分布式搜索引擎优化:基于hadoop、nutch与solr
版权申诉
67 浏览量
更新于2024-07-02
收藏 2.21MB PDF 举报
"大数据技术文档,涉及Hadoop、Nutch和Solr的使用,旨在优化分布式搜索引擎的索引构建策略。"
本文档主要探讨了大数据处理的背景和现状,特别关注了分布式处理框架Hadoop以及在搜索引擎应用中的Nutch和Solr。随着互联网信息的爆炸性增长,传统的信息检索方式面临挑战,需要更高效、可扩展且安全的解决方案。Hadoop作为一个开源的分布式处理框架,因其高效、可扩展和高可靠性的特点,成为了大数据处理的首选工具。
Hadoop的主要优点在于其分布式文件系统HDFS和MapReduce编程模型。HDFS能够处理大规模数据,通过数据冗余确保高可用性,而MapReduce则将复杂计算分解为可并行处理的部分,极大提升了处理速度。此外,Hadoop允许动态添加节点,适应不断增长的数据量,保持系统的稳定运行。
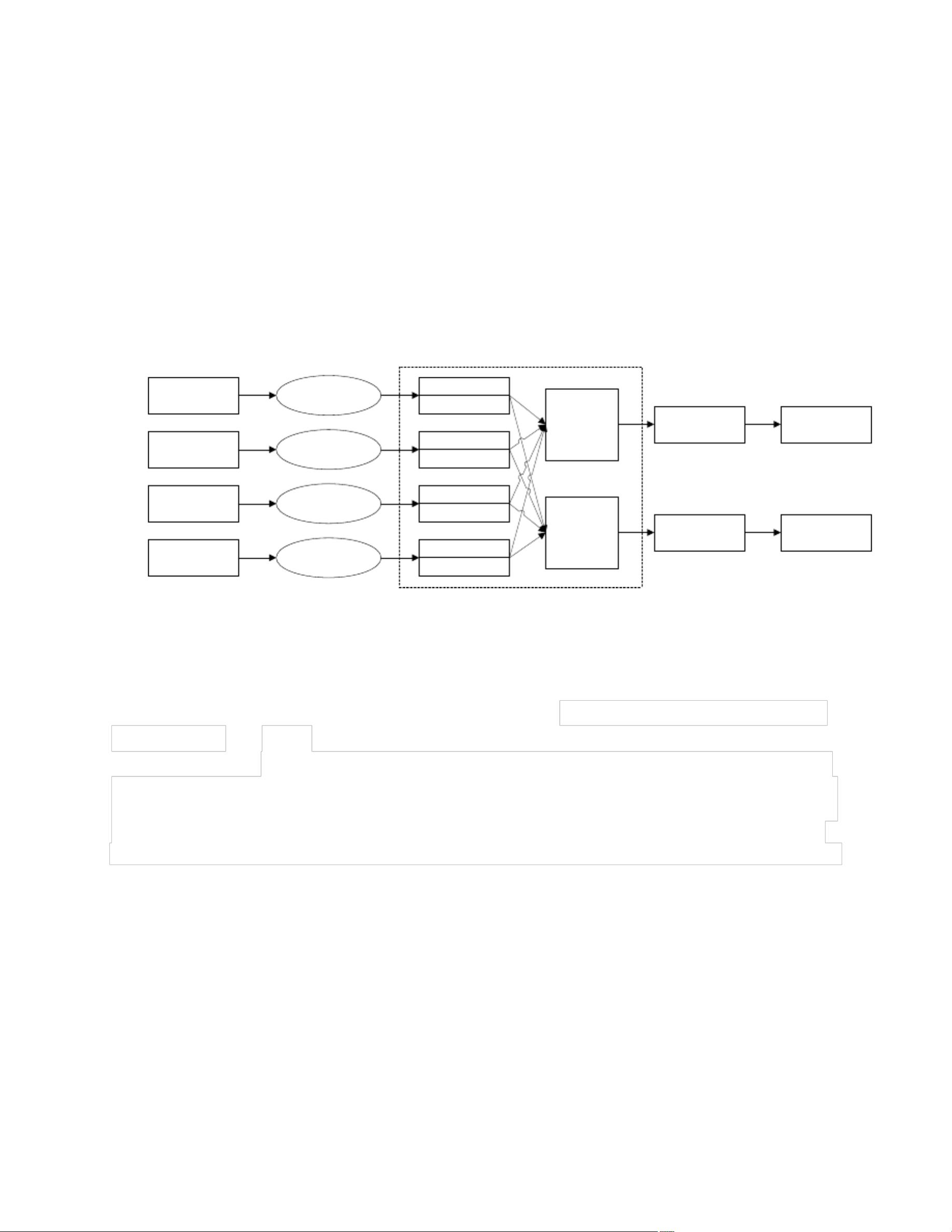
Nutch作为Hadoop生态系统的一部分,负责网页的抓取、解析和评分,同时与Solr结合,构建索引以提升搜索引擎的效果。Nutch的插件机制使其具备高度灵活性,可以针对不同需求定制抓取和解析策略,以提高搜索的相关度。而Solr则提供了强大的分布式索引和检索能力,能够跨服务器交换信息,支持主题索引。
本文的研究目标聚焦于深入研究Hadoop的分布式平台和Nutch的架构,特别是Nutch的插件系统。通过开发特定插件,如支持表单登录、URL过滤和信息解析,以提升搜索引擎的性能和相关性。此外,文中提及使用MapReduce实现Google的PageRank排序算法,进一步优化系统的搜索关联度。
系统功能结构方面,文档提到了本地资源解析模块,该模块可能负责处理本地的非结构化数据,如PDF文本,将其转化为可供搜索的结构化信息。这表明整个系统不仅处理网络数据,还能整合各种本地资源,提供全面的搜索服务。
总结来说,这份文档详尽地介绍了如何利用Hadoop、Nutch和Solr构建和优化分布式搜索引擎,解决大数据环境下的信息检索问题,提高搜索质量和效率。通过对这些技术的深入理解和应用,可以为大数据时代的搜索引擎提供更高效、精准的服务。

Hbase分布式数据库 Pig数据流语言 Hive数据仓库 Mahout数据挖掘库 Avro远程过程调用
MapReduce
分布式处理模型
HDFS
分布式文件系统
ZooKeeper
分布式协同系统
Hadoop Common
Hadoop项目的核心
图 Hadoop 框架图
子项目
Hadoop Common
HDFS
MapReduce
HBase
Pig
Hive
ZooKeeper
Mahout
Arvo
功能
Hadoop 系统核心,提供子项目的基本支持
实现高吞吐的分布式存储
执行分布式并行计算
一个可扩展的分布式数据库系统
为并行计算提供数据流语言和执行框架
提供类 SQL 语法进行数据查询的数据仓库
提供分布式锁等
一个大规模机器学习和数据挖掘库
Hadoop 的 RPC(远程过程调用)方案
表 Hadoop 子项目功能介绍
5
剩余31页未读,继续阅读
2021-11-06 上传
2022-12-24 上传
2022-12-24 上传

xxpr_ybgg
- 粉丝: 6717
- 资源: 3万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
