大数据时代的随机权神经网络建模方法及应用
版权申诉
182 浏览量
更新于2024-04-04
收藏 1.06MB DOCX 举报
信息技术的迅速发展使得生产制造行业进入大数据时代, 这为数据建模提供了大量的数据样本, 使得数据驱动建模在不同领域产生广阔的应用空间。然而,系统复杂度和数据规模的日益增大为数据建模算法带来新的挑战。模型精度取决于样本的质量与数量,但超过一定规模的样本数据,会显著增加网络参数训练与优化的成本,且难以有效学习,导致模型的整体性能下降。在采用传统神经网络算法进行大数据建模时,所得到的模型往往存在训练耗时、网络结构复杂等问题,难以满足实际应用的需求。因此,建立一种能够从大量数据中快速、高效学习的策略具有重要意义。
上世纪90年代,提出的随机向量函数链接网络与另一种具有随机权值的单层前馈神经网络被统称为随机权神经网络(Random weight neural networks, RWNNs)。其特征在于隐含层参数(输入权值和偏置)在给定的区间内随机产生,只需解析求解网络输出权值。因RWNNs实现简单、建模速度快等优势受到了广泛的关注。设计了一种二维RWNNs分类器,用于人脸识别。
然而,随机权神经网络在处理大规模数据时仍然存在一些问题,如对于复杂数据的建模能力有限,准确度不够高等。为了克服这些问题,近年来学者们提出了一种新的模型与数据混合并行学习方法。该方法同时利用了随机权神经网络的快速学习能力和数据混合并行算法的高效性能,将二者相结合,实现了对大规模数据的快速、高效处理。
这种模型与数据混合并行学习方法的机理是这样的:首先,利用随机权神经网络的特点,将网络的隐含层参数随机初始化,然后采用数据混合并行算法,将大规模数据拆分成多个小批量,并行计算每个小批量数据的梯度并更新网络参数。通过不断迭代训练,逐渐优化网络参数,提高模型的准确度和泛化能力。
这种模型与数据混合并行学习方法在实际应用中取得了显著的效果。通过与传统神经网络算法进行对比实验,结果表明该方法在处理大规模数据时明显提升了模型的训练速度和准确度。同时,该方法还具有较好的可扩展性和适应性,可以灵活应用于不同领域的数据建模任务中。
总的来说,随机配置网络的模型与数据混合并行学习方法是一种有效应对大规模数据建模挑战的新型算法。它充分利用了随机权神经网络和数据混合并行算法的优势,结合了二者的特点,为数据建模领域带来了新的思路和方法。随着技术的不断进步和算法的不断完善,相信这种方法将在未来的应用中发挥重要作用,推动数据建模领域的发展。
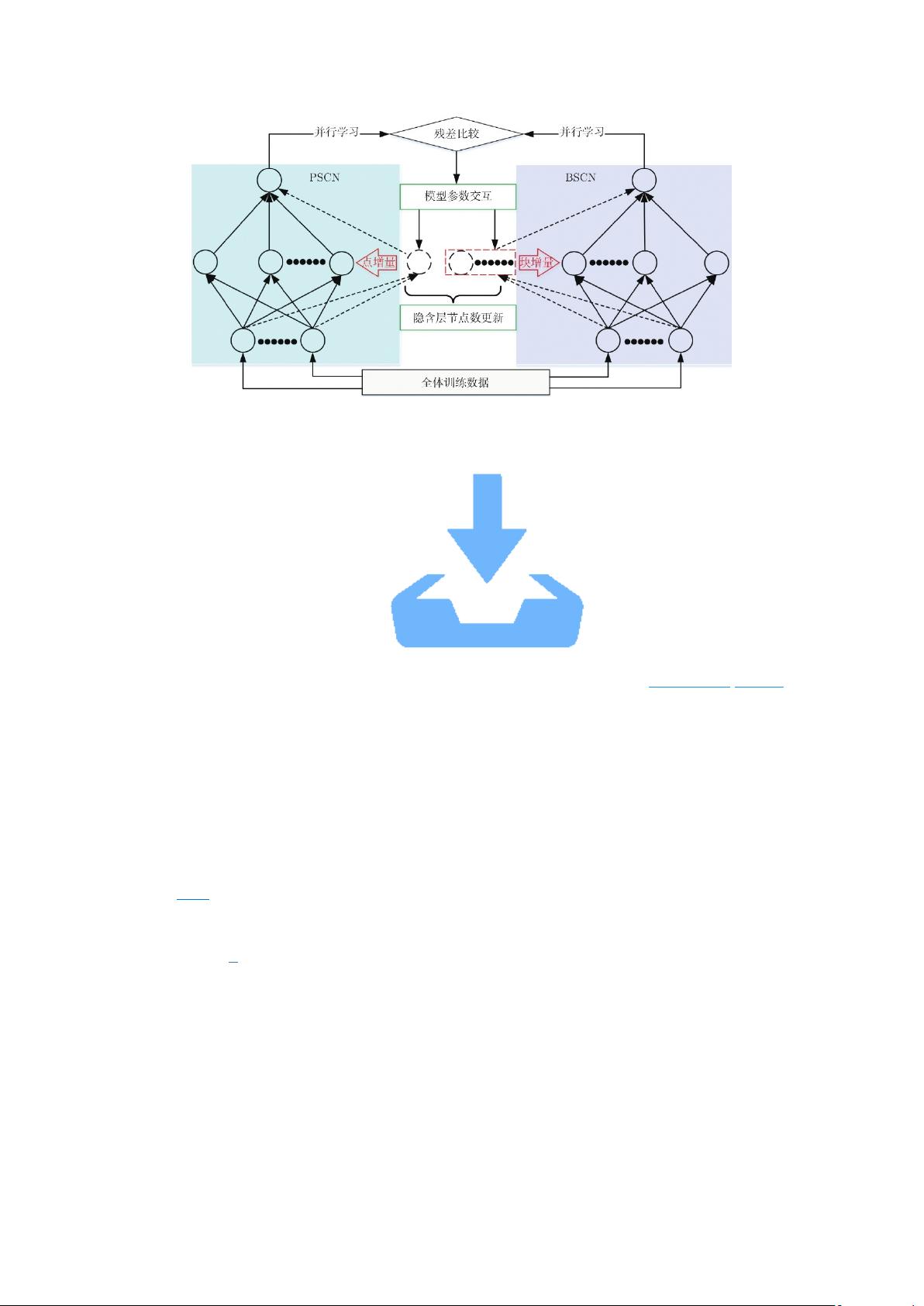
图 1 模型并行结构图
Fig. 1 The structure diagram of model parallelism
下载: 全尺寸图片 幻灯片
该策略采用平行网络并行计算. 即在增量学习过程中, 平行的 PSCN 与 BSCN 通过并
行计算被独立地构建; 每次迭代结束后, 以当前网络残差为指标, 保留其中较优的网络, 并
将其模型参数作为本次迭代的最终结果; 同时将该结果赋值给另一个网络以更新其节点数,
然后进行下一次迭代.
2.1.1 PSCN
图 1 所示的模型并行增量学习方法, 左侧采用传统点增量随机配置网络 PSCN, 其学习
过程约束根据引理 1 获得.
引理 1
[14]
. 令$ \Gamma :=\left\{ {{g_1},{g_2},{g_3}, \cdots } \right\} $表示一组实值函
数, $ {\rm{span}}(\Gamma ) $表示由$ \Gamma $组成的函数空间. 假设
$ {\rm{span}}(\Gamma ) $稠密于$ {L_2} $空间且$ \forall g \in \Gamma $, $ 0 < \left\| g \right\|
< {b_g} $, 其中${b_g} \in $$ {{\bf{R}}^ + }$. 给定$ 0 < r < 1 $以及非负实值序列
$\left\{ {{\mu _L}} \right\},$ 其中,$\mathop {\lim }\nolimits_{L \to \infty } {\mu
_L}=0,$ ${\mu _L} \le \left( {1 - r} \right).$ 对于 $ L =1,2,\cdots, $定义
$$ \delta _{L,q}^{}=\left( {1 - r - {\mu _L}} \right){\left\| {{\boldsymbol{e}}_{L - 1,q}^{}} \right\|^2}, q=1,2, \cdots ,m $$
(8)
若激活函数$ {{\boldsymbol{g}}_L} $满足下列不等式约束:
剩余20页未读,继续阅读
2023-02-24 上传
2023-06-10 上传
2023-05-30 上传
2023-05-31 上传
2023-05-31 上传
2023-05-31 上传
2023-09-04 上传

罗伯特之技术屋
- 粉丝: 4393
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
