PyTorch神经网络训练实战教程:模型构建与数据集设计
需积分: 0 88 浏览量
更新于2024-08-03
收藏 680KB DOCX 举报
本教程旨在提供一个通俗易懂的PyTorch神经网络训练指南,适合初学者和大创项目组员。通过作者个人经验,讲解如何使用PyTorch构建和训练神经网络模型。教程主要涉及以下几个关键步骤:
1. **网络模型设计**:
- 首先,需要定义一个网络模型,这通常包括选择合适的层结构(如卷积层、全连接层等)、激活函数和可能的池化操作。示例网络结构未给出,但理解基本的网络组件至关重要。
2. **训练函数编写**:
- 训练函数的核心部分是模型、训练次数(epochs)、学习率(lr)。优化器如Adam或SGD负责调整模型参数,使损失函数(如交叉熵损失)最小化,表示模型输出与真实标签的误差。这里提到的优化器和损失函数是基础配置,根据实际需求可选择不同的优化算法和评价指标。
3. **数据集处理**:
- 数据集是训练神经网络的关键,它包含训练样本及其对应的标签。数据集类需继承自`torch.utils.data.Dataset`,实现`__init__`、`__getitem__`和`__len__`方法。作者读取csi_el、csi_hy、video和ir四类数据,以`torch.tensor`形式存储,同时处理三维数据的维度问题,通过`torch.load`和`torch.cat`合并数据。
4. **标签处理**:
- 数据集中的标签通常不在数据本身,而是存储在文件名中。通过文件名解析获取标签,例如用one-hot编码转换多类别标签,确保标签与模型输出的维度匹配。
5. **训练流程**:
- 在`train`函数中,循环执行epochs次迭代,每次迭代通过数据集遍历数据,调用模型的前向传播得到预测值,计算损失,然后使用优化器更新模型参数。这是一个典型的“前向传播-反向传播-参数更新”流程。
通过本教程,读者将掌握如何在PyTorch环境中搭建、训练和优化神经网络模型,以及如何有效地管理数据集。理解这些核心概念有助于提升对深度学习模型训练的实践能力。
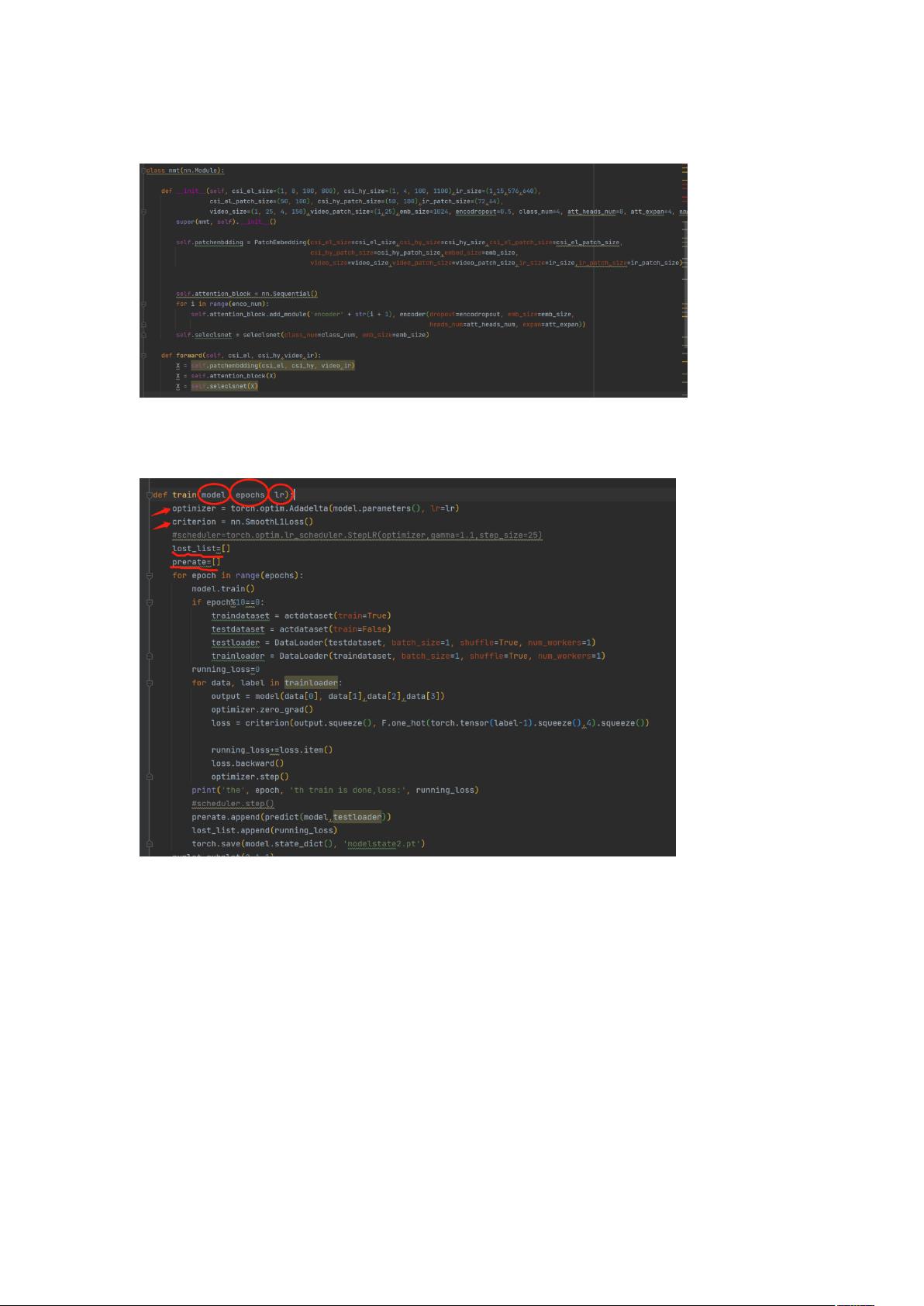
完成一个完整的训练过程,你需要有网络模型、数据集、训练函数、预测函数
假设你已经写好了一个网络模型(不用在意我给出例子的网络结构)
------------------------------------------
接下来你编写训练函数(我给出的例子具有本人完成工程所需要的特殊性,不必在意完成方
法)
但总的说来,训练函数往往需要你输入模型 model、训练次数 epochs、学习率 lr(红圈)
首先我们先创建了优化器 optimizer 和损失函数 criterion(箭头所指处),优化器决定了我们
的模型参数通过怎样的方式下降以使模型输出贴近标签指示的正确答案;损失函数决定了以
什么函数来衡量模型输出与正确输出的差距。优化器与损失函数可以参考我的,也可以上网
搜索更为合适的。
准备工作完成后我们准备进行正式的训练↓
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-05-20 上传
2024-04-22 上传
2021-04-06 上传
2024-04-22 上传
106 浏览量
2024-04-22 上传

很凡
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 淘淘商城源码-Java代码类资源
- mybatis - Springboot+Mybatis+MySql搭建实例.zip
- 商务团队背景的商务幻灯片下载PPT模板
- Python库 | VizKG-0.0.3-py3-none-any.whl
- 直方图修改:代码执行直方图修改-matlab开发
- Android-project-FishPond:ZJU中的Android课程,这是名为FishPond的最终项目,这是一个适合时间大师的应用
- mm-screen:马克·米纳维尼(Mark Minervini)在“像股票向导一样交易”一书中描述的股票筛选器,用于识别超级绩效股票
- POO-2021
- SergioHPassos.github.io
- Quarantine-Friends:编码Dojo小组项目
- code-red:可视化代码 RED
- EpigenomicsTask_MscOmics
- VK-DMR:VK DMR文件
- kiwi:简约的内存键值存储
- Trex-Game-2:有游戏结束条件
- Python库 | vizex-2.0.4-py3-none-any.whl
