Stata面板数据回归教程:快速编辑与分析
版权申诉
"这篇教程主要介绍了如何在Stata中进行面板数据回归分析,适合初学者快速上手。通过5个步骤,详细阐述了数据编辑、格式调整、排序和保存的过程。"
在统计分析和经济学研究中,面板数据回归是一种常用的方法,它结合了截面数据和时间序列数据的优点,能更好地捕捉个体效应和时间效应。Stata作为一款强大的统计软件,提供了便捷的面板数据分析功能。以下是使用Stata进行面板数据回归的详细步骤:
第一步:编辑数据
在进行面板数据回归前,需要将所有变量的数据录入Stata。这通常涉及将Excel中的数据复制到Stata的数据编辑框中。确保数据按照正确的格式排列,例如,对于模型𝑌𝑖𝑡=𝛽0+𝛽1𝑋1𝑖𝑡+𝛽2𝑋2𝑖𝑡+𝛽3𝑋3𝑖𝑡+𝜀𝑡,需要包含 Yi, Xi1, Xi2, 和 Xi3 的数据。
第二步:格式调整
1. 重命名变量:将代表样本的变量(例如var1)重命名为更具描述性的名称,如province。
2. 转换数据格式:使用`reshape long`命令将数据转换为面板数据格式。例如,`reshape long var, i(province)`,其中var表示年份变量,i(province)表示个体标识。
3. 重命名新生成的年份变量:默认生成的变量_j,可以使用`rename _j year`将其命名为年份。
4. 重命名其他变量:例如,如果Y变量是taxi,可以使用`rename var taxi`来保持变量名称的一致性。
第三步:排序
为了确保数据正确无误,需要对数据进行排序。使用`sort`命令按照个体(province)和时间(year)进行升序排列,命令为`sort province year`。
第四步:保存数据
完成数据处理后,别忘了保存工作,确保所做的更改被保存下来。
第五步:重置Stata
使用`clear`命令清除当前工作区,以便导入下一个变量(例如X1)的数据,准备进行下一步操作。
以上步骤是Stata中进行面板数据回归的基础流程,对于初学者来说,理解并熟练掌握这些步骤至关重要。在实际操作中,可能还需要进行数据清洗、缺失值处理、变量转换等预处理步骤,以及模型选择、估计和结果解释等后续步骤。面板数据回归不仅涉及到回归模型的选择(如固定效应模型、随机效应模型),还可能需要考虑时间趋势、异方差性、自相关等问题。学习Stata面板数据回归,不仅能提升数据分析能力,也为理解和应用更复杂的统计方法打下基础。
5 分钟速学 stata 面板数据回归(超实用!)
第一步:编辑数据。
面板数据的回归,比如该回归模型为:
,在
stata 中进行回归,需要先将各个变量的数据逐个编辑好,该模型中共有 Y X1 X2 X3 三个变量,
那么先从 Y 的数据开始编辑,将变量 Y 的面板数据编辑到 stata 软件中,较方便的做法是,
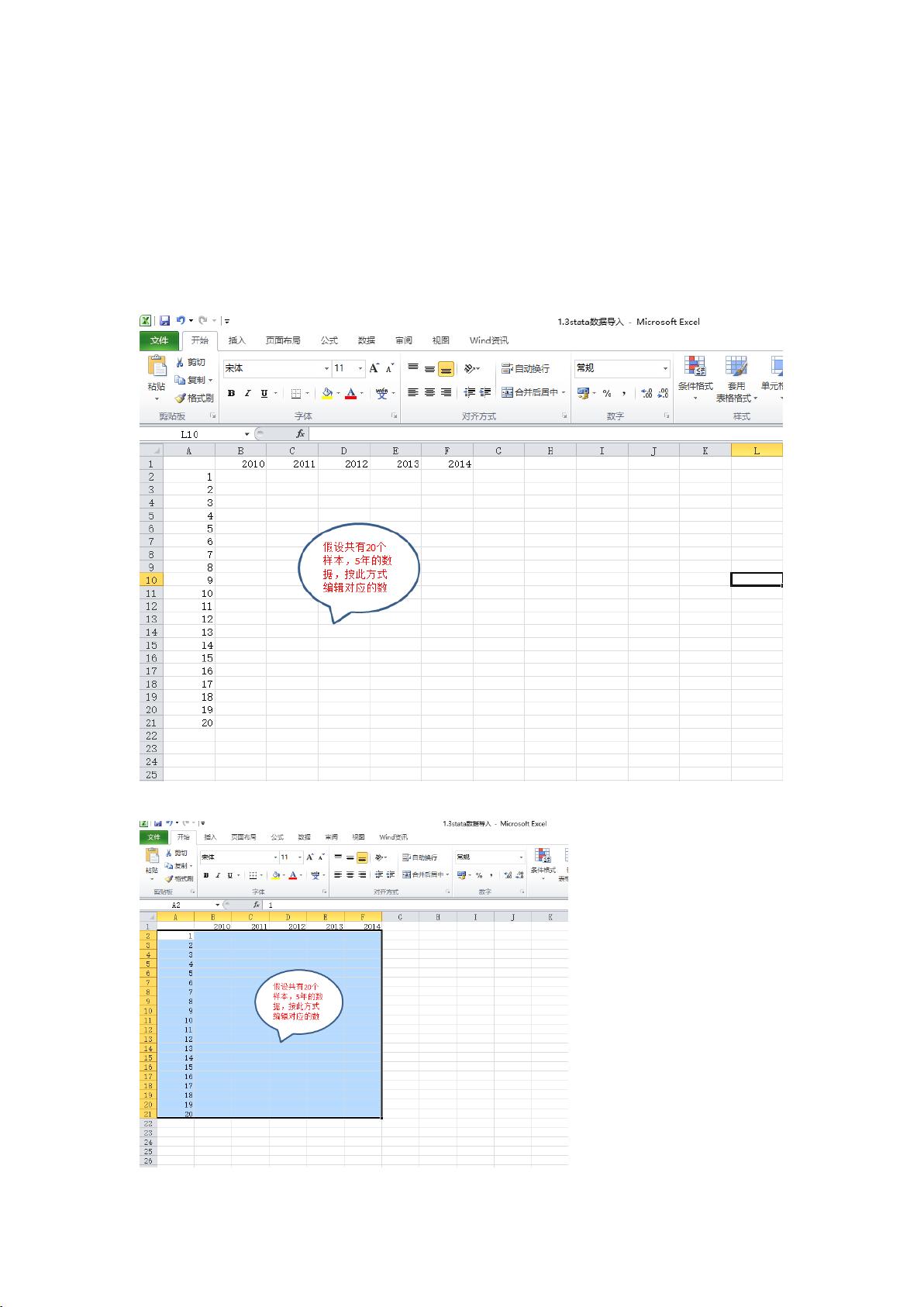
将 excel 的数据直接复制到 stata 软件的数据编辑框中,而 excel 中的数据需要如下图编辑:
从数据的第二行开始选中 20 个样本数据,如图:
下载后可阅读完整内容,剩余4页未读,立即下载
相关推荐





samFuB
- 粉丝: 1934
 我的内容管理
展开
我的内容管理
展开







最新资源
- 革新操作体验:无需最小化按钮的窗口快速最小化工具
- VFP9编程实现EXCEL操作辅助软件的使用指南
- Apache CXF 2.2.9版本特性及资源下载指南
- Android黄金矿工游戏核心逻辑揭秘
- SQLyog企业版激活方法及文件结构解析
- PHP Flash投票系统源码及学习项目资源v1.2
- lhgDialog-4.2.0:轻量级且美观的弹窗组件,多皮肤支持
- ReactiveMaps:React组件库实现地图实时更新功能
- U盘硬件设计全方位学习资料
- Codice:一站式在线笔记与任务管理解决方案
- MyBatis自动生成POJO和Mapper工具类的介绍与应用
- 学生选课系统设计模版与概要设计指南
- radiusmanager 3.9.0 中文包发布
- 7LOG v1.0 正式版:多元技术项目源码包
- Newtonsoft.Json.dll 6.0版本:序列化与反序列化新突破
- Android实现SQLite数据库高效分页加载技巧
