SPSS多元逐步回归:3种筛选方法详解与结果解读
需积分: 11 25 浏览量
更新于2024-08-05
收藏 280KB DOCX 举报
多元逐步回归是一种统计分析方法,用于在多元线性回归模型中逐步选择和排除自变量,以优化模型的预测能力和解释能力。本文档详细介绍了在SPSS中实施多元线性回归的三种筛选自变量的方法:
1. 向前法:这是一种逐次加入自变量的方法。SPSS从一个初始的空模型开始,每次添加一个与当前模型偏差平方和最大且具有统计学显著性的自变量。此方法可能包括一些非关键变量,但有助于识别最重要的影响因素。
2. 向后法:虽然这种方法通常不常用,它从包含所有自变量的模型开始,然后依次移除那些偏差平方和最小且无统计学意义的变量。这个过程相对复杂,可能会漏掉重要的关联。
3. 逐步法:结合了向前法和向后法的优点,它在每一步都重新评估已纳入的变量,决定它们是否应继续保留。这样可以确保模型的准确性,避免过度拟合。
在进行多元逐步回归后,结果判断的关键在于:
- VIF值:如果VIF值大于10,意味着可能存在多重共线性,需要剔除相关性强的自变量,以提高模型的稳健性。
- 残差统计表:检查残差的正态性和独立性,以及库克距离(Cook值)来检测异常值或强影响点。在本例中,由于库克距离的最大值小于1,数据被认为适合进行回归分析。
模型构建过程中,文档展示了以下内容:
- 模型纳入变量表:记录了纳入模型的4个变量(LTP、SOM、SAN和LTN4)以及它们对产量的影响,使用步进法进行变量选择。
- 模型摘要:显示了每个模型的R方、调整后R方等指标,反映了模型的拟合优度。在本案例中,随着变量增多,R方和调整后R方逐渐增大,显示出模型的有效性。
最后,ANOVA表用来检验模型的整体显著性,通过观察F值(如F值分别为118.207、106.346),确认模型各阶段的改进是否具有统计学意义。
总结来说,本文档提供了一套完整的多元逐步回归分析流程,包括自变量的选择策略、结果评估标准,以及关键统计表格的解读,对于实际数据分析具有指导价值。
多元逐步回归有 3 种筛选自变量的方法:
(1)向前法:这种算法 SPSS 会建立由一个自变量开始,每次引入一个偏回归平方和最大
且具有统计学意义的自变量,由少到多,直到无具有统计学意义的因素可以代入方程为止
此法也可能纳入部分无意义变量;
(2)向后法:这种算法 SPSS 会先建立一个全因素的回归方程,再逐步剔除一个偏回归平
方和最小且无统计学意义的自变量,知道不能再剔除为止,这种方法算法较为复杂,一般
我们不使用;
(3)逐步法(本次分享):逐步法结合向前法和向后法的优点,在向前引入每一个新自变
量之后都要重新对已代入的自变量进行计算,以检验其有无继续保留在方程中的价值,并
以此为依据进行自变量的引入和剔除交替进行,直到没有新的变量可以引入或剔除为止,
此法较为准确。
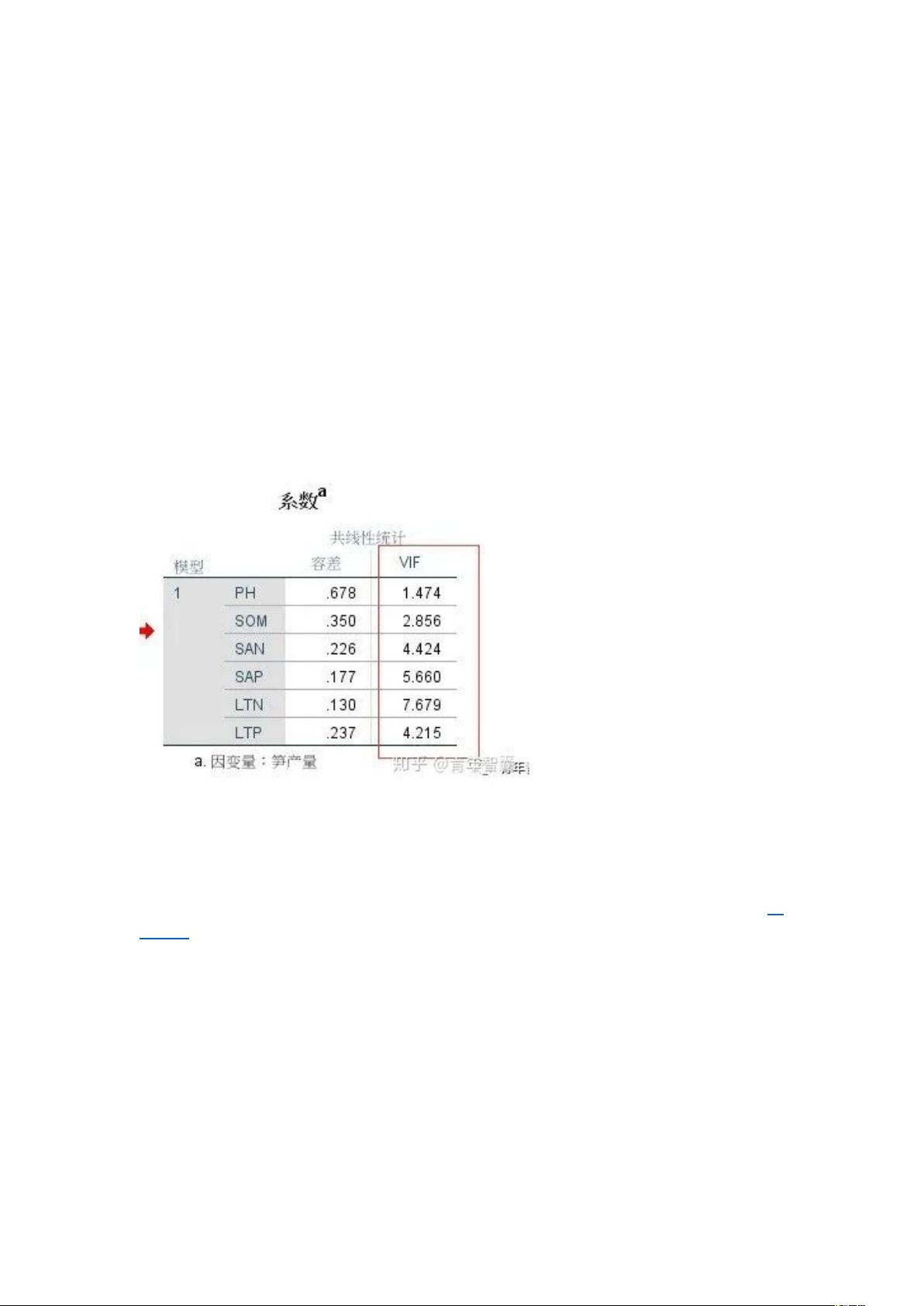
4.结果判断:在结果中我们关注系数表即可,当 VIF 值大于等于 10 时,我们认为变量间存
在严重的共线性,应当剔除部分 VIF 值较高的自变量,再进行多元逐步回归分析;当 VIF 值
小于 10 时,我们认为数据基本符合多元逐步回归分析的假设(4),即不存在多重共线性
问题,可以进行分析。
一、残差统计表
我们首先查看输出结果中的最后一个表,残差统计表。
在满足我们提到的 4 个假设后,我们还需要依据残差统计表中的库克距离(cook 值)来判
断数据有无强影响点,若库克距离的最大值大于 1,则应检查数据是否存在的异常值(检
验方法);若库克距离的最大值小于 1,则数据中不存在强影响点,可以进行下一步的分
析。
本案例中库克距离的最大值为 0.135<1,数据满足多元逐步回归分析的要求。
二、模型纳入变量表
通过此表我们可以看出:
(1)本次多元线性逐步回归分析一共拟合了 4 个方程模型;
(2)纳入模型的变量有 LTP、SOM、SAN 和 LTN4 个,输入方法为步进法;
(3)因变量为产量。
下载后可阅读完整内容,剩余3页未读,立即下载
2022-06-23 上传
2021-10-05 上传
2022-06-24 上传
2020-06-04 上传
2023-10-22 上传
2022-11-30 上传
2022-11-02 上传
2020-07-10 上传
2022-06-23 上传

weixin_53202186
- 粉丝: 0
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
