Hadoop深度解析:HDFS与MapReduce详解及其应用
需积分: 10 7 浏览量
更新于2024-07-28
收藏 809KB PDF 举报
Hadoop是一个开源的大数据处理框架,它主要由两个核心组件Hadoop Distributed File System (HDFS) 和 MapReduce 构成,用于处理大规模分布式数据。本文将详细介绍这两个关键部分。
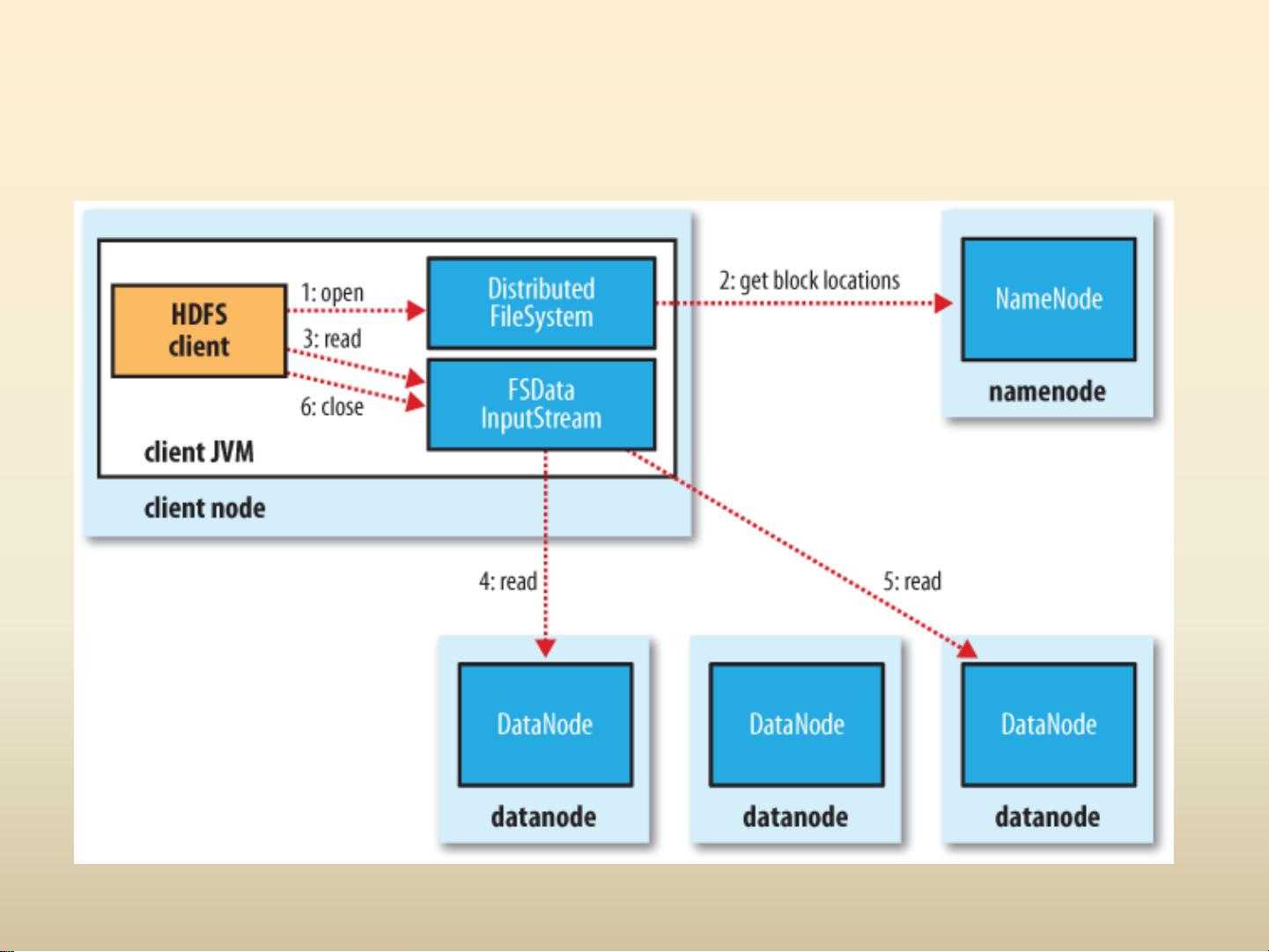
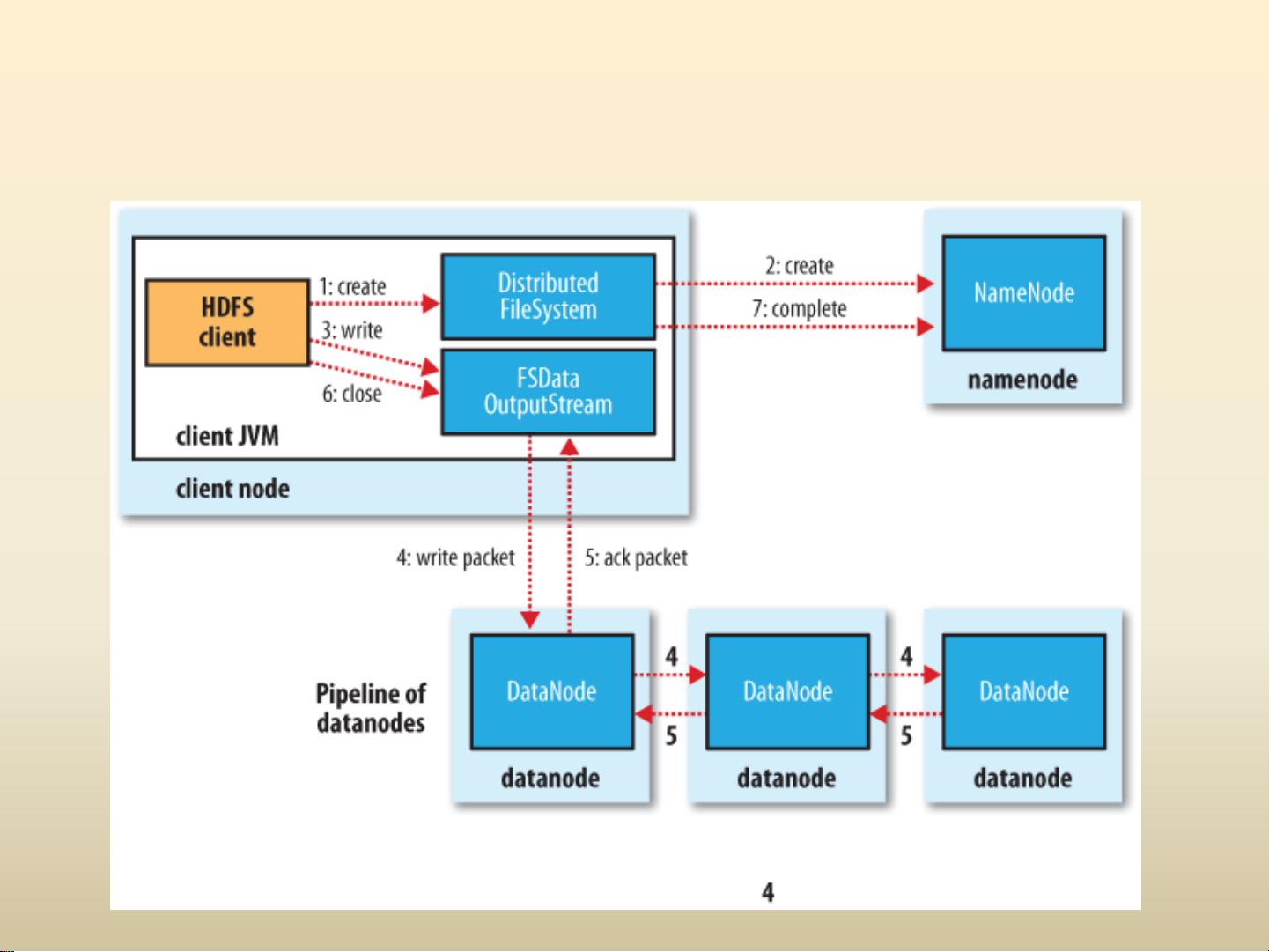
HDFS是Hadoop的核心组成部分,它设计用于存储超大文件,尤其适合批量处理而非实时交互。HDFS的主要理念是将大文件分解为固定大小(如64MB或128MB)的块,并在多个节点上复制存储,以实现数据的冗余和容错性。Namenode是HDFS的中心管理器,负责维护文件系统的命名空间和块的元数据,而Datanode则是存储实际数据块的节点。当Datanode发生故障时,HDFS会自动检测并从其他副本恢复数据。访问HDFS的方式多样,包括Java API、Thrift服务、C库以及Fuse模块,同时也提供了HTTP和WEBDAV等接口供不同场景使用。
MapReduce则是一个分布式计算模型,用于在Hadoop集群中执行并行任务。它将复杂的计算任务分解为一系列小任务(map任务)和合并结果的任务(reduce任务),通过多台机器的协同工作来加速数据处理。这个模型简化了编程模型,用户只需编写mapper和reducer函数即可,无需关心底层的并发细节。MapReduce适用于各种数据处理任务,如数据清洗、聚合、分类等。
Hadoop的扩展包括HBase和Pig/Hive。HBase是一个基于HDFS构建的分布式列式存储系统,用于处理大规模的结构化和半结构化数据,提供高扩展性和性能。Pig是一种基于Hadoop的数据流语言,它允许用户以接近自然语言的方式编写数据处理任务,而Hive则是一个数据仓库工具,提供SQL-like查询接口,使得数据分析更为便捷。
总结来说,Hadoop通过HDFS提供高效、容错的分布式文件存储,结合MapReduce实现了大规模数据的并行处理,而Hadoop的扩展组件如HBase、Pig和Hive则进一步增强了其在数据存储、处理和分析方面的功能。这些组件共同构成了一个强大的大数据处理平台,广泛应用于企业级的数据处理场景。

HDFS:访问接口
• Java客户端:Java API
• 非java客户端:Thrift服务
• C客户端:通过系统提供的C库,libhdfs。
• Filesystem in Userspace(Fuse):Hadoop提供了Fuse-
DFS模块,实现对HDFS的挂载和标准化访问
• HTTP接口:只读访问
• WEBDAV:对HTTP的扩展,支持对文件的编辑、hdfs文
件挂载和标准化访问,处于开发阶段
• FTP接口:使用FTP协议与HDFS进行交互,处于开发阶
段
剩余45页未读,继续阅读
199 浏览量
382 浏览量
2024-06-28 上传
123 浏览量
366 浏览量
226 浏览量









