GitHub上的机器学习与编程语言集成:解决兼容性问题的探索
版权申诉
21 浏览量
更新于2024-06-14
收藏 464KB DOCX 举报
"这篇文档探讨了在GitHub上集成机器学习模型到编程语言中对解决兼容性问题的影响。文章由Faten Slama、Imen Ismail和Lassaad Latrach共同撰写,他们均来自突尼斯的Manouba大学。关键词包括GitHub项目、文件扩展名、编程语言和机器学习。"
在当前的数字化时代,机器学习(ML)正逐渐融入各种领域,包括编程语言。GitHub作为一个全球最大的开源代码库,成为了开发者分享和协作的平台。文档指出,GitHub上的项目经常利用编程语言来自动化会计任务,如数据输入、计费和费用管理,同时也可能借助可视化工具清晰地展示财务数据,从而提升企业的效率并帮助做出更明智的财务决策。
然而,随着不同编程语言间的交互增加,兼容性问题成为了一个重要的挑战。当用一种编程语言编写的代码需要与其他语言的代码协同工作时,可能会出现不兼容的情况。这个问题在GitHub项目中尤为突出,因为开发者们常常需要将多种技术集成到一个项目中。例如,一个使用Python进行数据处理的项目可能需要与使用Java或JavaScript构建的前端界面进行交互。这种跨语言的集成可能会导致接口不匹配、库依赖冲突或者性能问题。
为了克服这些兼容性问题,文档可能详细阐述了以下几点:
1. **多语言接口设计**:开发者需要设计标准化的接口,使得不同语言之间可以无缝通信,如通过RESTful API或消息队列系统。
2. **语言桥接工具**:使用如Jython(Python的Java实现)或JSweet(将Java转换为TypeScript/JavaScript的工具)等工具,可以消除语言之间的障碍。
3. **容器化与微服务架构**:通过Docker等容器技术,每个服务都可以在其自己的环境中运行特定的编程语言,减少兼容性问题。
4. **版本管理和依赖管理**:利用Git等版本控制工具和包管理器(如npm、pip、maven),确保所有依赖项的版本协调一致。
5. **机器学习模型的封装**:将机器学习模型封装成可跨语言使用的库或服务,比如TensorFlow Serving支持多种语言的API。
6. **兼容性测试**:进行详尽的兼容性测试,确保不同语言和组件在各种场景下都能正常协作。
7. **社区与标准**:遵循开放标准和社区的最佳实践,如OpenAPI规范,可以帮助促进不同语言之间的互操作性。
该文档可能深入研究了GitHub上机器学习模型与编程语言集成的现状,分析了兼容性问题,并提出了相应的解决策略,对于理解和改进跨语言项目开发具有重要的参考价值。
Adv Mach Lear Art Inte, 2023
Volume 4 | Issue 2 |80
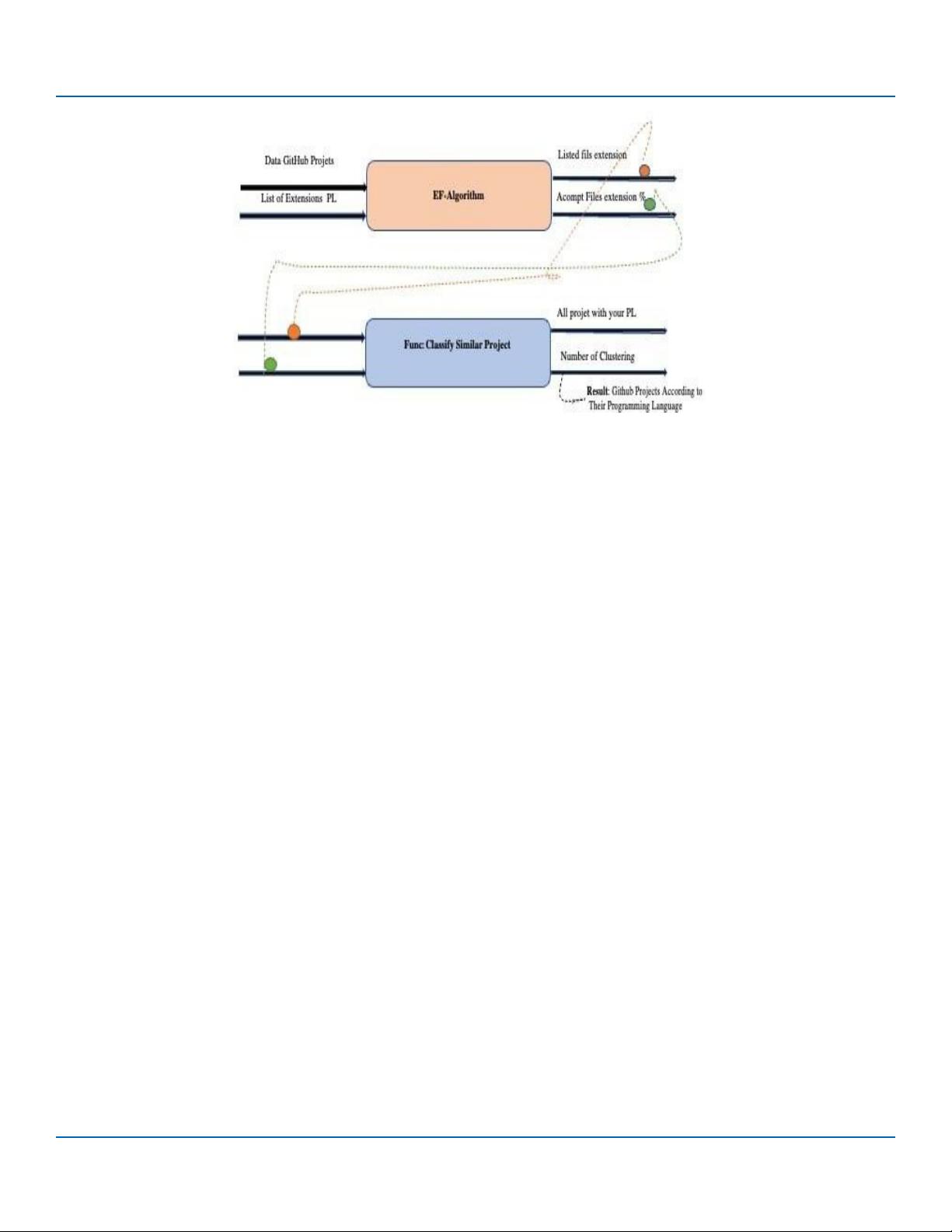
Figure 2: Requirements Generalization Process
This image shows a set of files with different extensions (“.java”,
“.py”, “.mp3”, etc). A classification algorithm is used to group
the files into different categories based on their extension. For
example, the “.java” files are grouped into the “Java” category, the
“.py” files are grouped into the “Python” category, and the “.mp3”
files are grouped into the “audio” category.
The project title does not always provide the program type index
to be used.
The algorithm can be trained on a dataset of labelled files to learn to
predict the category of a file based on its extension. Once trained, it
can be used to classify new files based on their extension.
This image is a simplified representation of classifying files by
their extension, and the details of the implementation may vary
depending on the data and the algorithm used. If you are interested
in implementing this approach, I would recommend consulting a
machine-learning expert or doing further research on the topic.
This new framework has been successfully applied to a real
database containing more than a hundred projects with various
extensions. The results obtained After that, we use the FE of each
PL, then extension-based segmentation to find the most used
language. Finally, we use techniques to analyse GitHub projects.
In this article, we will further detail this new method and we will
describe and explain the obtained results.
When you have a set of unlabelled data, it’s very likely that you’ll
be using some kind of unsupervised learning algorithm. So, we
choose K-means clustering because it is the most commonly
used clustering algorithm. It’s a centroid-based algorithm and the
simplest unsupervised learning algorithm. This algorithm tries to
minimize the variance of data points within a cluster. It’s also how
most people are introduced to unsupervised machine learning.
K-means is best used on smaller data sets because it iterates over
all of the data points. That means it’ll take more time to classify
data points if there are a large amount of them in the data set. Since
this is how we implement the method EF to k-means clusters and
facilitate the use of the application GitHub.
There are several ways to categorize GitHub projects by
programming language. One of the most popular methods is to use
GitHub’s search functionality to look for projects using keywords
associated with various programming languages. For instance,
you can search for Python-based projects by using keywords like
“Python,” “Django,” or “Flask.” Additionally, there are tools like
GitHub Trends that allow you to view the trends of the most well-
liked projects according to programming languages. There are also
third-party services like GitHub Language Statistics, which allows
you to view the language statistics for all of GitHub’s open-source
projects. There are visualization tools available that will allow
you to see the trends of programming languages used on GitHub.
Additionally, data analysis tools exist that can be used to extract
information about GitHub projects based on the programming
language they use. GitHub projects can be efficiently imitated
through the site’s fork process or through a Git clone-push sequence
and improve the quality of GitHub project samples that are utilized
to conduct empirical software engineering studies [1]. This work
surveys the recent attempts, both from the machine learning and
operations research communities, at leveraging machine learning
to solve combinatorial optimization problems [1].
Given the hard nature of these problems, state-of-the-art
algorithms rely on handcrafted heuristics for making decisions
that are otherwise too expensive to compute or mathematically not
well-defined. In recent years, the development of machine learning
has led to augmentations of automated tools that classify or extract
information in GitHub [2]. The research works on classification in
GitHub have been still in the passage of development, primarily
engrossed in the submitting, reviewing, and evaluation process.
To recommend experts for the development of AI and machine
剩余16页未读,继续阅读
2023-04-05 上传
2024-01-21 上传
2023-09-22 上传
2024-01-20 上传
2024-04-03 上传
2024-01-22 上传
2023-03-30 上传

百态老人
- 粉丝: 5110
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
