
Unpatched
code fragment
extraction
Diff
Vulnerability
signature
generator
Target program
signature generator
Vulnerability
detection engine
Vulnerability
locations
Vulnerability detection
Input
NVD
CVE-to-
algorithm
mapping
Vulnerability
signatures
CVE-IDs
Vulnerability
signatures
CVE-to-
algorithm
mapping
Output
Learning phase
Detection phase
Vulnerability Code
Instance Database
(VCID)
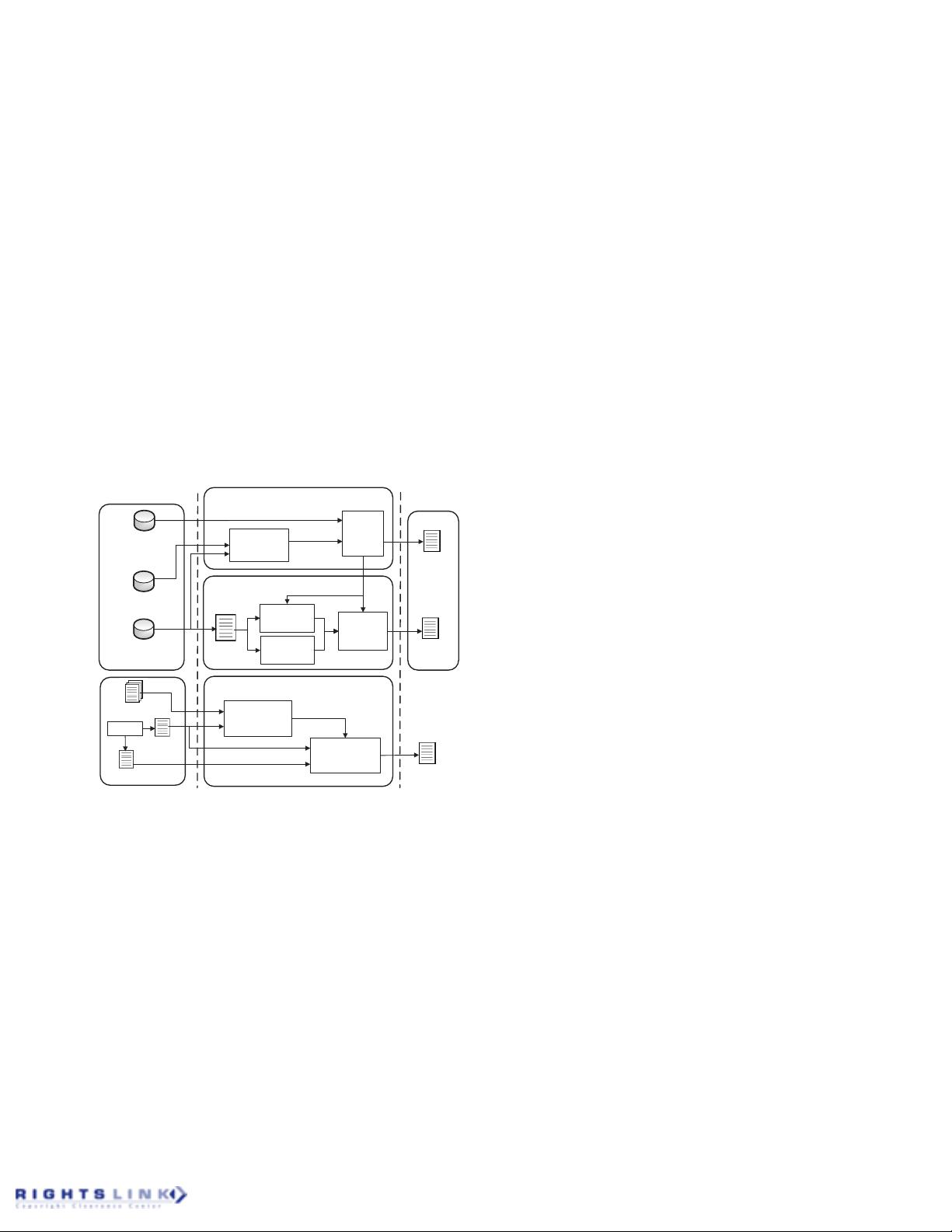
Figure 1: Overview of VulPecker: The learning
phase selects code-similarity algorithm(s) that is ef-
fective for a vulnerability. The select algorithms in
turn guide the generation of vulnerability signatures
and the detection of vulnerabilities.
Figure 1 gives an overview of VulPecker. It has two phases:
a learning phase and a detection phase. Before we elaborate
on the modules described in Figure 1, let us discuss two
high-level issues. First, which code-similarity algorithm(s) is
effective for detecting which vulnerability? In answering this
question, we analyze a set of candidate code-similarity algo-
rithms by taking advantage of features describing vulnerabil-
ities and patches. This analysis leads to a CVE-to-algorithm
mapping, which maps a CVE-ID to the select code-similarity
algorithm(s) that is effective for detecting the vulnerability.
Second, how should we generate and use vulnerability sig-
natures? Recall that a code-similarity algorithm can be
characterized by three attributes: code-fragment level, code
representation, and comparison method. We observe that
code-fragment level and code representation offer guidance
for generating signatures of vulnerabilities as well as signa-
tures of target programs. These signatures are then com-
pared with each other for determining whether or not a tar-
get program has a vulnerability. If a vulnerability is found,
the location of the vulnerable code fragment(s) is reported.
3.2 Defining vulnerability and code-reuse fea-
tures
Since our focus is to use code similarity analysis to detect
vulnerabilities, we need to define features to characterize
vulnerabilities and code reuses.
Features for describing vulnerability diff hunks.
Given a vulnerability and its patch, the vulnerability can be
characterized by the vulnerability diff,whichiscomposed
of one or multiple diff hunks.Eachdiffhunkcontainsa
sequence of lines of code, where each line is prefixed by a
“+” symbol (addition), “-” symbol (deletion), or nothing. In
order to define features to describe a vulnerability, it is suf-
ficient to define features that describe these diff hunks. For
adiffhunk,wedefinetwosetsoffeatures: basic features and
patch features. Table 1 summarizes these features. Basic fea-
tures are the Type 1 features described in Table 1, including
the unique CVE-ID, the Common Weakness Enumeration
Identifier (CWE-ID) that represents the vulnerability type,
product vendor, product affected, and vulnerability severity.
Patch features are the Type 2–Type 6 features described in
Table 1 and describe the code changes from the unpatched
piece of code to the patched one. The five types of patch
features are elaborated as follows.
• Non-substantive features: These features describe chan-
ges in whitespace, format or comment which have no
impact on useful code.
• Component features: These features describe the chan-
ges of components in statements such as varia bles, op-
erators, constants, and functions.
• Expression features: These features describe the chan-
ges of expressions in statements such as assignment
expression, if condition, and for condition.
• Statement features: These features describe the chan-
ges of statements involving addition, deletion, and mo-
vement.
• Function-level features: These features describe the
changes of functions or changes outside a function,
such as macros and global variable definitions.
Features for describing code reuses. The term “code
reuse”often means code cloning [5, 26], including exact clones,
renamed clones, near miss clones, and semantic clones. For
vulnerability detection, we are given a piece of code con-
taining a vulnerability and a target piece of code that may
or may not contain the same vulnerability, where the latter
may or may not be an exact clone of the former. Note that
we have already defined five types of patch features for de-
scribing vulnerabilities, namely Type 2–Type 6 described in
Table 1. Since these features can already describe the “trans-
formation” from an unpatched piece of vulnerable code to a
patched piece of code, which may be seen as a sort of code
reuse in a sense, we can naturally use these patch features
to describe code reuses.
3.3 Preparing the input
203
剩余12页未读,继续阅读
2021-03-11 上传
2021-05-19 上传
2021-05-14 上传
2021-05-09 上传
2021-03-08 上传
2023-08-31 上传
2011-10-06 上传
2021-03-08 上传
2021-04-13 上传

shadowlight123
- 粉丝: 4
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- NIST REFPROP问题反馈与解决方案存储库
- 掌握LeetCode习题的系统开源答案
- ctop:实现汉字按首字母拼音分类排序的PHP工具
- 微信小程序课程学习——投资融资类产品说明
- Matlab犯罪模拟器开发:探索《当蛮力失败》犯罪惩罚模型
- Java网上招聘系统实战项目源码及部署教程
- OneSky APIPHP5库:PHP5.1及以上版本的API集成
- 实时监控MySQL导入进度的bash脚本技巧
- 使用MATLAB开发交流电压脉冲生成控制系统
- ESP32安全OTA更新:原生API与WebSocket加密传输
- Sonic-Sharp: 基于《刺猬索尼克》的开源C#游戏引擎
- Java文章发布系统源码及部署教程
- CQUPT Python课程代码资源完整分享
- 易语言实现获取目录尺寸的Scripting.FileSystemObject对象方法
- Excel宾果卡生成器:自定义和打印多张卡片
- 使用HALCON实现图像二维码自动读取与解码
