大数据挖掘架构与方法论:并行计算详解与MPI应用
版权申诉
39 浏览量
更新于2024-07-03
收藏 1.11MB PDF 举报
本资源是一份关于大数据挖掘技术的分享文档,详细探讨了超大规模数据挖掘的架构和方法论。首先,它关注于如何在海量数据背景下实现高效的数据分析,强调了更深入的洞察和更科学的决策。主要内容分为两个部分:
1. **超大规模数据挖掘架构**:这部分介绍了主流的并行计算架构,包括如何处理数据挖掘中的并行特性。特别关注的是GDM(Geni-sage Data Mining)并行架构,这是一个专为大数据环境设计的架构,旨在解决传统串行计算中CPU和内存资源的重复占用问题,通过采用并行计算来提升性能。
- **主流并行计算架构**:这可能涵盖了分布式计算模型,如Hadoop MapReduce、Spark等,以及云计算环境下的资源调度策略。
- **数据挖掘并行特点**:涉及数据分割、并行处理、负载均衡和数据一致性等问题,解释了为何并行化在大数据挖掘中至关重要。
2. **数据分析方法论**:这部分可能讨论了如何在并行环境中设计和实施有效的数据挖掘算法,包括特征选择、模式识别、预测模型等,以及如何利用MPI(Message Passing Interface)这样的并行计算标准库进行编程。
- **MPI设计目标**:MPI是一种高效的并行通信框架,它的目标是提供一种易于使用的编程接口,使开发者无需关心底层的硬件和系统细节。MPI设计的关键点包括避免内存复制、支持异构环境、保证可靠性和线程安全,以及适应多用户平台。
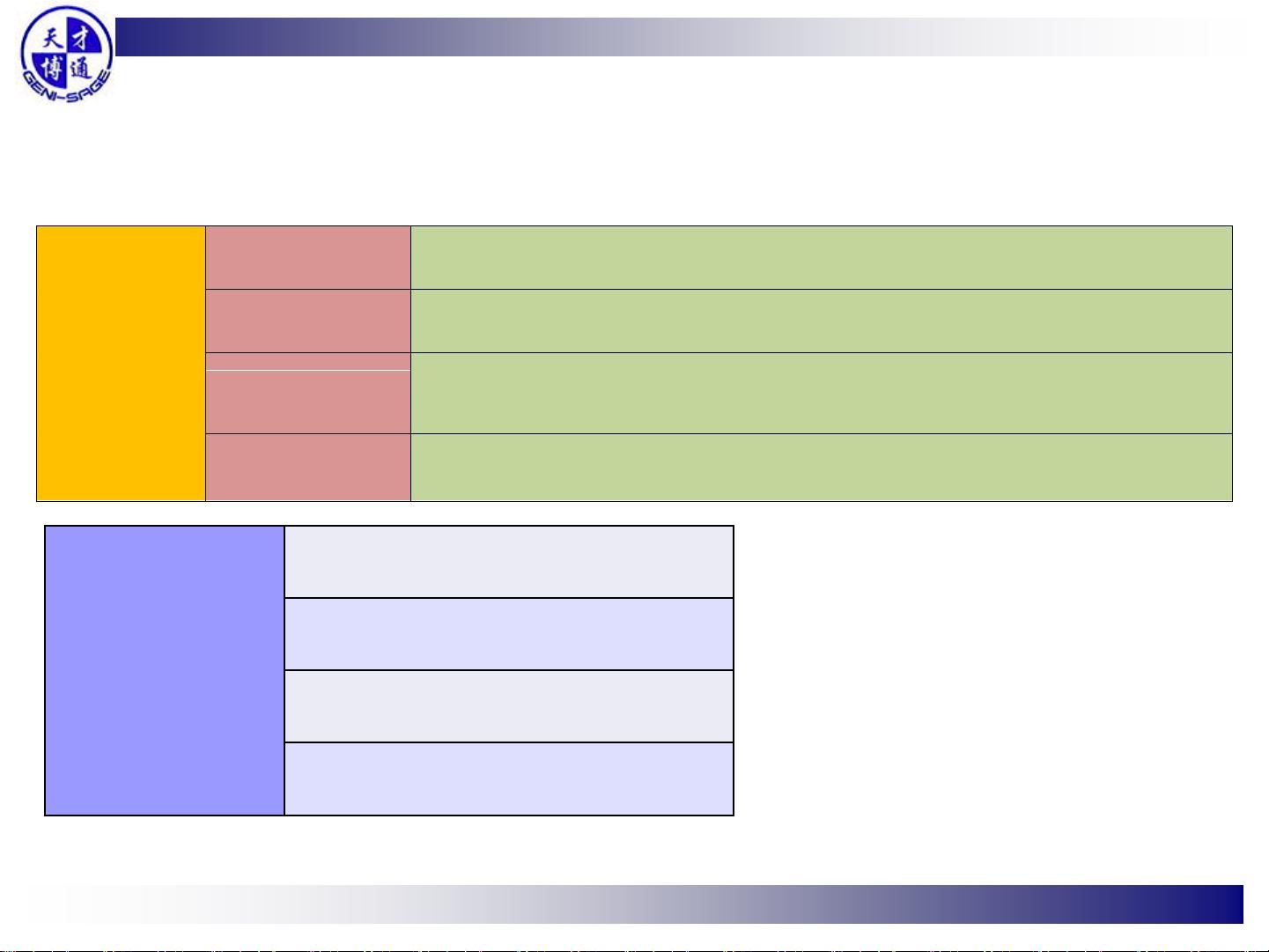
- **MPI基本函数**:文档详细列出了MPI的核心函数,如MPI_INIT用于初始化MPI环境,MPI_COMM_SIZE和MPI_COMM_RANK用于获取进程数量和标识,MPI_SEND和MPI_RECV用于进程间的通信,而MPI_FINALIZE则用于关闭MPI环境。
这份26页的PDF文件提供了实用的工具和技术,帮助读者理解如何在大数据时代利用并行计算技术进行深度数据挖掘,以获取洞察力和驱动科学决策。它不仅涵盖了理论概念,还包含了实际编程中如何应用MPI的实例,对于数据科学家和工程师来说是一份有价值的参考资料。

Further Insight,
Better Decisions
Copyright © 2007, Geni-sage Technology CO.,LTD. All rights reserved
5
MPI_INIT: 启动MPI环境
MPI_COMM_SIZE: 确定进程数
MPI_COMM_RANK: 确定自己的进程标识符
MPI_SEND: 发送一条消息
MPI_RECV: 接收一条消息
MPI_FINALIZE: 结束MPI环境
MPI基本函数
剩余25页未读,继续阅读
2022-04-05 上传
2021-07-14 上传
2023-10-09 上传
2023-05-03 上传
2023-08-09 上传
2023-07-13 上传
2023-12-30 上传
2023-12-05 上传
2023-06-21 上传

passionSnail
- 粉丝: 448
- 资源: 6875
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
