Flink流处理与SQL:挑战与优化
需积分: 10 189 浏览量
更新于2024-07-17
收藏 631KB PDF 举报
"FlinkForwardChina2018FlinkStreamingSQL2018.pdf"
本文档主要探讨了Apache Flink中的流处理SQL(Streaming SQL)的相关知识,由Piotr Nowojski在Flink Forward China 2018大会上进行分享。内容涉及为何选择SQL,流处理SQL面临的挑战,以及不同类型的表连接方法,如归并连接算法和哈希连接算法,并介绍了模式识别和最近的改进。
为何选择SQL?
SQL是结构化查询语言,因其易用性和声明性而被广泛接受。在流处理中选择SQL有以下几个原因:
1. **已知接口**:SQL是一种业界标准,大多数开发人员对其有基本了解,减少了学习曲线。
2. **无需编程**:使用SQL可以避免编写复杂的数据处理代码,使流程更易于理解和维护。
3. **声明性**:SQL允许用户以声明性的方式表达业务逻辑,专注于“做什么”而非“如何做”。
4. **内置优化**:流处理引擎可以对SQL查询进行优化,提高执行效率。
选择Streaming SQL将要面对的挑战
尽管SQL在流处理中有诸多优势,但也存在一些挑战:
1. **实时性**:流处理要求实时响应,SQL需要适应连续查询的需求。
2. **状态管理**:流处理中的连接操作需要维护状态,这可能带来复杂性和性能影响。
3. **窗口和时间语义**:在处理事件时间时,需要正确处理迟到数据和窗口定义。
在StreamingSQL中连接表的不同方式
文档提到了两种常见的表连接算法:
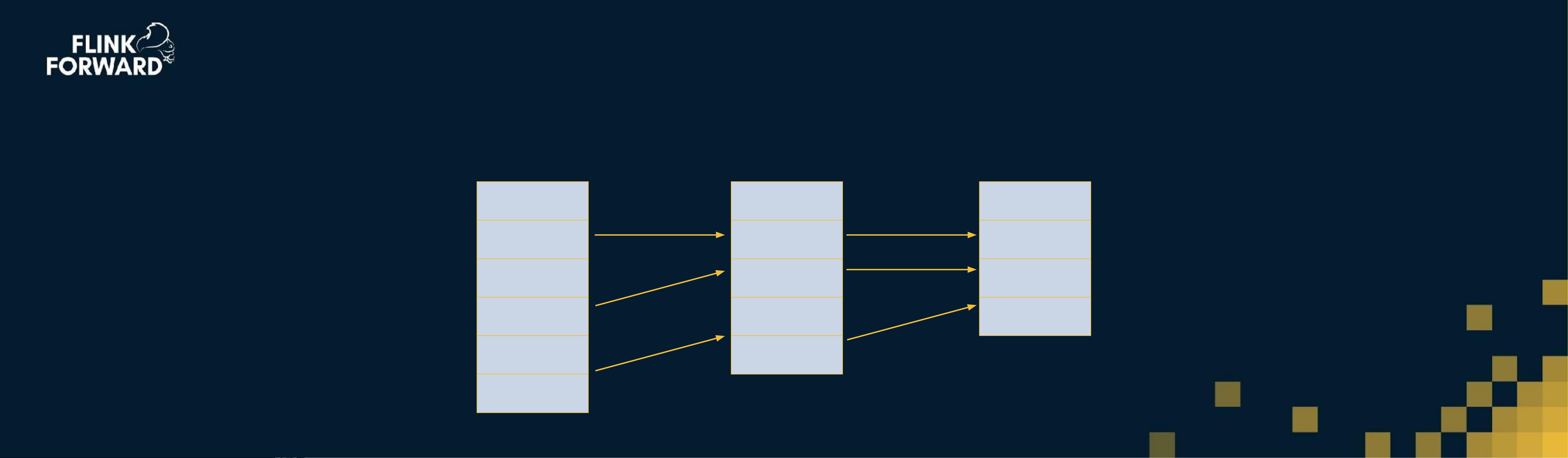
1. **归并连接算法**(Sort-Merge Join):首先对两个表进行排序,然后逐个元素进行比较和连接。适合于大表之间的连接,尤其是当数据可预测且内存充足时。
- 第一步是分类,对两个表进行排序。
- 第二步是合并和连接排序后的表。
2. **哈希连接算法**(Hash Join):对于较小的表,可以将其完全加载到内存中,然后使用哈希函数快速查找匹配项。这种方法对于内存有限但连接表较小的情况非常有效。
模式识别
在流处理中,模式识别是识别特定数据序列的重要功能,例如,检测异常或趋势。
其他近期成果
文档还提及了一些最近的改进,可能包括对SQL支持的增强,性能优化,以及处理复杂流处理需求的新特性。
Apache Flink的Streaming SQL提供了强大的工具,使得开发人员能够更方便地处理实时数据流,同时克服了流处理特有的挑战。通过利用SQL的声明性,可以简化复杂的业务逻辑实现,并利用内建优化来提高效率。随着技术的发展,Flink Streaming SQL将继续为云环境中的实时数据分析提供强大支持。

第一步 — 分类
First step - Sort
Table A
1
2
3
6
42
Table B
1
3
7
42
剩余46页未读,继续阅读
108 浏览量
103 浏览量
点击了解资源详情
107 浏览量
2021-10-05 上传
141 浏览量
104 浏览量
102 浏览量
2019-08-29 上传

weixin_38744435
- 粉丝: 373
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- gapi-script:npm包来加载gapi脚本并初始化一些功能
- BP神经网络的数据分类-语音特征信号分类
- nexthink_thanos
- url-pet:无效的简单URL缩短服务
- 行业分类-设备装置-一种接插式眼镜.zip
- is-png:检查BufferUint8Array是否为PNG图像
- QQ空间批量删除 梓涵QQ空间说说批量删除 v1.5
- XTW100高速24 25编程器.rar
- tddbc-sendai-x:TDDBC仙台X
- vinodvani.github.io
- GPS Date Converter:转换不同GPS日期格式的程序。-开源
- 行业分类-设备装置-一种接收机板卡及接收机.zip
- MyDiskTest 3.0.zip
- Data-Science-and-AI
- python数据分析与可视化-课后学习-15-查询学员代码实现.ev4.rar
- play_match_the_color_game:尝试匹配所选颜色的 RGB 或 YIQ 三元组-matlab开发
