Python爬虫入门与实战:requests与BeautifulSoup详解
Python爬虫是一门实用的技能,它涉及到通过编程方式自动访问、抓取并处理网站上的数据,特别是在大数据时代,对于数据采集和分析具有重要作用。在这个课程中,主要讲解了Python在网络爬虫领域的基础知识和技术应用,以BIT-1001870001 MOOC课程为例,涵盖了以下几个核心知识点:
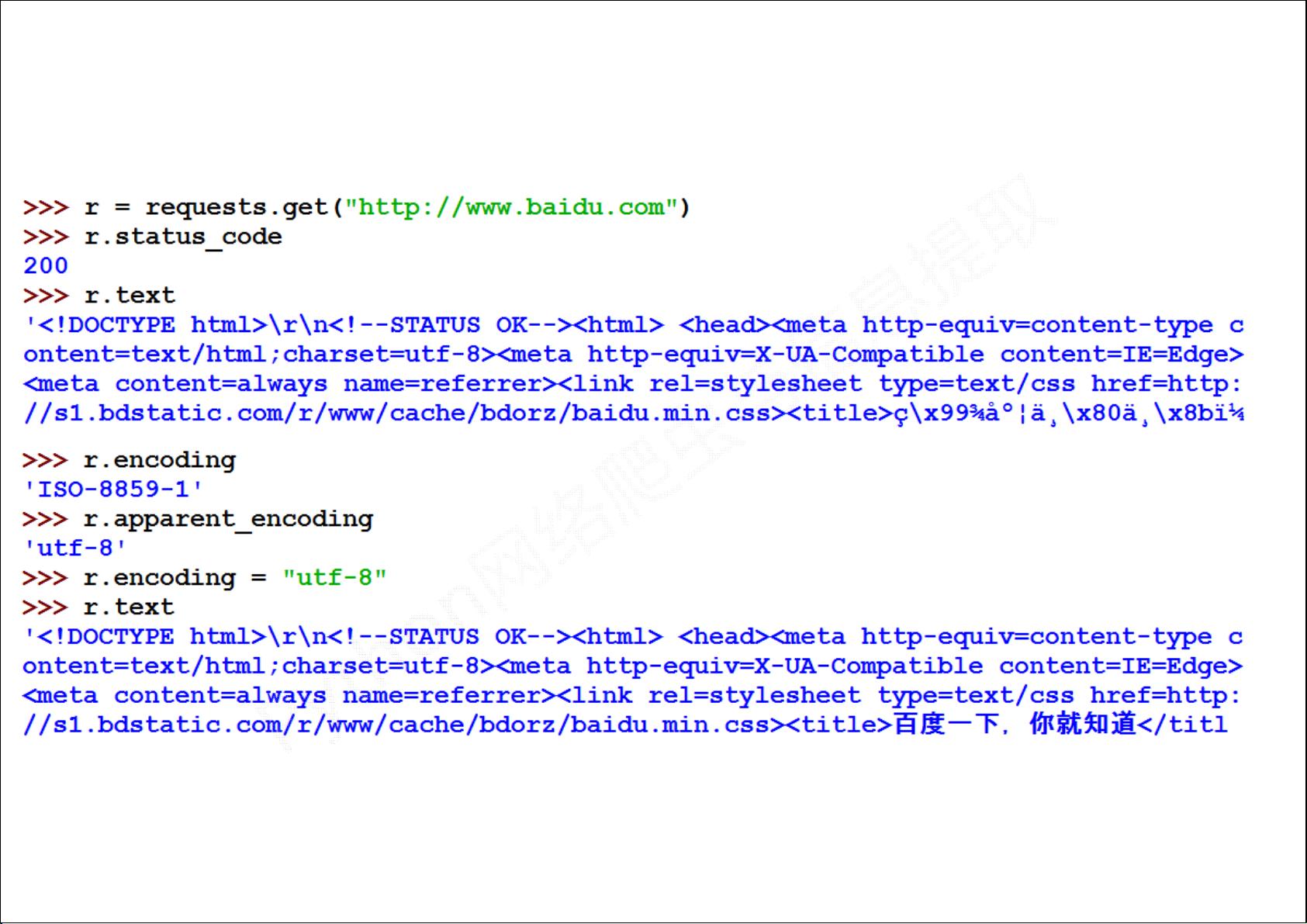
1. **基础爬虫技术**:课程从理解网络爬虫的工作原理开始,介绍如何通过编程实现自动爬取HTML页面,这涉及到利用requests库进行网络请求,如GET、POST等方法的使用。requests库是Python中常用的网络请求库,它的requests.get()方法是获取网页内容的常用手段。
2. **Robots.txt的理解**:课程提到了robots.txt文件,这是网站所有者制定的规则,用于告知爬虫哪些部分可以抓取,哪些禁止抓取,遵循这些规则能避免对网站造成不必要的负担。
3. **正则表达式详解**:正则表达式是解析和处理文本数据的强大工具,通过学习和应用正则表达式,能够更精确地提取页面的关键信息,如特定模式的数据。
4. **解析HTML页面**:课程讲解了如何使用BeautifulSoup库解析HTML文档,这是一个非常流行的网页解析库,能够方便地从HTML中提取结构化的数据。
5. **实战项目**:课程包含多个实战项目,如京东、亚马逊商品页面的爬取,搜索引擎关键字提交,网络图片的抓取和存储,以及IP地址归属地查询等,这些都是实际操作中常见的应用场景,有助于提升学员的实战能力。
6. **专业爬虫框架**:Scrapy作为专业的爬虫框架被提及,它提供了更高级的功能,如分布式爬虫、中间件处理、数据存储等,适合构建更复杂、可扩展的网络爬虫系统。
7. **信息提取与定向爬取**:课程强调了定向网络数据爬取的重要性,即根据具体需求选择性地抓取所需数据,同时培养学员处理网页解析的能力。
8. **课程结构**:全课程共分为8个内容单元和4个实例单元,每周安排3个单元,课程内容丰富且结构合理,既有理论知识讲解也有实践操作。
通过这个Python爬虫课程,学员将全面掌握基础到进阶的网络爬虫技能,包括但不限于HTTP请求方法、数据提取技巧、使用Python库以及设计和实施实际爬虫项目的技巧。这不仅适用于个人学习,也对数据分析师、开发者或任何需要大量网络数据的人士非常有价值。

2022-06-22 上传
2020-04-09 上传

QLMX
- 粉丝: 110
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- snake-js:带有Javascript和HTML5的Snake
- badges-and-schedules:熨斗学校实验室
- ArtCenterGame
- mywonkysounds:SoundManger 2 音板! 我的声音!
- birdinginvermont.com
- Usso:sso统一登录系统
- Design-Algorithm-Homework
- MonadicRP:GHC Haskell中的相对论编程
- monolithic-sample
- vue-shop:Vue + Element UI电商后台管理系统演示
- Neurotypical-mode:一种Chrome扩展程序,可关闭除Microsoft Stream或Manaba之外的所有选项卡
- observ-conference:实验
- module-blog-graph-ql:Magento 2 Blog GraphQL扩展。 为Magefan博客模块提供GraphQL端点
- Excel模板00现金日记账.zip
- Naive-Bayes-Classifier
- SmartFactory
