卷积层硬件实现与优化技术探析
需积分: 10 94 浏览量
更新于2024-07-16
收藏 3.03MB PDF 举报
"卷积层硬件实现和优化方法——卜居.pdf"
本文主要探讨了卷积神经网络(CNN)中的卷积层的硬件实现和优化技术,由阿里巴巴云计算有限公司的赵永科撰写。文档涵盖了从基本的卷积计算原理到各种实现方法,包括直接实现、Caffe框架的实现、快速傅里叶变换(FFT)实现、CUDNN库的利用,以及FPGA硬件加速等。此外,还介绍了针对这些方法的优化策略。
首先,卷积层是CNN的核心组件,它通过卷积操作对输入特征图进行处理。卷积定义为两个函数的乘积积分,通常在CNN中,卷积是3D或4D张量的操作。前向传播时执行卷积,反向传播时执行相关的运算。卷积层由多个滤波器(权重)对输入特征图进行滑动并产生输出特征图,每个滤波器通常有固定大小(如KxK),并覆盖整个输入图。对于多通道输入,每个滤波器都会对每个通道进行卷积。
直接实现方法是最基础的卷积计算方式,通过循环遍历每个输出像素位置,逐个应用滤波器权重进行计算。例如,对于一个具有通道数为 channels,输出特征图维度为 num_output,输入特征图尺寸为 HxW,滤波器尺寸为 KxK的卷积层,直接实现会涉及到大量的乘加运算。这种方法计算量大,效率较低,但在理解卷积运算的底层逻辑时非常有用。
Caffe是一种广泛使用的深度学习框架,它提供了高效的卷积层实现。Caffe通过优化的内存管理和计算流程,大大加快了卷积计算的速度,适用于大规模数据的训练和推理。
FFT方法则是利用快速傅里叶变换的特性来加速卷积运算,尤其是当滤波器尺寸较大时。FFT将卷积转换为点乘,从而降低了计算复杂度。然而,FFT方法在处理小尺寸滤波器时可能不如直接方法有效。
CUDNN是NVIDIA开发的深度学习库,专为GPU优化,特别适用于处理卷积层。它利用了GPU的并行计算能力,提供了多种卷积算法,如通过直接卷积、FFT和Winograd算法,自动选择最优策略,进一步提高了性能。
FPGA(现场可编程门阵列)硬件实现则允许对卷积层进行定制化硬件加速。FPGA相比于GPU有更高的灵活性,可以根据特定的卷积网络结构进行硬件配置,从而达到更高的能效比。但FPGA的设计和实现相对复杂,需要专门的硬件设计知识。
最后,优化策略是提高卷积层效率的关键。这可能包括使用更有效的数据布局、优化内存访问模式、减少计算冗余、并行化处理、量化和剪枝等技术。这些策略旨在减少计算量,提升计算速度,降低功耗,同时保持模型的准确度。
理解和优化卷积层的硬件实现对于构建高性能的深度学习系统至关重要,尤其是在资源受限或需要实时处理的场景下。通过选择合适的实现方法和优化策略,可以极大地提升CNN的运行效率,为AI应用提供更强的计算支持。
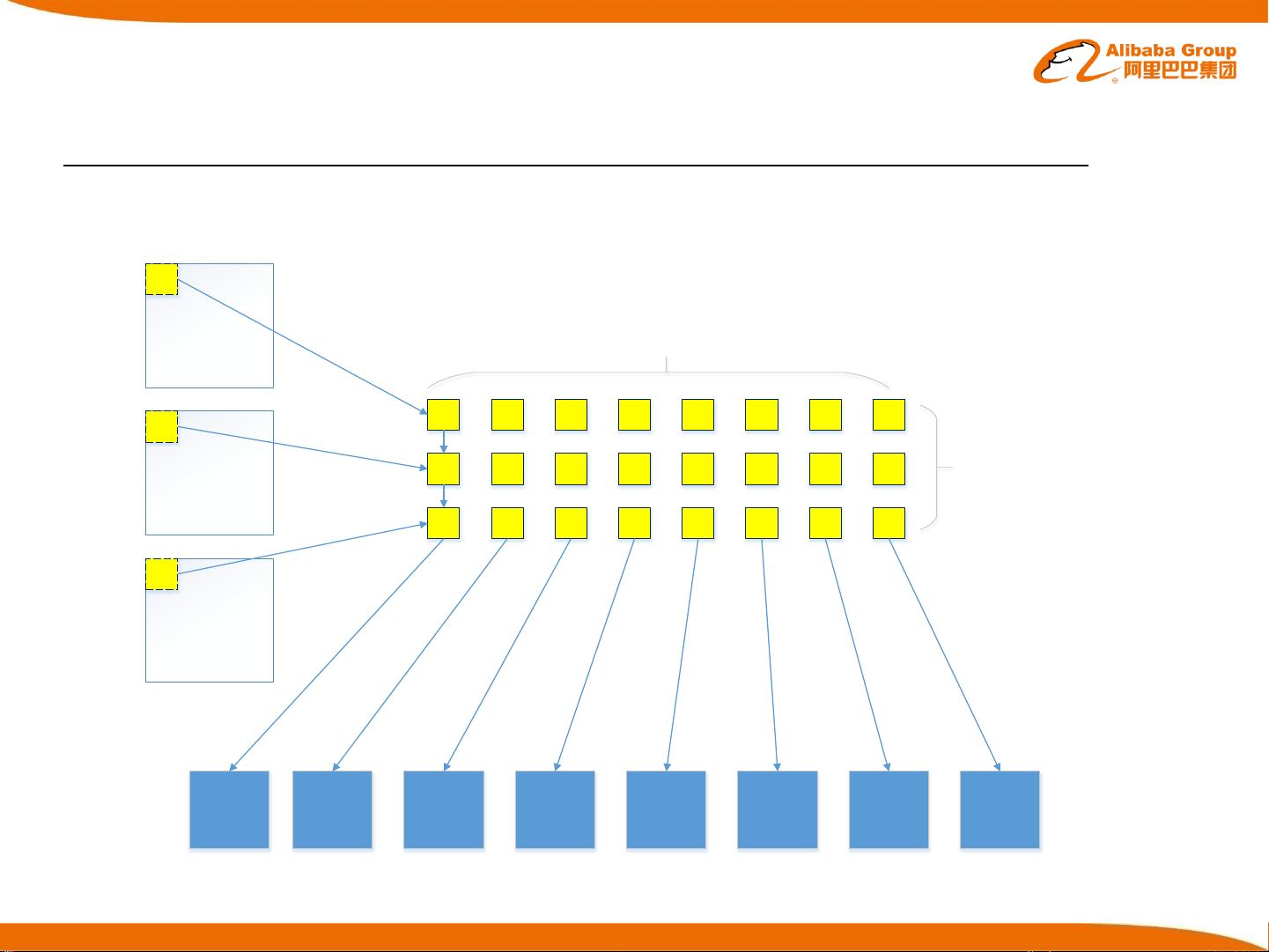
Caffe实现方法
思路:转化为GEMM问题
第8页
Input feature map #1
Input feature map #2
Input feature map #3
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
KxK
Output feature
map #1
Output feature
map #2
Output feature
map #3
Output feature
map #4
Output feature
map #5
Output feature
map #6
Output feature
map #7
Output feature
map #8
channels=3
num_output=8
H
W
HO
WO
剩余44页未读,继续阅读
2021-12-03 上传
2021-12-03 上传
2021-08-31 上传
2019-12-27 上传
2021-02-23 上传
2024-03-09 上传
2021-09-25 上传
2022-11-18 上传
2021-09-26 上传

SoldierSir
- 粉丝: 0
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
