Apriori算法详解:发现频繁项集的关键步骤与伪代码
需积分: 9 78 浏览量
更新于2024-08-02
1
收藏 174KB PDF 举报
Apriori算法是数据挖掘领域中一种著名的关联规则学习算法,用于发现频繁项集和生成关联规则。该算法由Professor Anita Wasilewska讲解,以英文形式提供详细的伪代码和实例,适用于理解频繁项集的概念以及如何通过迭代过程找出具有最低支持度的项集。
Apriori算法的核心概念包括:
1. **频繁项集**(Frequent Itemsets):这些是由满足用户定义的最小支持度阈值(通常用L或k-itemset表示)的项目组成的集合。例如,如果一个商品组合在交易记录中的出现频率高于预设阈值,则称其为频繁项集。
2. **Apriori性质**:这个性质指出,任何频繁项集的子集也必须是频繁的。这意味着,如果{A, B}是一个频繁项集,那么A和B单独也都应是频繁的。
3. **连接操作**(Join Operation):为了寻找Lk(k-itemset),算法会通过将Lk-1(k-1-itemset)与自身进行连接来生成一组候选k-itemset。这是算法的主要迭代步骤,通过不断增大项集的大小来挖掘潜在的频繁项。
算法的工作流程概括如下:
- **找出频繁项集**:从单个项目开始,逐步增加项目的数量,直到达到k-itemset。每次迭代都会检查所有可能的k-itemset,只有那些在所有数据集中支持度达到阈值的才会被标记为频繁项集。
- **剪枝步骤**(Prune Step):在生成的候选k-itemset中,如果某个(k-1)-itemset不是频繁的,那么它不能包含在任何频繁k-itemset中,因此可以被剔除,以减少后续计算的复杂性。
Apriori算法的伪代码主要包括两个关键步骤:
- **连接步(Join)**:创建一个新的候选k-itemset集合Ck,通过将Lk-1中的每个元素与其他元素配对形成新的项集。
- **剪枝步(Prune)**:遍历Ck,检查每个子集的频繁性。如果一个子集的频繁性不满足,将其从Lk中移除。
通过频繁项集的发现,Apriori算法能够为后续的关联规则生成提供基础,这些规则通常以“如果...则...”的形式表达,并描述了不同项目之间的关联模式。整个过程中,算法的效率是通过避免不必要的搜索和剪枝来优化的,确保了在大规模数据集上的有效应用。然而,由于其基于频繁集的性质,对于大数据集可能存在效率问题,后来的研究者提出了改进版本,如FP-Growth算法,以缓解这个问题。
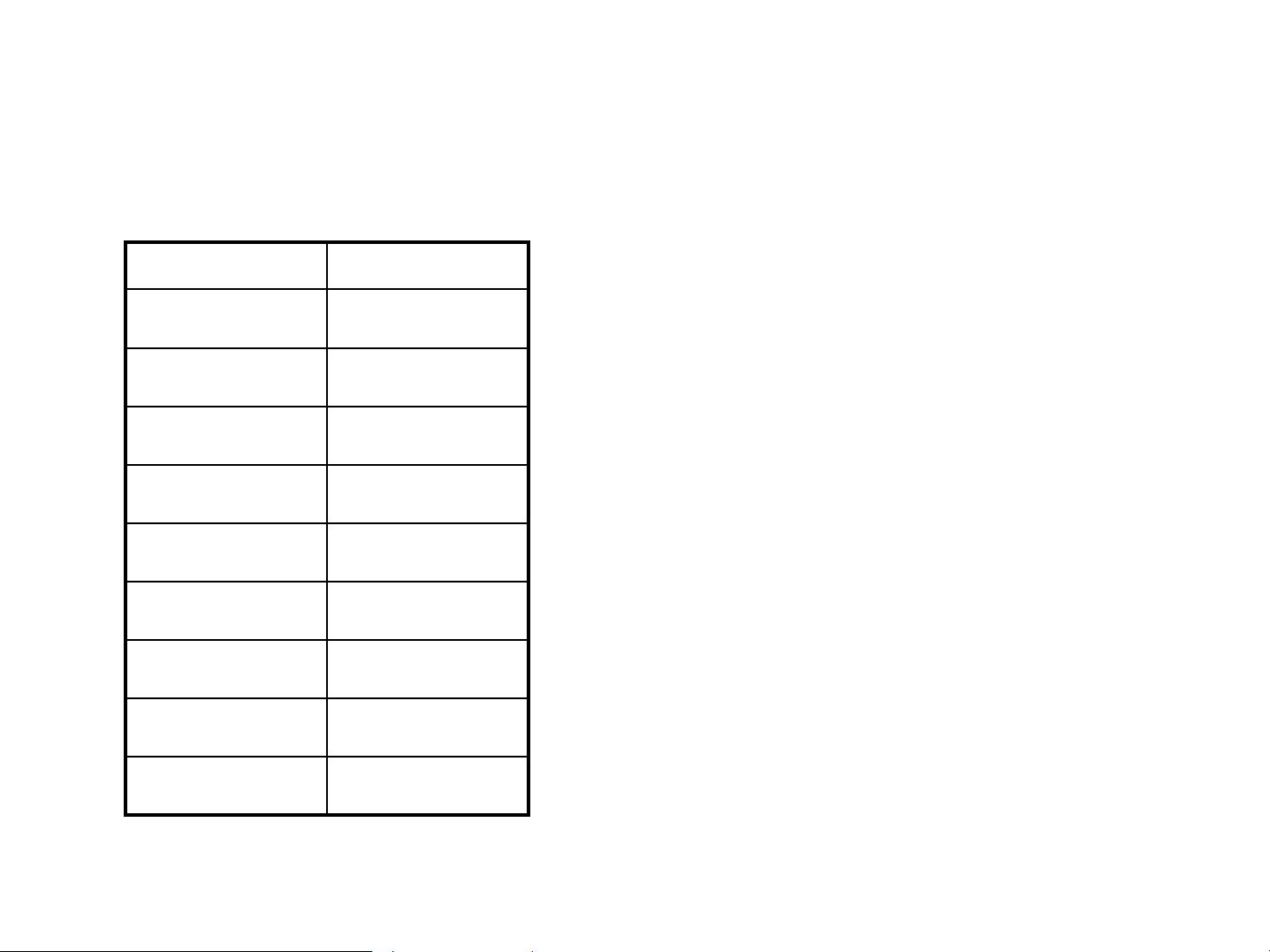
The Apriori Algorithm: Example
• Consider a database, D ,
consisting of 9 transactions.
• Suppose min. support count
required is 2 (i.e. min_sup = 2/9 =
22 % )
• Let minimum confidence required
is 70%.
• We have to first find out the
frequent itemset using Apriori
algorithm.
• Then, Association rules will be
generated using min. support &
min. confidence.
TID List of Items
T100 I1, I2, I5
T100 I2, I4
T100 I2, I3
T100 I1, I2, I4
T100 I1, I3
T100 I2, I3
T100 I1, I3
T100 I1, I2 ,I3, I5
T100 I1, I2, I3
剩余22页未读,继续阅读
2079 浏览量
3227 浏览量
2022-09-22 上传
108 浏览量
101 浏览量
2022-09-20 上传
137 浏览量
263 浏览量

zkspirit2
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 送药小车毕业设计送药小车毕业设计
- sxiv-patches:一组用于sxiv图像查看器的补丁
- minikube-nfs-test:在minikube上安装NFS服务器客户端的各种资源
- FreeRiderHMC
- Box's Evolutionary algorithm:求解多变量无约束优化-matlab开发
- 动科(DK)企业网站管理系统 v9.2
- scheamer
- Karabiner-Elements-12.8.0.dmg.zip
- 校园志愿者活动管理系统-志愿者小程序(含管理后台)-毕业设计
- ditto-subgraph
- astlog:星号SIP日志解析器
- Addon-Bluetooth-WebGUI:适用于FABI和FLipMouse的ESP32插件,添加了蓝牙和WiFiWebGUI支持
- 模拟
- MP4
- unist-util-modify-children:修改父母直系子女的实用程序
- 信呼协同办公系统 v1.6.0
