Lucene/Solr案例研究:提升信息检索与发现的实践
Lucene/Solr案例研究提供了丰富的实践应用示例,展示了这两个强大的搜索和信息检索技术在不同场景中的卓越表现。本篇由Erik Hatcher在2009年的ApacheCon EU大会上分享,主要关注了Lucene与Ant集成、内容索引构建,以及Solr在多个项目中的实际应用。
首先,Lucene与Ant集成案例展示了如何使用Ant构建工具自动化Lucene索引过程。通过定义XML任务,用户可以方便地指定文件目录,Lucene将根据这些设置进行高效地索引,提高了开发效率。
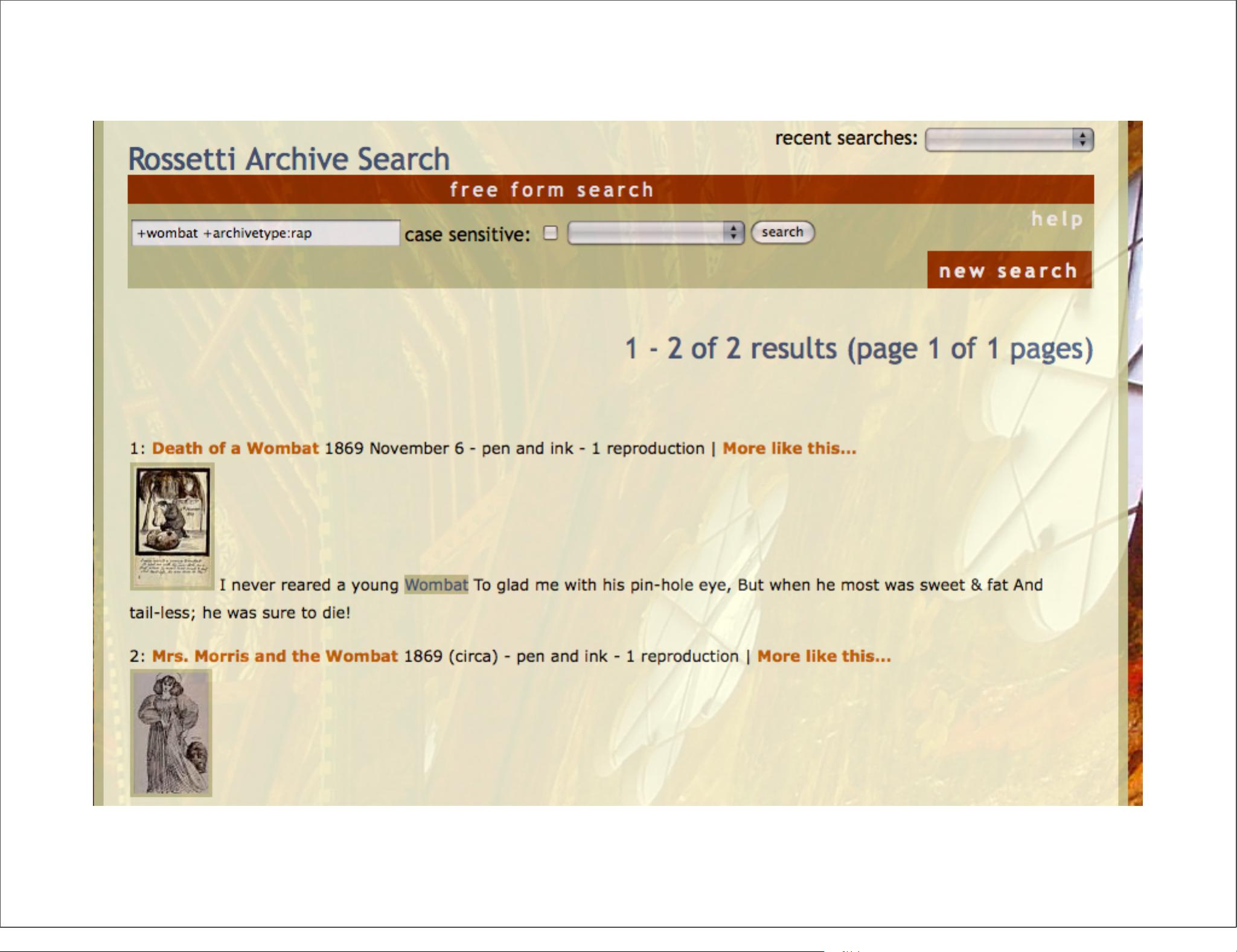
第二个案例是Rossetti Archive,该项目的目标是提升罗塞蒂艺术作品的可查找性和意外发现性。利用TEI(Text Encoding Initiative)类似的XML数据源,项目面临的挑战包括区分大小写搜索和学术相关性的精确度调整。Lucene的强大文本处理能力结合Tapestry框架,有效解决了这些问题,用户可以通过该平台深入探索罗塞蒂的艺术世界。
接着是Collex,这是一个以19世纪领域(NINES)为起点的学术对象搜索和分享平台,长远目标是实现通用用途。Collex的数据源包括RDF和MARC格式,挑战在于保持快速的标签更新速度。Solr作为核心技术,配合Ruby on Rails框架,确保了平台的高效性和易用性。
Blacklight是一个开源的下一代图书馆发现界面库,旨在提供可扩展且干净的用户体验。它支持多种数据源,如MARC、Fedora和EAD,同时考虑到学术界的需求和竞争环境。Solr Marc Java解析器的使用,使得黑光能够适应多样化的数据格式,实现内容的深度挖掘。
这些Lucene和Solr的案例研究揭示了它们在学术、艺术和信息检索领域的广泛应用,强调了搜索引擎技术在提高信息发现和检索效率方面的关键作用,以及如何通过定制化和集成不同的技术栈来满足特定项目的需求。通过学习这些案例,开发者和用户可以更好地理解如何优化搜索体验并解决实际问题。
5
剩余23页未读,继续阅读
131 浏览量
点击了解资源详情
点击了解资源详情
2015-04-13 上传
2019-05-26 上传
197 浏览量
2022-09-24 上传
2021-05-16 上传

味甘
- 粉丝: 7
- 资源: 77
 我的内容管理
展开
我的内容管理
展开







