
17
decade. However, this is still a young discipline. Until recently, it would have been
unthinkable to even try to work with complex scenes such as that in figure 1.1.
As Szeliski (2010) puts it, “It may be many years before computers can name and
outline all of the objects in a photograph with the same skill as a two year old
child.” However, this book provides a snapshot of what we have achieved and the
principles behind these achievements.
Organization of the book
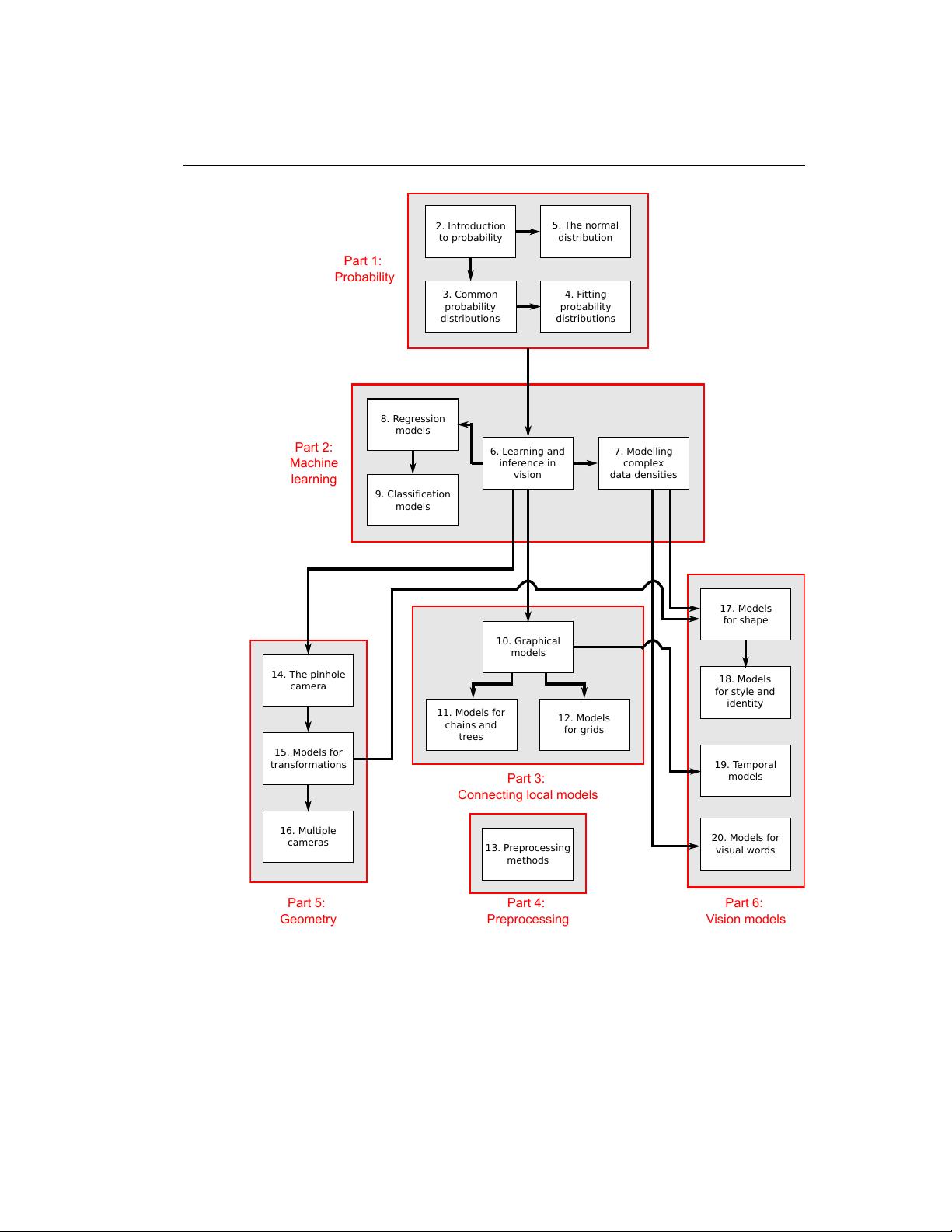
The structure of this book is illustrated in figure 1.2. It is divided into six parts.
The first part of the book contains background information on probability. All
the models in this book are expressed in terms of probability, which is a useful
language for describing computer vision applications. Readers with a rigorous
background in engineering mathematics will know much of this material already
but should skim these chapters to ensure they are familiar with the notation. Those
readers who do not have this background should read these chapters carefully. The
ideas are relatively simple, but they underpin everything else in the rest of the
book. It may be frustrating to be forced to read fifty pages of mathematics before
the first mention of computer vision, but please trust me when I tell you that this
material will provide a solid foundation for everything that follows.
The second part of the book discusses machine learning for machine vision.
These chapters teach the reader the core principles that underpin all of our methods
to extract useful information from images. We build statistical models that relate
the image data to the information that we wish to retrieve. After digesting this
material, the reader should understand how to build a model to solve almost any
vision problem, although that model may not yet be very practical.
The third part of the book introduces graphical models for computer vision.
Graphical models provide a framework for simplifying the models that relate the
image data to the properties we wish to estimate. When both of these quantities are
high dimensional, the statistical connections between them become impractically
complex; we can still define models that relate them, but we may not have the
training data or computational power to make them useful. Graphical models
provide a principled way to assert sparseness in the statistical connections between
the data and the world properties.
The fourth part of the book discusses image preprocessing. This is not necessary
to understand most of the models in the book, but that is not to say that it is
unimportant. The choice of preprocessing method is at least as critical as the
choice of model in determining the final performance of a computer vision system.
Although image processing is not the main topic of this book, this section provides
a compact summary of the most important and practical techniques.
The fifth part of the book concerns geometric computer vision; it introduces
the projective pinhole camera – a mathematical model that describes where a given
point in the 3D world will be imaged in the pixel array of the camera. Associated
with this model are a set of techniques for finding the position of the camera relative
to a scene and for reconstructing 3D models of objects.
Finally, in the sixth part of the book, we present several families of vision models
Copyright
c
2011,2012 by Simon Prince; published by Cambridge University Press 2012.
For personal use only, not for distribution.




 我的内容管理
展开
我的内容管理
展开







