Hadoop 2.0:Baidu的研究与进展
需积分: 13 112 浏览量
更新于2024-07-28
收藏 1.62MB PDF 举报
"Hadoop最新的研究重点和进展主要集中在Hadoop 2.0的改进,包括HDFS(Hadoop Distributed File System)的扩展性和可用性提升,以及MapReduce的升级。在百度的实践中,Hadoop已经应用于大规模的数据处理,拥有超过1.5万个节点,每天处理的数据量超过10PB,并且管理着10个以上的集群,其中最大的一个包含3000个节点。未来的研究方向包括云数据传输、提高MapReduce应用的稳定性以及应对更大规模的集群挑战。"
Hadoop是大数据处理领域的重要框架,其最新的研究焦点在于优化系统性能和可扩展性。HDFS 2.0的引入旨在解决文件数量、数据块的增长以及负载均衡问题,以支持更大型的分布式存储系统。HDFS Federation是这一改进的关键部分,通过将单一的NameNode拆分为多个NameNode,解决了单点故障问题,提高了系统的可用性。这一改动预计在2011年11月的hadoop-0.23版本中发布。
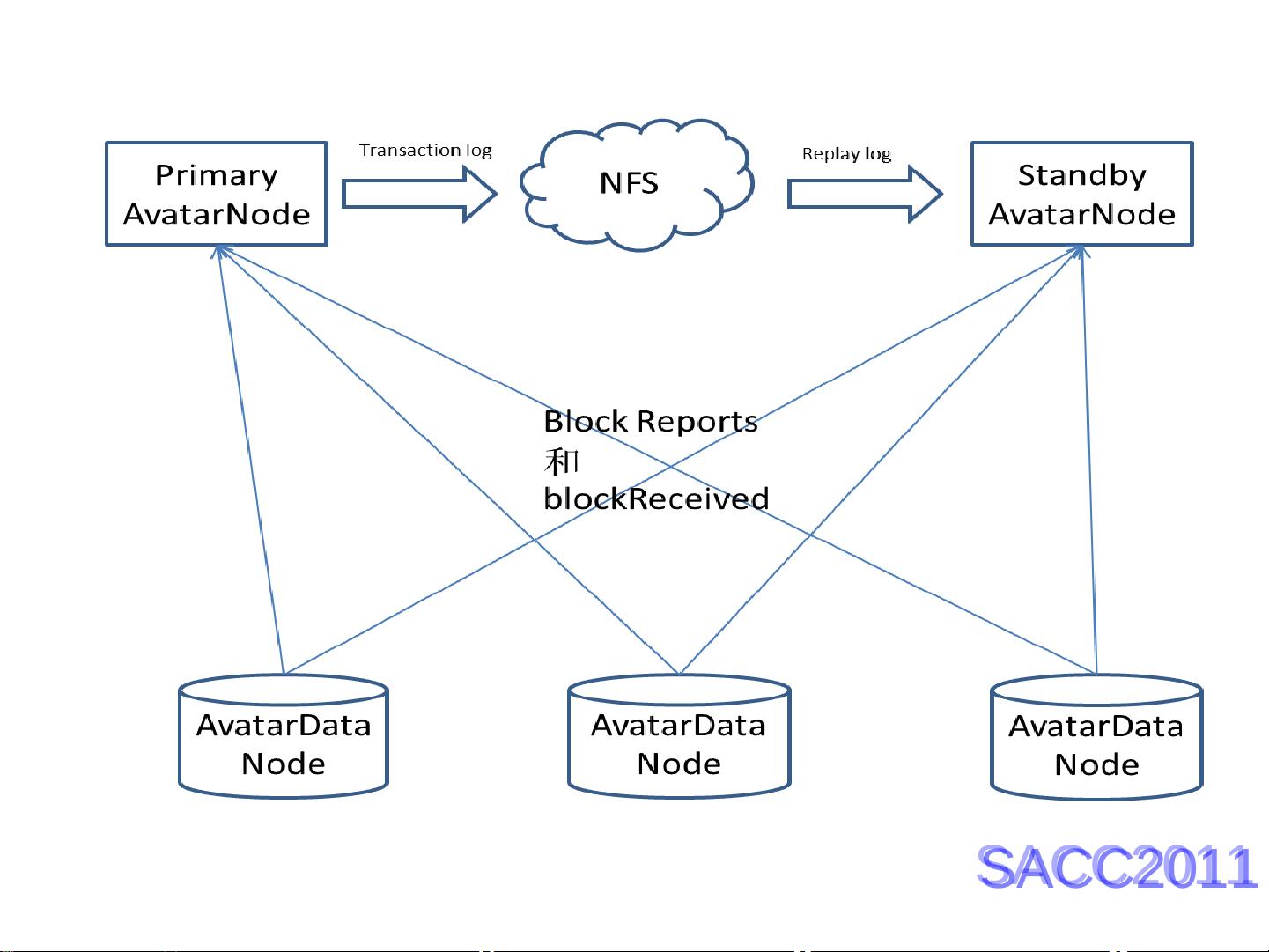
在可用性方面,针对NameNode的单点故障,社区提出了两种解决方案:AvatarNameNode和BackupNameNode。Facebook采用的AvatarNameNode架构利用NetApp Filer实现热备份,通过在同一网段内的VIP提供高可用性。然而,BackupNameNode的实现较为复杂,可能会导致服务不稳定。此外,MapR公司的HDFS方案也提供了增强的可用性和性能。
MapReduce 2.0(也称为NextMapReduce或YARN)是另一个重要的研究方向,它的目标是提高集群资源管理和应用程序生命周期的管理,以适应更复杂的计算需求和更大的集群规模。这将通过引入集群级的资源调度和更好的任务管理来提升MapReduce的可扩展性,确保大规模并行处理任务的高效执行。
在百度的应用中,他们已经对Hadoop进行了定制,发展了Baidu-HDFS 2.0和Baidu-MapReduce 2.0,以满足内部的大数据处理需求。未来的工作计划包括CloudTransfer,旨在优化数据在云端的迁移,以及MR-On-time项目,目的是提高MapReduce应用的稳定性。同时,面对处理更大规模集群的挑战,这也是Hadoop社区和企业用户共同关注的问题。

剩余31页未读,继续阅读
2021-07-18 上传
109 浏览量
2021-08-21 上传
2021-08-08 上传
2022-04-16 上传
2021-07-04 上传
2021-08-15 上传
2021-07-14 上传
2020-05-16 上传

Mushroom_lb
- 粉丝: 149
- 资源: 954
 我的内容管理
展开
我的内容管理
展开







最新资源
- StickyMayhem
- Face-Tracker-Haar-Kanade:使用Lucas-Kanade和Haar Cascade算法即使在数据集有限的情况下也可以跟踪人脸
- dodgeballs:躲开球!
- 女性美容养生护理手机网站模板
- template-cpanel-adminiziolite:模板 CPanel Adminiziolite
- raw-connect:具有Polkadot JS WasmProvider实现的基板Wasm客户端的原始模板
- 基于三菱PLC程序的花样喷泉控制程序.zip
- Yoda-to-sl:尤达告诉你怎么走!
- soko-city:崇光市
- 防京东商城手机网站模板
- Awesome-Trajectory-Prediction
- 易语言-易语言简单的多线程例子
- 模板-tmp7
- 间歇交替输出PLC程序.rar
- ecommerce-bikeshop:一个电子商务网络应用程序,受在线自行车商店网站的启发,让您使用Google身份验证创建帐户,添加购物车中的商品,使用Stripe进行付款等等
- django-dropboxchooser-field:Django的Dropbox选择器字段
