注意力机制提升NLP中LSTM性能:解决长序列信息丢失问题
需积分: 10 60 浏览量
更新于2024-09-05
收藏 325KB PDF 举报
在自然语言处理(NLP)领域,"Attention机制.pdf"文件深入探讨了为什么在编码器-解码器模型中引入注意力机制以及如何实现这一过程。传统的模型面临的主要挑战是,编码阶段将整个序列压缩到一个固定长度的语义向量C中,导致信息损失和长序列处理的困难。注意力机制的引入旨在解决这些问题。
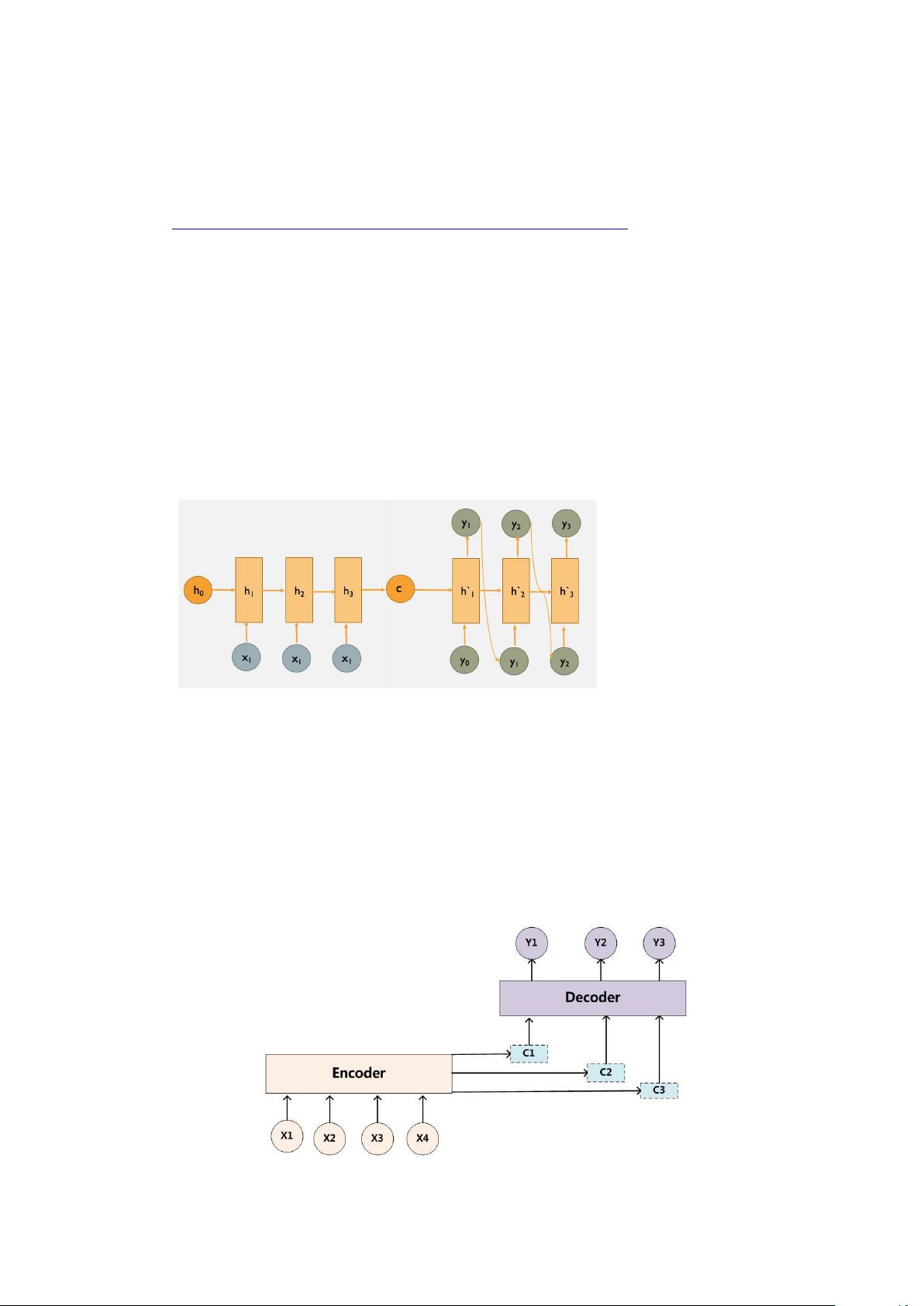
首先,使用注意力机制的动机在于提升模型对输入序列信息的动态处理能力。传统的encoder-decoder模型依赖于单一的语义向量C,无法充分表达长序列中的所有细节。注意力机制允许解码阶段针对编码器的隐藏向量序列(h1,...,hT_x)进行动态选择,这意味着在生成每个输出Y_i时,模型可以根据当前生成的状态调整对输入的注意力分配,从而避免了信息丢失。
具体实现上,注意力机制通过以下步骤工作:
1. **注意力分配**:在解码器的每一时刻i,计算一个隐藏层输出yi-1与编码器隐藏状态h_j之间的相似度,形成一个权重α_ij。这些权重反映了当前时刻i对输入序列中各个位置j的注意力程度。
2. **计算注意力向量ci**:将编码器隐藏向量序列按权重α_ij进行加权求和,得到注意力向量ci,它反映了在生成Y_i时,模型对输入序列中哪些部分更重视。
3. **条件概率的更新**:将注意力向量ci与解码器的上一时刻隐藏状态si-1结合,计算出生成当前单词Y_i的条件概率。
通过这种方式,注意力机制使得模型能够灵活地处理输入序列,每个输出都能基于当前生成上下文动态调整对输入的利用,显著提高了翻译任务等应用场景中的性能。例如,Seq2Seq模型(Sequence-to-Sequence)在加入注意力机制后,其结构更加灵活,适应性更强,能够更好地保留长序列中的细节信息,从而提升模型的准确性和流畅度。理解注意力模型的核心在于它能够实时调整中间语义表示,使之与当前生成的单词相适应,这是与传统模型显著的区别。
NLP 中 LSTM 的 attention 机制的应用讲解
文章转载:
https://www.cnblogs.com/dllearning/p/7834018.html
1.
为什么要使用
attention
由于 encoder-decoder 模型在编码和解码阶段始终由一个不变的语义向量 C 来联系
着,编码器要将整个序列的信息压缩进一个固定长度的向量中去。这就造成了 (1)语义
向量无法完全表示整个序列的信息,(2)最开始输入的序列容易被后输入的序列给覆盖掉,
会丢失许多细节信息。在长序列上表现的尤为明显。
2.怎么实现 attention 机制
相比于之前的 encoder-decoder 模型,attention 模型最大的区别就在于它不在要求
编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编
码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进
行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。
而且这种方法在翻译任务中取得了非常不错的成果。
下图为 seq2seq 模型加入了 Attention 注意力机制
下载后可阅读完整内容,剩余5页未读,立即下载
2019-07-17 上传
2020-04-25 上传
2020-11-21 上传
2019-10-30 上传
2020-04-20 上传
2019-06-11 上传
2021-09-26 上传
2020-03-26 上传
2021-09-18 上传









