ZooKeeper:分布式协调利器与Hadoop HA集群搭建
需积分: 9 16 浏览量
更新于2024-07-18
收藏 1.74MB PDF 举报
"大数据时代zookeeper分布式协调工具"
在大数据时代,Zookeeper作为一个关键的分布式协调工具,扮演着至关重要的角色。本文将深入探讨分布式协调技术的概念,以及Zookeeper的概述、功能、工作角色,并通过实例展示如何利用Zookeeper搭建Hadoop的高可用(HA)集群。
一、分布式协调技术概述
分布式协调技术是解决分布式环境中多进程间同步和资源访问控制的核心技术。在一个分布式系统中,各个节点可能分布在不同的物理机器上,它们需要协作提供服务,而分布式协调就是确保这些进程能有序地访问共享资源,避免冲突和无序状态。例如,如果有三个进程分别在三台机器上运行,它们都需要访问同一资源,分布式协调器就会确保资源的访问顺序,保证系统的稳定运行。
二、Zookeeper概述
Zookeeper是由Apache软件基金会开发的开源项目,它是一个分布式的协调服务,源于Google的Chubby。Zookeeper提供了诸如分布式同步、配置管理、集群管理和命名服务等基础功能,使得开发者可以构建更复杂的应用程序。它的数据模型类似文件系统,使用znode(类似于文件或目录)来存储和管理数据,支持多种操作,如创建、删除、更新和查询znode。Zookeeper的设计目标是简化分布式应用的协调任务,提高系统的稳定性和效率。
三、Zookeeper提供的功能
1. 文件系统:Zookeeper以树形结构组织数据,允许动态创建和删除znode。
2. 分布式锁:通过创建临时znode实现分布式锁,确保资源的独占访问。
3. 配置管理:集中存储和更新分布式应用的配置,确保所有节点一致。
4. 集群管理:监控集群中节点的状态,自动处理故障恢复。
5. 命名服务:为分布式组件提供全局唯一的名字。
6. 队列管理:实现先进先出(FIFO)的队列,用于消息传递。
四、Zookeeper工作角色
Zookeeper作为一个中心化的服务器,维护了所有客户端的会话状态和数据变更记录。每个客户端与一个或多个Zookeeper服务器建立连接,发送请求并接收响应。服务器之间通过复制和选举机制保证数据的一致性和高可用性。
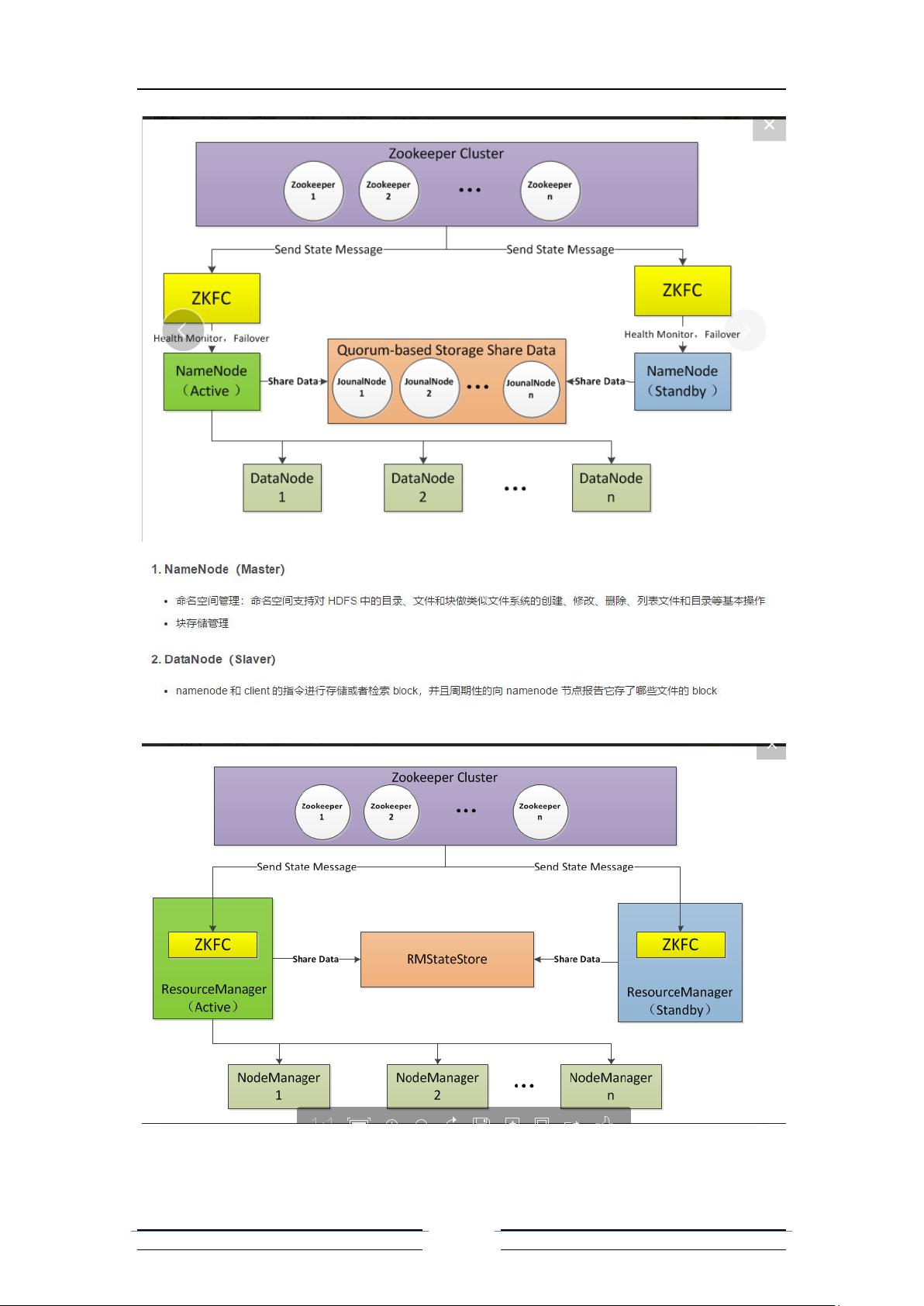
五、ZooKeeper搭建Hadoop的HA集群
在Hadoop中,Zookeeper常用于实现NameNode的HA,确保在主NameNode故障时能快速切换到备用NameNode,保证Hadoop集群的连续服务。具体步骤包括配置Zookeeper集群,设置Hadoop的HA参数,以及正确部署和启动所有组件。
六、案例:搭建Hadoop2.7.6结合Zookeeper-3.4.10完全分布式存储集群
实际操作中,会涉及安装Zookeeper和Hadoop,配置Hadoop的Zookeeper依赖,设置相关的配置文件如`core-site.xml`、`hdfs-site.xml`等,以及启动和测试HA功能。通过这样的实践,可以深入理解Zookeeper在Hadoop中的作用和配置过程。
Zookeeper作为分布式协调的重要工具,为复杂分布式环境下的资源管理和协同提供了强大的支持,是构建大规模、高可用系统不可或缺的一部分。掌握Zookeeper的原理和使用,对于理解和解决分布式系统中的问题至关重要。
资源由 www.eimhe.com 美河学习在线收集分享
6
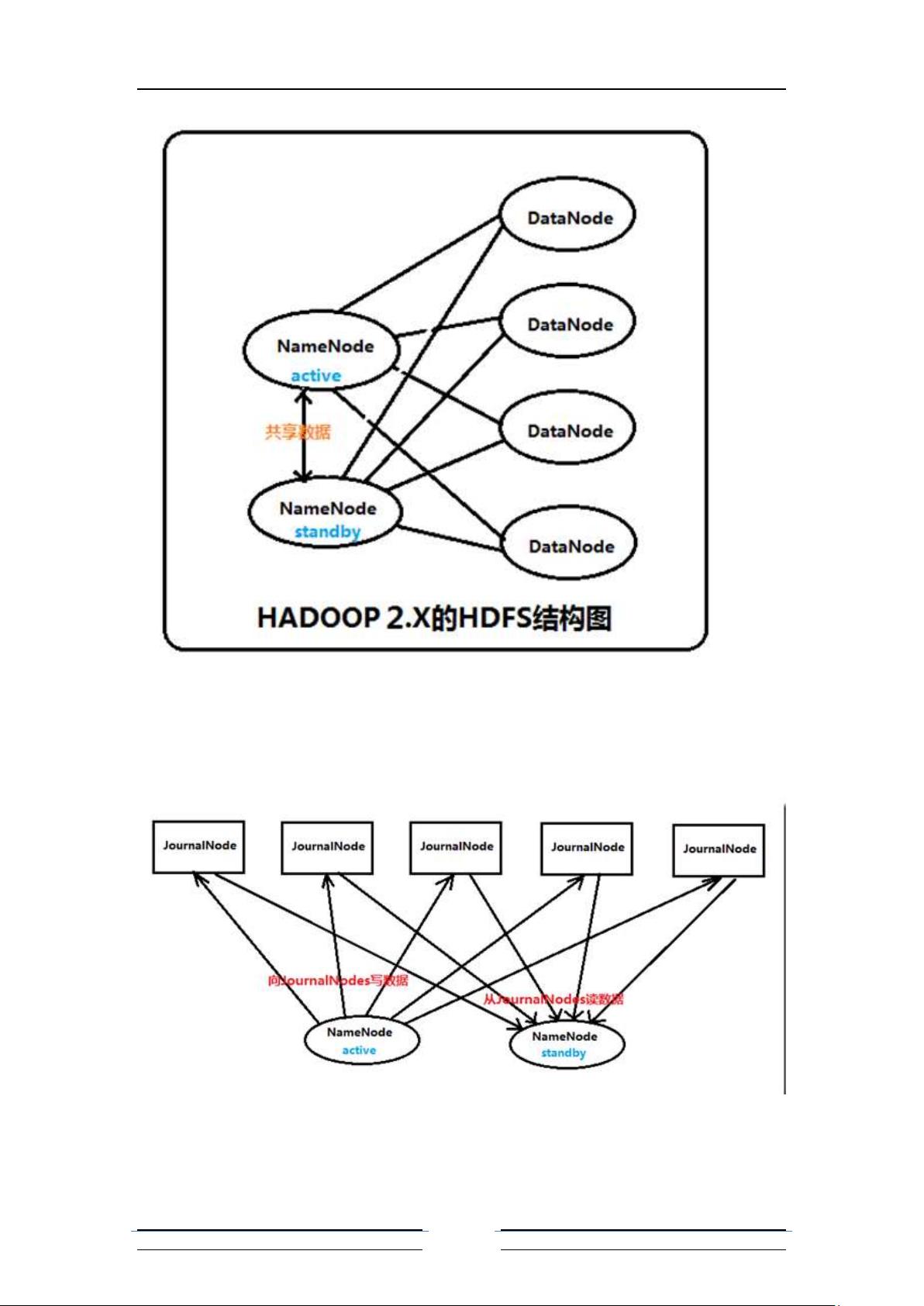
为了能够实时同步 Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog),
需提 供一个共享存储系统,可以是 NFS、QJM(Quorum Journal Manager)或者 Zookeeper,
Active Namenode 将数据写入共享存储系统,而 Standby 监听该系统,一旦发现有新数据写
入,则 读取这些数据,并加载到自己内存中,以保证自己内存状态与 Active NameNode 保
持基本一致,如此这般,在紧急情况下 standby 便可快速切为 active namenode;
Zookeeper+Namenode
剩余32页未读,继续阅读
2019-12-13 上传
2021-04-16 上传
2024-04-13 上传
2017-02-20 上传
2019-04-29 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

machen_smiling
- 粉丝: 509
- 资源: 1983
 我的内容管理
展开
我的内容管理
展开







最新资源
- word 排版技巧 不得不看的资源
- DS1302中文资料
- ajax实战中文版(最新)
- PowerBuilder制作IE风格的图标按钮
- PowerBuilder同时访问多个数据库
- Elements of Information Theory
- the GNU C library
- 关于抽象类和接口的两篇不错文章
- Tomact容器相关知识
- JasperReport 与iReport 的配置与使用
- arcgis介绍文件
- 数字温度计ds18b20的详细中文资料
- Groovy经典入门+.pdf
- 使用WEB方式修改域用戶密碼
- MYECLIPSE 下的 JAVA 教程
- 《Struts in Action中文版》
