深入解析Java HashMap的工作原理与实现细节
PDF格式 | 389KB |
更新于2024-09-01
| 84 浏览量 | 举报
Java HashMap是Java编程语言中常用的一种高效哈希映射表数据结构,它实现了`java.util.Map<K, V>`接口,提供了插入、查找和删除键值对的功能。本文将深入解析HashMap的工作原理,包括其内部实现细节、数据结构设计以及Java 8版本的新增特性。
HashMap的核心机制基于哈希函数,它通过将键(K)转换成一个整数哈希码,再根据这个哈希码将键值对分配到数组中的特定位置,通常使用数组的索引来表示。HashMap使用一个固定大小的Entry数组(默认为16,可以根据负载因子动态调整),每个数组元素称为“桶”或“容器”。
内部存储结构中,HashMap使用一个名为`Entry<K, V>`的内部类,它封装了键值对,并且包含一个指向下一个Entry的引用,这样就构成了链表形式的数据结构。每当一个新的键值对被插入,它会被添加到对应哈希值的链表末尾。如果两个键具有相同的哈希值,它们将共享同一个桶,形成一个链表,从而解决了哈希冲突。
在Java 8中,HashMap引入了可变哈希表(ConcurrentHashMap)的概念,提供了线程安全的并发操作。此外,HashMap的底层实现还考虑了性能优化,例如使用尾递归优化减少内存消耗,以及在链表长度超过一定阈值时自动扩容,以保持良好的性能和空间效率。
当用户通过`put()`方法插入键值对时,首先计算键的哈希码,然后根据计算结果找到相应的桶。接着,遍历该桶内的链表,查找与给定键匹配的`Entry`。如果找到匹配项,更新值;如果没有找到,则在链表尾部添加新项。而`get()`方法则执行类似的步骤,只不过它是查找键对应的值,而不是添加新的键值对。
然而,HashMap并非没有性能上的挑战。由于哈希冲突的存在,最坏情况下的时间复杂度为O(n),当负载因子过高时可能导致性能下降。因此,在实际使用中,应合理设置初始容量和负载因子,以维持良好的性能。
总结来说,Java HashMap的工作原理围绕着哈希函数、桶和链表结构展开,它在性能、内存管理和并发控制方面都有一定的策略。了解这些原理有助于开发者更有效地使用HashMap,并解决可能遇到的问题。
Java HashMap的工作原理的工作原理
主要介绍了Java HashMap的工作原理的相关资料,需要的朋友可以参考下
大部分Java开发者都在使用Map,特别是HashMap。HashMap是一种简单但强大的方式去存储和获取数据。但有多少开发者
知道HashMap内部如何工作呢?几天前,我阅读了java.util.HashMap的大量源代码(包括Java 7 和Java 8),来深入理解这
个基础的数据结构。在这篇文章中,我会解释java.util.HashMap的实现,描述Java 8实现中添加的新特性,并讨论性能、内存
以及使用HashMap时的一些已知问题。
内部存储内部存储
Java HashMap类实现了Map<K, V>接口。这个接口中的主要方法包括:
V put(K key, V value)
V get(Object key)
V remove(Object key)
Boolean containsKey(Object key)
HashMap使用了一个内部类Entry<K, V>来存储数据。这个内部类是一个简单的键值对,并带有额外两个数据:
一个指向其他入口(译者注:引用对象)的引用,这样HashMap可以存储类似链接列表这样的对象。
一个用来代表键的哈希值,存储这个值可以避免HashMap在每次需要时都重新生成键所对应的哈希值。
下面是Entry<K, V>在Java 7下的一部分代码:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
…
}
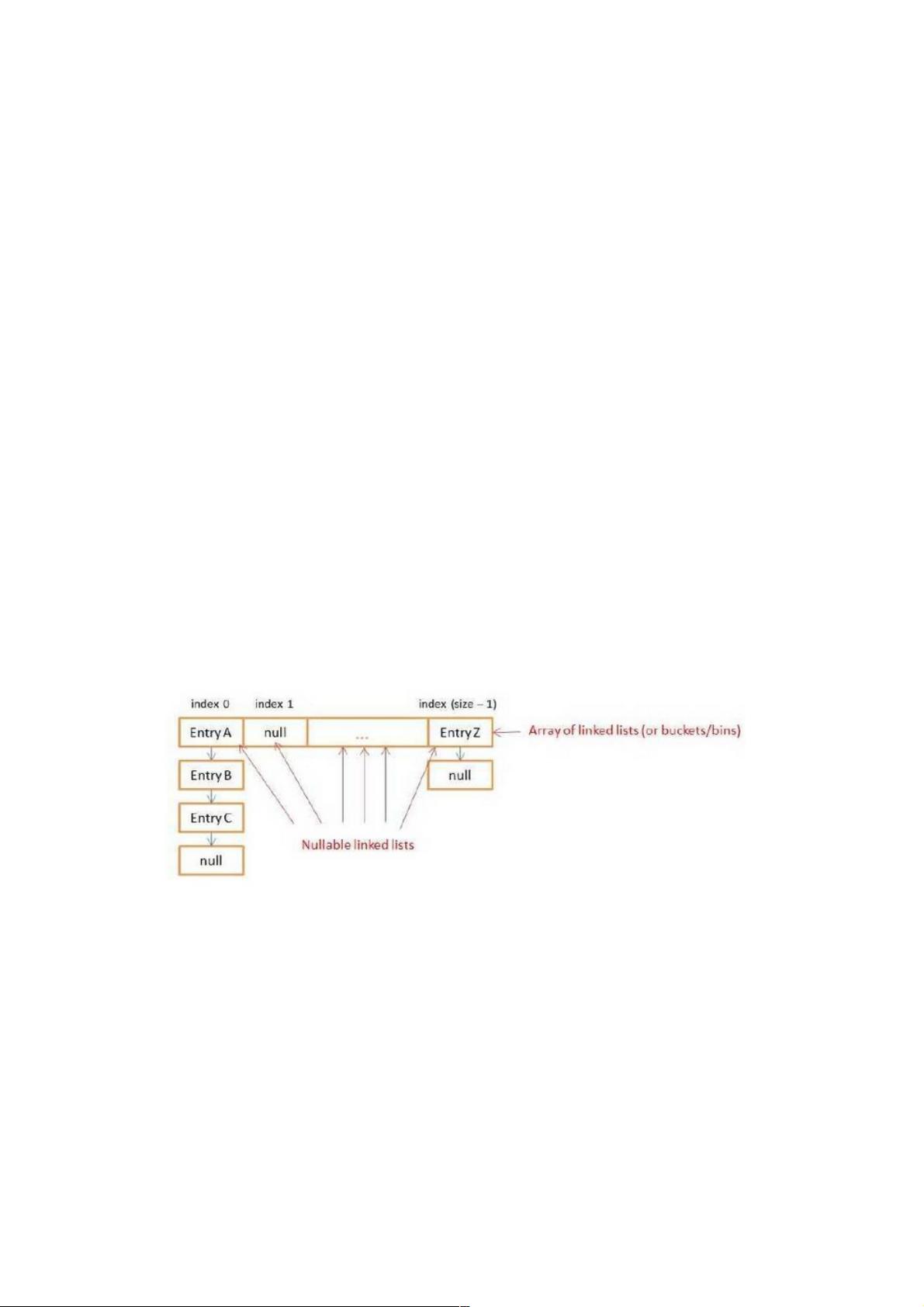
HashMap将数据存储到多个单向Entry链表中(有时也被称为桶bucket或者容器orbins)。所有的列表都被注册到一个Entry数
组中(Entry<K, V>[]数组),这个内部数组的默认长度是16。
下面这幅图描述了一个HashMap实例的内部存储,它包含一个nullable对象组成的数组。每个对象都连接到另外一个对象,这
样就构成了一个链表。
所有具有相同哈希值的键都会被放到同一个链表(桶)中。具有不同哈希值的键最终可能会在相同的桶中。
当用户调用 put(K key, V value) 或者 get(Object key) 时,程序会计算对象应该在的桶的索引。然后,程序会迭代遍历对应的
列表,来寻找具有相同键的Entry对象(使用键的equals()方法)。
对于调用get()的情况,程序会返回值所对应的Entry对象(如果Entry对象存在)。
对于调用put(K key, V value)的情况,如果Entry对象已经存在,那么程序会将值替换为新值,否则,程序会在单向链表的表头
创建一个新的Entry(从参数中的键和值)。
桶(链表)的索引,是通过map的3个步骤生成的:
首先获取键的散列码。
程序重复散列码,来阻止针对键的糟糕的哈希函数,因为这有可能会将所有的数据都放到内部数组的相同的索引(桶)上。
程序拿到重复后的散列码,并对其使用数组长度(最小是1)的位掩码(bit-mask)。这个操作可以保证索引不会大于数组的
大小。你可以将其看做是一个经过计算的优化取模函数。
下面是生成索引的源代码:
// the "rehash" function in JAVA 7 that takes the hashcode of the key
下载后可阅读完整内容,剩余7页未读,立即下载
相关推荐





weixin_38629303
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开








最新资源
- WinIo3.0 64位及32位驱动文件与使用示例
- CentOS64位环境下Hadoop-2.7.5编译及安装指南
- Axure RP:美国Axure公司快速原型设计工具介绍
- 蓝色简洁PPT背景图片免费下载
- 跨平台音乐播放器:Qt开发实现Android、Windows、iOS三系统兼容
- 中国PACS标准推荐:AAPM TG18噪声测试图的应用
- Mybatis自动代码生成工具包:一键生成项目框架
- Maya展UV实用插件-UVDeluxe功能与介绍
- Hadoop Eclipse 插件 - 快速安装与使用指南
- ESP8266从入门到精通的实例教程
- 掌握Linux系统中HTTP代理程序的简易搭建技巧
- 深度学习模型peleenet在压缩包中的应用
- 绿色瑜伽PPT背景图片:健康养生幻灯片模板
- 北京大学数字电路EDA课程设计深度解析
- 将OSG 3.2.0嵌入Qt 5.2.0框架的实现方法
- 浩顺小票机驱动安装简易,计算机光驱故障时的完美替代
