Python3爬虫实战:微博宫格验证码识别技巧
16 浏览量
更新于2024-09-01
收藏 324KB PDF 举报
在Python3爬虫中,识别微博宫格验证码是一项具有挑战性的任务,尤其是在处理交互式、动态的验证码时。验证码的结构特征包括四个宫格之间的连线,以及指示滑动方向的箭头,这些元素构成了验证码的识别关键。本文将详细介绍如何通过编程手段来解决这个问题。
首先,目标明确,即使用Python3和Selenium库配合Chrome浏览器来自动化识别并模拟滑动行为。Selenium允许我们控制浏览器行为,这对于动态加载内容的网页特别有用。然而,宫格验证码的复杂性在于其随机性和多样性,包括C型、Z型、X型等不同形状的连线,以及正反向的指示箭头,这要求识别算法不仅要理解线型,还要能够辨别箭头指向。
识别过程中,核心策略是找出规律。宫格间的连线和箭头提供了线索,但它们的位置和方向会随时间改变,这意味着不能简单地基于固定的视觉特征进行识别。为了处理这个问题,文章建议采用模板匹配的方法。这意味着预先收集和标记一系列的滑动路径模板,然后在实际验证码图像中寻找与模板最相似的部分。这涉及到像素点坐标的精确计算和比较,以及对箭头位置变化的敏感性。
模板匹配算法的具体实现可能包括以下步骤:
1. 图像预处理:对验证码图片进行灰度化或二值化处理,以便于提取关键特征。
2. 特征提取:定位宫格和连线,识别箭头的形状、位置和方向,这可能需要使用图像分析技术,如边缘检测、形状识别等。
3. 模板创建:根据识别到的滑动轨迹标记出四个宫格和连线的相对位置,形成模板图像。
4. 模板匹配:对于新的验证码图片,与所有预定义的模板进行比对,找到最佳匹配的模板。
5. 滑动路径预测:基于匹配的模板,推断出滑动的正确顺序,执行滑动操作以通过验证。
然而,这是一项复杂的任务,因为涉及到图像识别和模式识别技术,而且需要处理不同箭头位置带来的复杂性。实际操作中可能需要不断优化算法,甚至结合机器学习技术,如卷积神经网络(CNN)来提高识别精度。此外,应对验证码的频繁更新和变化也是一项持续的工作。
Python3爬虫中的微博宫格验证码识别需要深入理解图像处理、机器学习和动态网页抓取的知识,以实现高效准确的自动化处理。这不仅是技术上的挑战,也是对编程逻辑和问题解决能力的考验。
Python3爬虫里关于识别微博宫格验证码的知识点详解爬虫里关于识别微博宫格验证码的知识点详解
在本篇文章里小编给大家分享了关于Python3爬虫里关于识别微博宫格验证码的知识点,有兴趣的朋友们可以参
考下。
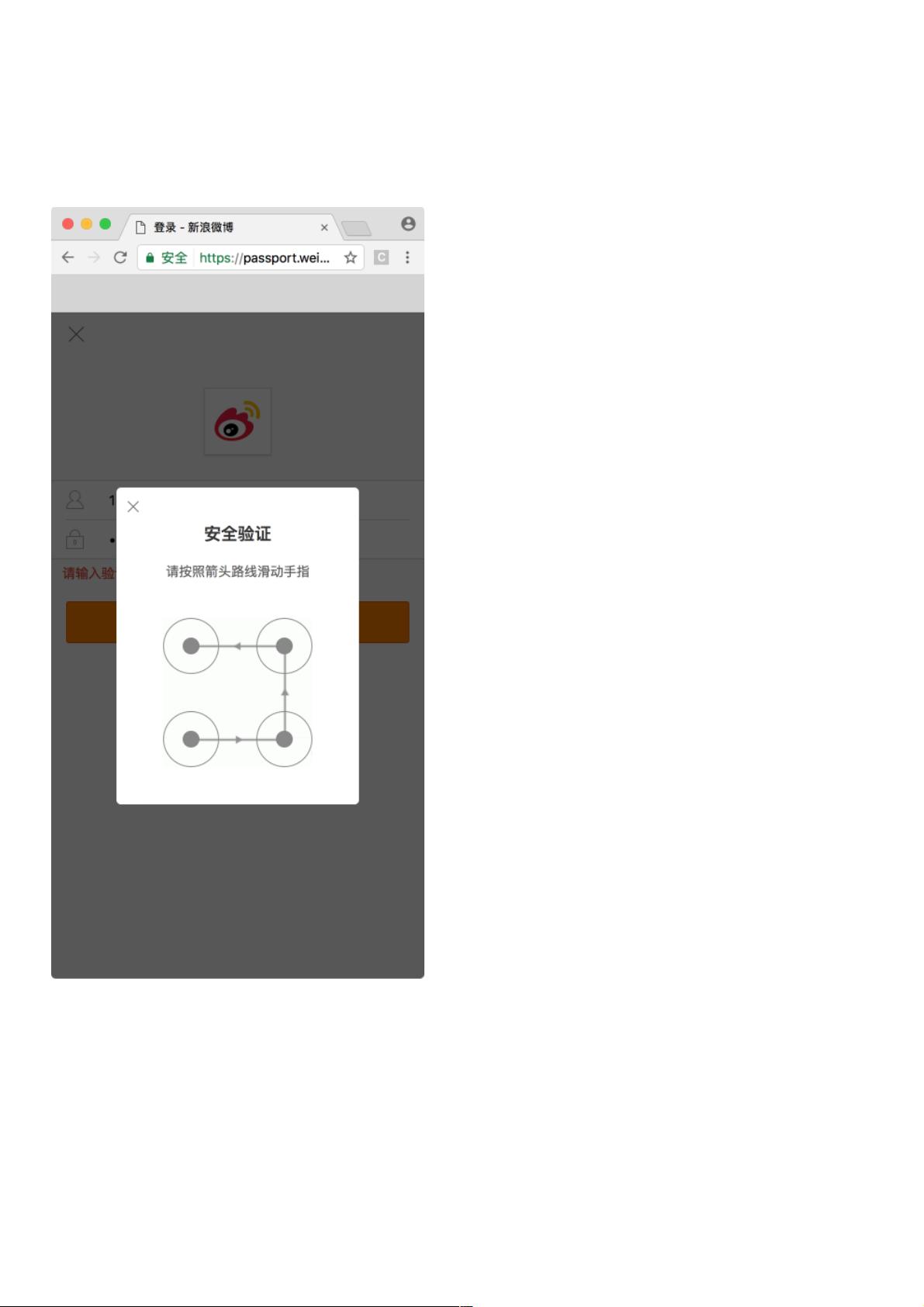
本节我们来介绍一下新浪微博宫格验证码的识别,此验证码是一种新型交互式验证码,每个宫格之间会有一条指示连线,指示
了我们应该的滑动轨迹,我们需要按照滑动轨迹依次从起始宫格一直滑动到终止宫格才可以完成验证,如图所示:
鼠标滑动后的轨迹会以黄色的连线来标识,如图所示:
下载后可阅读完整内容,剩余7页未读,立即下载
116 浏览量
点击了解资源详情
126 浏览量
2024-01-11 上传
280 浏览量
590 浏览量
135 浏览量
529 浏览量
156 浏览量

weixin_38593380
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 经典J2ME坦克对战游戏:回顾与介绍
- ZAProxy自动化工具集合:提升Web安全测试效率
- 破解Steel Belted Radius 5.3安全验证工具
- Python实现的德文惠斯特游戏—开源项目
- 聚客下载系统:体验极速下载的革命
- 重力与滑动弹球封装的Swift动画库实现
- C语言控制P0口LED点亮状态教程及源码
- VB6中使用SQLite实现列表查询的示例教程
- CMSearch:在CraftMania服务器上快速搜索玩家的Web应用
- 在VB.net中实现Code128条形码绘制教程
- Java SE Swing入门实例分析
- Java编程语言设计课程:自动机的构建与最小化算法实现
- SI9000阻抗计算软件:硬件工程师的高频信号分析利器
- 三大框架整合教程:S2SH初学者快速入门
- PHP后台管理自动化生成工具的使用与资源分享
- C#开发的多线程控制台贪吃蛇游戏源码解析
