数据分类学习:定义与实例解析
版权申诉
83 浏览量
更新于2024-07-07
收藏 4.02MB PDF 举报
"01-第5章 数据分类.pdf,主要介绍了数据分类的基本概念、定义以及数据集格式,通过中国大学MOOC平台进行在线学习。"
在机器学习领域,数据分类是一项基础且重要的任务,其目标是根据输入的特征对数据进行预定义类别的归属预测。第5章的数据分类主要探讨了以下几个核心知识点:
1. **分类的定义**:分类是一种监督学习方法,它涉及到将数据样本依据其属性特征映射到预先设定的类别中。这个过程通常基于归纳学习算法,如决策树、朴素贝叶斯、逻辑回归、支持向量机等,通过学习已知的属性向量与对应的类标签,来构建一个分类模型。
2. **数据集格式**:在分类问题中,数据集通常包含两部分:描述属性(或称为特征)和类别属性。描述属性是用于训练模型的输入变量,如年龄(Age)和薪水(Salary);类别属性是需要预测的目标变量,如上述例子中的Class,可能有多个不同的类别(如c1, c2)。
3. **示例数据**:数据集通常以表格形式展示,例如:
- 年龄:30, 薪水:高, 类别:c1
- 年龄:25, 薪水:高, 类别:c2
- 年龄:21, 薪水:低, 类别:c2
- ...
这些实例展示了不同个体的属性值,可用于训练分类模型。
4. **分类问题的解决步骤**:一般包括数据预处理(如缺失值处理、异常值检测、特征选择等)、模型选择与训练、模型评估(如准确率、召回率、F1分数等)、模型调优(如参数调整)以及最终的预测应用。
5. **机器学习算法的应用**:不同的分类问题可能适合不同的算法。例如,线性问题可能选择逻辑回归,非线性问题可能选择决策树或神经网络,而支持向量机则适用于解决高维问题。每种算法都有其优缺点,需结合具体问题进行选择。
6. **交叉验证**:在模型训练过程中,为了提高模型泛化能力,通常会采用交叉验证技术,如k折交叉验证,将数据集分成k个子集,每次用k-1个子集训练模型,剩下的子集用来测试,重复k次并取平均结果。
7. **模型评估指标**:除了准确率外,还包括精确率、召回率、查准率、查全率和F1分数等,这些指标可以帮助我们全面地评估模型的性能。
通过对中国大学MOOC上的这门课程的学习,读者可以掌握数据分类的基本原理和实践技巧,进一步提升在机器学习领域的分析和预测能力。
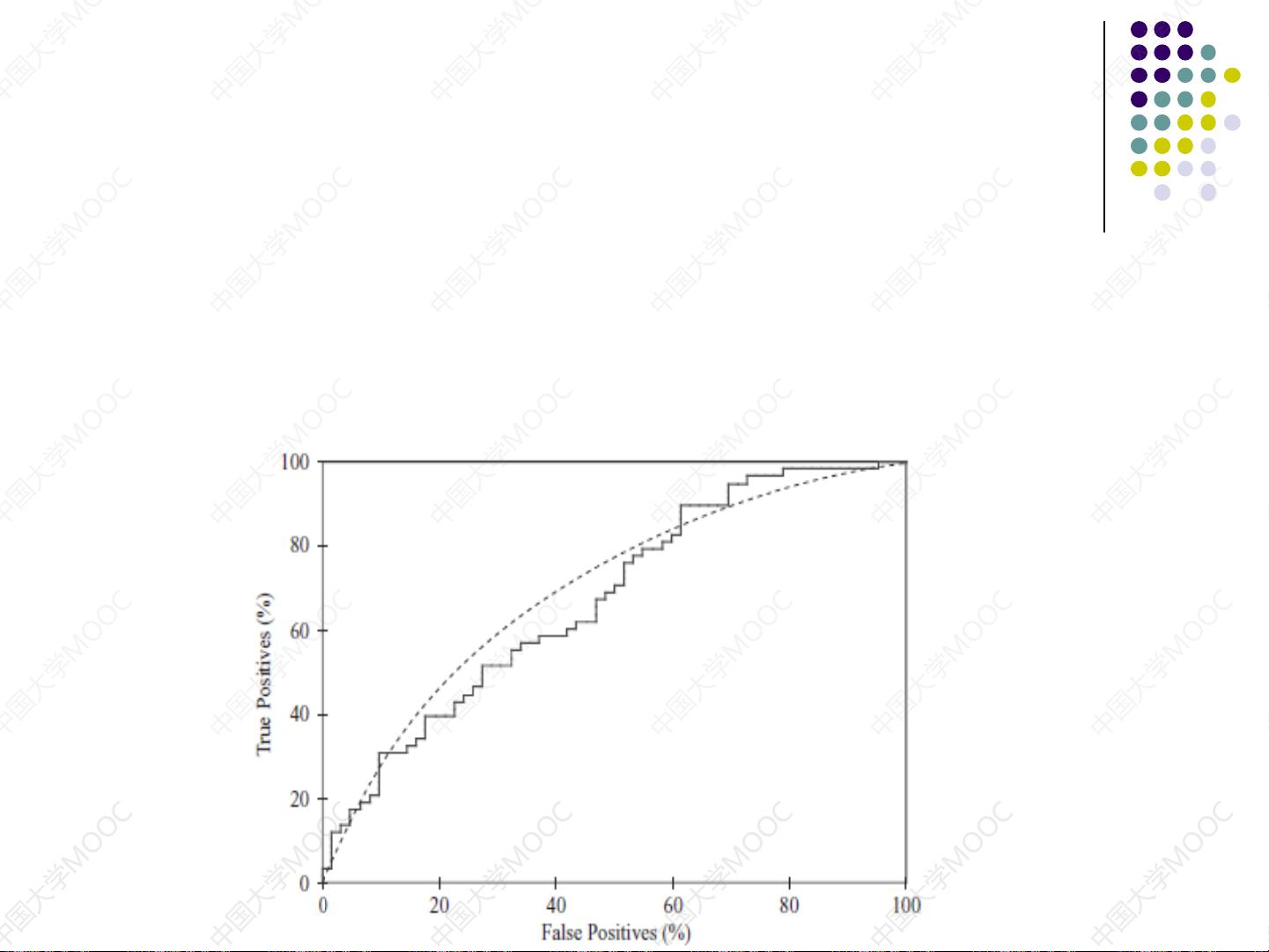
预测的准确率常用于比较和评估分类器的性能,
它将每个类别看成同等重要,因此可能不适合用
来分析不平衡数据集。在不平衡数据集中,稀有
类别比多数类别更有意义。也就是说,需要考虑
错误决策、错误分类的成本问题。例如,在银行
贷款决策中,贷款给违规者的代价远远比由于拒
绝贷款给不违规者而造成生意的代价损失大得多;
在诊断问题中,实际没有问题的机器误诊为有问
题而产生的成本比没有诊断出问题而导致机器损
坏而产生的损失小得多。
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC
中国大学MOOC



剩余157页未读,继续阅读
2020-12-24 上传
2023-05-14 上传
2019-08-13 上传
2020-12-24 上传
2021-09-26 上传
2021-11-11 上传
2021-11-25 上传
2021-10-11 上传
2022-07-04 上传

念广隶
- 粉丝: 4w+
- 资源: 6万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
