企鹅数据集决策树实战:分类与可视化分析
版权申诉
18 浏览量
更新于2024-08-03
收藏 321KB DOCX 举报
"这篇文档是关于使用决策树算法对企鹅数据集进行分析的实战教程。数据集包含有关不同企鹅物种的信息,如喙长、喙深、鳍长和体重等,目标是根据这些特征来区分企鹅种类。"
在这个实战项目中,我们将通过以下步骤了解如何使用Python的数据分析工具来构建和应用决策树模型:
1. **库函数导入**:
首先,我们需要导入必要的库,包括`numpy`用于数值计算,`pandas`用于数据处理,以及`matplotlib`和`seaborn`用于数据可视化。这些库是数据科学项目中的基础工具,它们帮助我们加载、操作和展示数据。
2. **数据读取/载入**:
使用`pandas`的`read_csv`函数读取CSV文件,将数据加载到DataFrame对象中。这里假设数据集存储在本地路径`D:\算法作业\penguins_raw.csv`。
3. **数据预处理**:
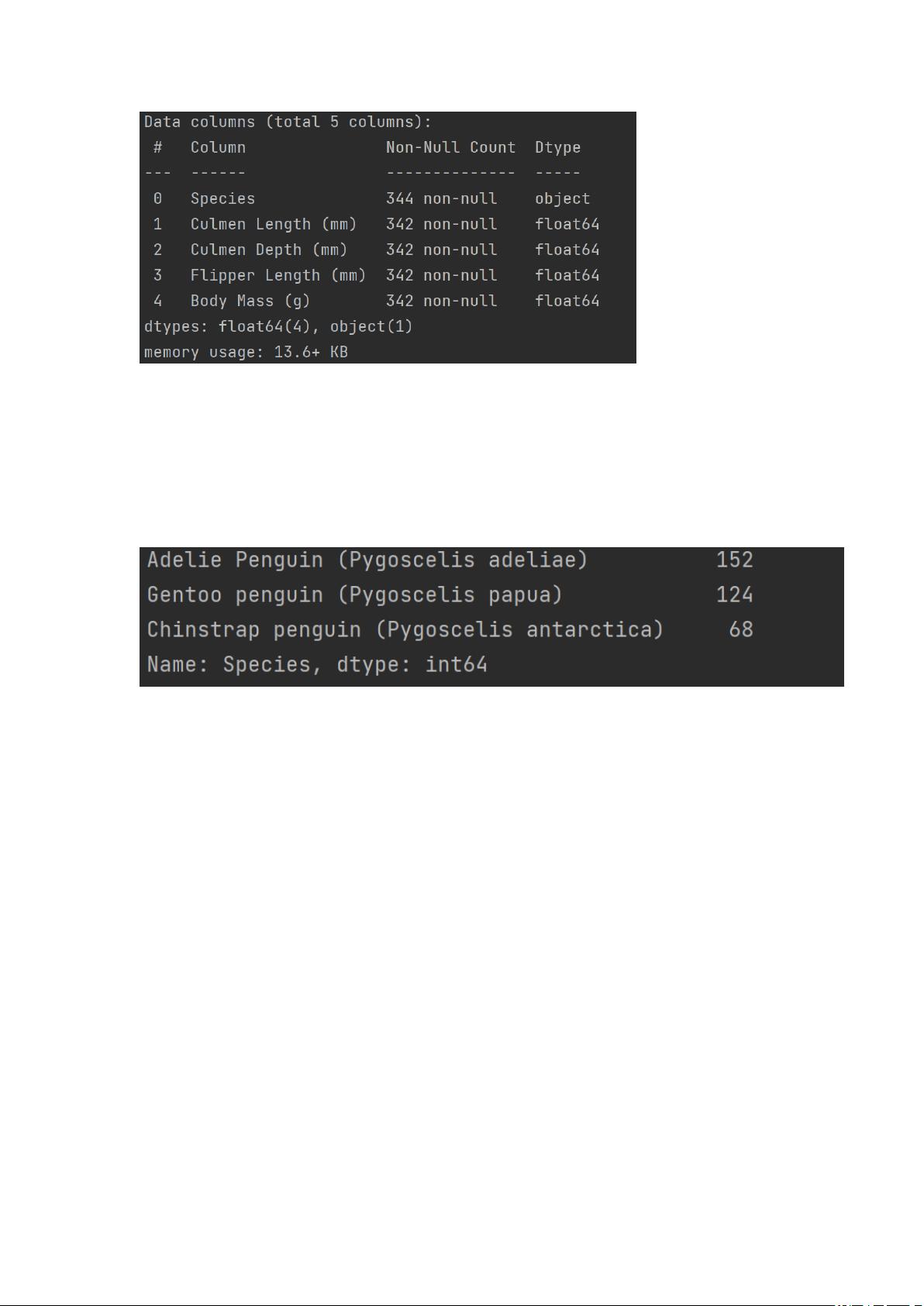
- `data.info()`显示数据的基本信息,包括列名、非空值数量等。
- 使用`fillna`方法将缺失值填充为-1,以便后续处理。
- 利用`value_counts`查看'Species'(企鹅种类)这一类别特征的数量,有助于理解数据分布。
4. **数据可视化**:
- `pairplot`函数创建了一个散点图矩阵,展示数据集中选定特征之间的关系,同时按'Species'分组,使用直方图作为对角线上的分布。这有助于我们初步探索特征间的关系以及不同企鹅种类的分布差异。
- 使用`boxplot`对各个特征进行箱型图绘制,按'Species'分类,这样可以直观比较不同物种在各特征上的统计特性。
5. **特征工程**:
- 为了使分类特征'Species'能够适用于数值计算,我们需要将其转换为数字表示。这里定义了一个`translate`函数,将'Species'的每个唯一值映射到0、1、2等整数。
- 应用`translate`函数转换所有'Species'值,并使用`apply`方法将其应用于数据框。
6. **构建决策树模型**:
未在提供的内容中详细描述,但通常接下来的步骤会包括划分数据集为训练集和测试集,选择合适的决策树模型(如`sklearn`库中的`DecisionTreeClassifier`),拟合模型,然后在测试集上评估模型性能。这可能涉及调整决策树的参数,如最大深度、最小叶子节点样本数等,以优化模型的准确性和泛化能力。
7. **模型评估**:
最后,使用评估指标(如精度、召回率、F1分数或混淆矩阵)评估模型的性能,并可能进行特征重要性分析,以了解哪些特征对决策树的预测最为关键。
通过这个实战项目,我们可以学习到如何使用Python进行数据预处理、特征工程、模型构建以及结果评估,这些都是数据科学项目中的核心技能。同时,决策树作为一种解释性强的模型,有助于我们理解企鹅特征与种类识别之间的关系。
data = data.fillna(-1)# 将缺失值补全
## 利用 value_counts 函数查看每个类别数量
print(pd.Series(data['Species']).value_counts())
Step4:可视化描述
仅从数据集中选择了几个特征
data = data[['Species','Culmen Length (mm)','Culmen Depth (mm)',
'Flipper Length (mm)','Body Mass (g)']]
sns.pairplot(data=data, diag_kind='hist', hue= 'Species')
plt.show()
剩余11页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-05 上传
2023-03-01 上传

ohmygodvv
- 粉丝: 507
- 资源: 4811
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
