Python+PyCharm+Scrapy:快速构建网站爬虫项目指南
 已收录资源合集
已收录资源合集
需积分: 0 197 浏览量
更新于2024-08-04
收藏 190KB DOCX 举报
本文档主要介绍了如何使用Python、PyCharm以及Scrapy框架来搭建一个爬虫项目。首先,我们先来了解Scrapy的基本概念。
Scrapy是一个强大的Python爬虫框架,专为高效地抓取网站数据和结构化数据设计,适用于数据挖掘、信息处理和存储历史数据等各种应用场景。其工作流程主要包括ScrapyEngine(引擎)、Scheduler(调度器)、Downloader(下载器)和Spider(爬虫)四个核心组件,以及可扩展的ItemPipeline(数据处理管道)和Middleware(中间件)。Scrapy的工作原理是通过这些组件协同工作,实现对目标网站的自动抓取和数据提取。
在进行实际操作前,你需要确保已安装Python 3.x版本,并且安装了PyCharm Community版,Scrapy框架可以通过pip工具轻松安装。安装完成后,可以使用scrapystartproject命令创建一个新的Scrapy项目,例如名为"WebScraping"的项目。创建的项目结构包括一个与项目名称相同的包、一个scrapy.cfg配置文件以及其他必要的文件。
以下是详细的搭建步骤:
1. **安装环境**:
- 安装Python 3.x: 这是基础,确保Python环境正常运行。
- 下载并安装PyCharm Community: PyCharm是一个流行的集成开发环境,提供良好的代码编辑和调试支持。
- 安装Scrapy: 在命令行中输入`pip install scrapy`来完成Scrapy框架的安装。
2. **创建项目**:
- 打开命令行,输入`scrapy startproject [项目名称]`,比如`scrapy startproject WebScraping`,这将在当前目录下生成一个名为"WebScraping"的Scrapy项目。
- 查看项目结构:项目会包含一个名为"WebScraping"的Python包,以及一个scrapy.cfg配置文件,这个文件用于配置项目的全局选项。
3. **理解项目结构**:
- 包含在WebScraping包下的文件主要有:__init__.py(初始化文件)、settings.py(配置文件)、spiders(存放Spider的子目录)、items.py(定义Item模型)、pipelines.py(定义ItemPipeline)、middlewares.py(定义中间件)、templates(模板文件,通常用于自定义输出)以及start_urls(初始爬取URL列表)。
4. **编写爬虫**:
- 在spiders子目录下创建一个新的Python文件,例如my_spider.py,编写Spider类,继承自Scrapy.Spider。在该类中定义start_requests()方法,生成需要爬取的初始请求,并在parse()方法中解析响应数据,提取所需信息,并调用yield Request()函数向其他URL发送请求。
5. **配置中间件**:
- 如果需要自定义下载或爬虫中间件,可以在middlewares.py中创建相应的类,遵循Scrapy的规则。下载中间件处理下载过程中的操作,而Spider中间件则涉及爬虫和调度器之间的通信。
6. **配置和运行**:
- 在scrapy.cfg中,可以调整默认设置以适应项目需求,如下载限制、下载代理等。启动爬虫时,可以在命令行中使用`scrapy crawl [spider_name]`,其中[spider_name]是你定义的Spider的名字。
通过以上步骤,你就可以在PyCharm环境中使用Scrapy搭建并运行一个基本的爬虫项目,对目标网站进行数据抓取和处理。根据实际需求,你可以继续扩展和定制Scrapy框架,使其满足更复杂的爬虫任务。
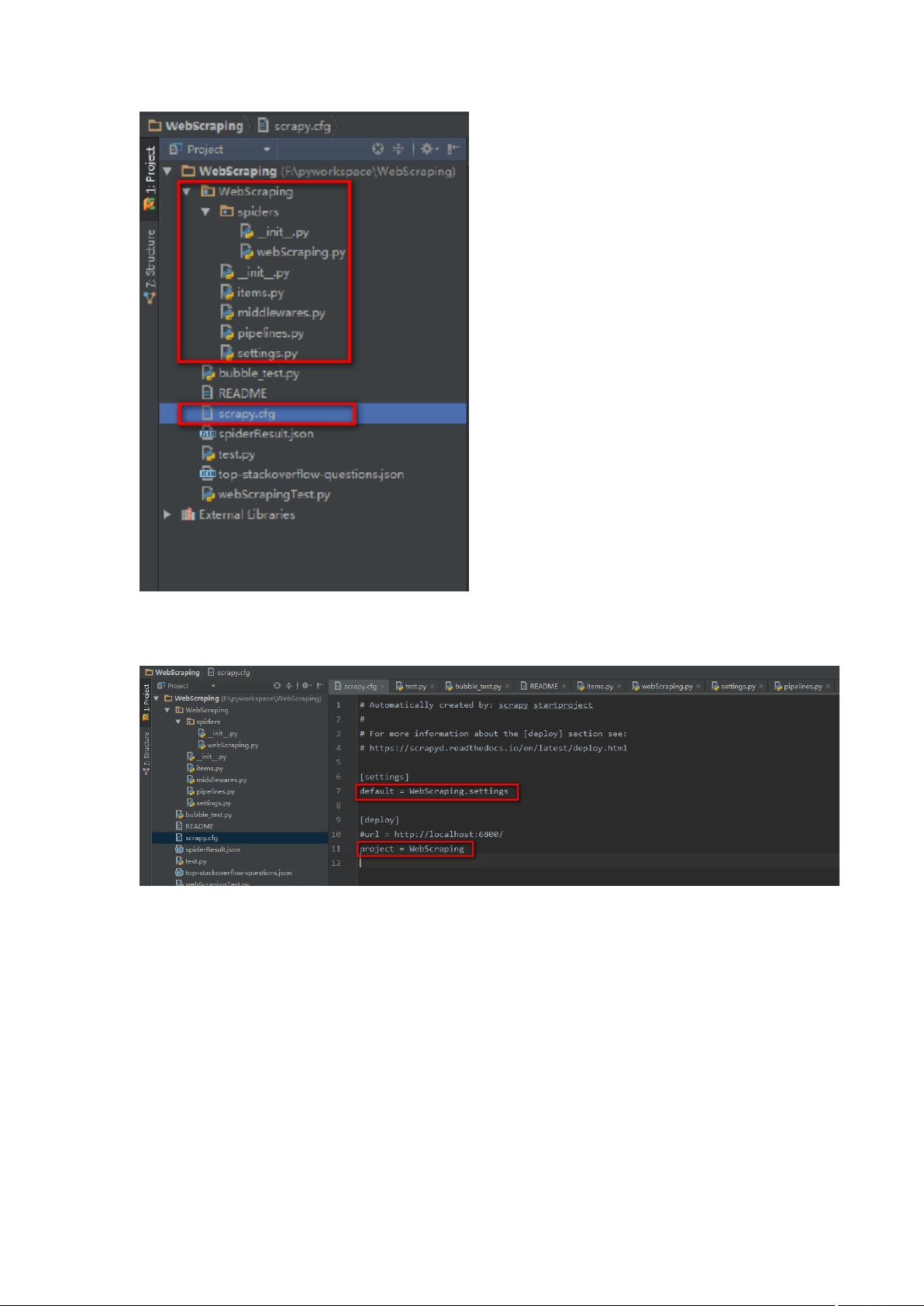
①WebScraping项⽬根⽬录下包括⼀个同名的WebScraping包和⼀个scrapy.cfg配
置⽂件;其中scrapy.cfg配置⽂件内容如下:
指定该scrapy项⽬的setting⽂件为WebScraping包下的settings.py⽂件
②scrapTest模块下⼜包含了items、middlewares、pipelines、settings模块以及spi
der包
(1)
items模块中定义了items类,各items类必须继承scrapy.Item;通过scrapy.Field()
定义各Item类中的类变量
import scrapy
class StockQuotationItem(scrapy.Item):
'''
'''
order=scrapy.Field()
symbol = scrapy.Field()
instrument_name = scrapy.Field()
price=scrapy.Field()
剩余12页未读,继续阅读
2023-05-04 上传
159 浏览量
272 浏览量
126 浏览量
2021-11-23 上传
2023-09-10 上传
2022-06-12 上传
2021-06-09 上传
468 浏览量

sun7bear
- 粉丝: 1
- 资源: 121
 我的内容管理
展开
我的内容管理
展开







