Elasticsearch 7.3 Logstash插件详解:input、filter与output实战
版权申诉
164 浏览量
更新于2024-08-06
收藏 471KB DOC 举报
本文档主要介绍了Elasticsearch 7.3的学习教程,重点讲解了Logstash的三大核心组件:input、filter和output。Logstash是一个强大的日志管理和数据处理工具,它允许用户从各种数据源收集、转换和输出数据,以便于整合到Elasticsearch中进行存储和分析。
1. **Logstash输入插件**
- 输入插件是Logstash的第一步,支持多种数据源,如file(文件)、http(HTTP请求)、jdbc(数据库连接)和s3(Amazon S3)。Logstash提供了丰富的输入选项,可以根据具体需求选择适合的数据源。
- **标准输入(Stdin)**:允许从控制台接收实时输入,已在前文中简要介绍过。
- **读取文件(File)插件**:用于读取本地文件,例如`nginx1.log`,支持通配符匹配多文件,并且可以设置从文件开头或末尾开始读取。默认情况下,Logstash使用`filewatch`库监控文件变化,记录读取进度到`.sincedb`文件中。
2. **过滤器(filter)**
- 过滤器环节对从输入插件获取的数据进行处理和转换,如数据清洗、格式调整、字段操作等,但这部分内容在提供的部分并未详细说明,通常包括grok(用于解析日志格式)、date(处理时间戳)、geoip(地理位置信息提取)等插件。
3. **输出(output)**
- 输出插件负责将处理后的数据发送到目标,如Elasticsearch、Kafka、RabbitMQ等。文档中的例子展示了如何将数据输出到控制台(stdout),并使用`rubydebug` codec进行调试格式化。
4. **实时更新文件和持续监控**
- 在实际环境中,Logstash能够实时监测文件系统的变化,比如新产生的日志条目,它会自动检测并处理这些新增数据,保持与文件的同步。这依赖于`filewatch`库和`.sincedb`文件记录的文件读取位置。
总结来说,本篇文档提供了一个关于Logstash在Elasticsearch 7.3中的应用示例,着重展示了如何配置input插件来读取不同类型的输入源,如何使用filter进行数据处理,以及如何通过output将数据输出到目标,包括文件监控和实时更新功能。通过学习这些基础知识,读者可以更好地理解和使用Logstash进行日志管理与数据管道构建。
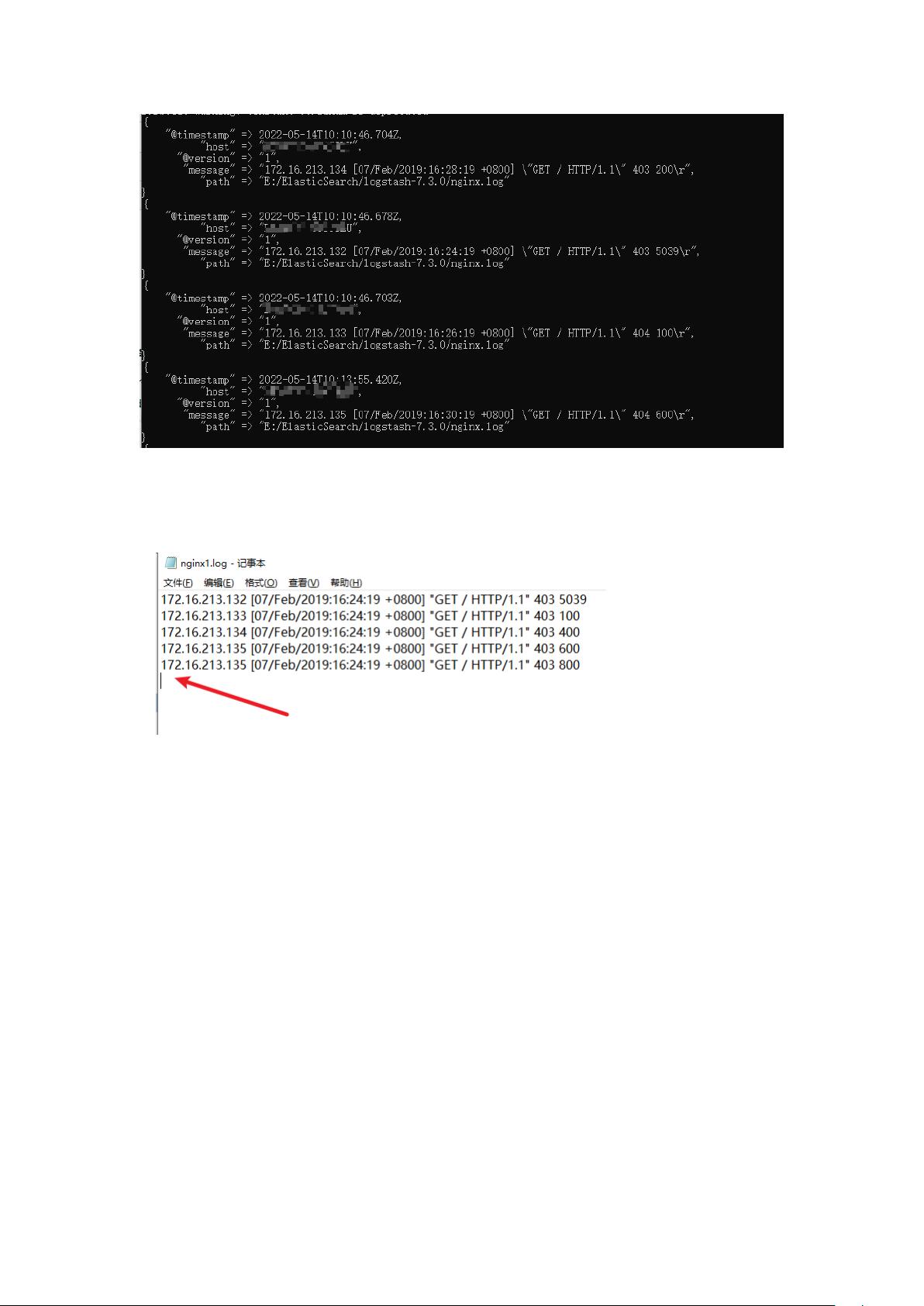
1.4 实时更新文件
假如说我们往 nginx1.log 下新增加一条数据,看下效果
在生产环境下,服务一直在运行,日志文件一直在增加,logstash 会自动读取新增的数据
剩余13页未读,继续阅读
335 浏览量
235 浏览量
182 浏览量
2024-10-24 上传
118 浏览量
235 浏览量
2021-05-10 上传
248 浏览量
2021-04-12 上传

书博教育
- 粉丝: 1
- 资源: 2837
 我的内容管理
展开
我的内容管理
展开







最新资源
- teacheruz:乌兹别克斯坦地方大学的学生管理系统
- dbdot:为postgres db模式生成DOT描述
- facebook-rockin-最佳自动化-selenium-scrape-no-api-tool-bot-machine-made-to-destroy-facebook:Facebook自动化:登录,喜欢,共享,评论,发布,删除。 包含视频“实际中”。 目的主要是通过在Fakebook平台中填充垃圾内容来破坏Fakebook平台(例如,当您决定离开所有这些Fcking平台时,在其中自杀)。 请安装,测试并提交您自己的改进和功能! 谢谢!
- Trigger
- 意法半导体ST_LinkV2.7z
- banking_app_angular
- kiosk_system_rpi3:Raspberry Pi 3的Nerves QtWebEngine信息亭系统
- Tribeca
- springboot-guide:Not only Spring Boot but also important knowledge of Spring(不只是SpringBoot还有Spring重要知识点)
- maven及其maven本地仓库
- SecretSanta2020:秘密圣诞老人游戏Jam 2020的游戏
- WWH21:我的winterwonderhack2021项目
- assertj-bean-validation:Bean验证的AssertJ扩展
- pytesseract:Google Tesseract的Python包装器
- FifaOnline4Api
- Triadxs
