C语言编译与链接全过程解析
版权申诉
88 浏览量
更新于2024-09-11
收藏 164KB PDF 举报
C语言编译过程总结详解
C语言的编译过程是将源代码转换为可执行程序的关键步骤,它包括预处理、编译、汇编和链接四个主要阶段。下面是对每个阶段的详细解释:
1. **预处理**:
预处理是在正式编译之前进行的,主要任务是处理预处理指令(如`#include`,`#define`等)。`#include`指令会将指定的头文件内容插入到源文件中,以便引入所需的功能或声明。`#define`用于创建宏定义,将源代码中的特定标识符替换为其他文本,这在处理条件编译时非常有用。例如,通过`#ifdef`、`#ifndef`、`#else`、`#elif`和`#endif`,开发者可以编写跨平台的代码,根据编译时的条件选择性地编译部分代码。
2. **编译**:
编译阶段,编译器读取经过预处理的源代码,进行词法分析和语法分析。词法分析将源代码分解为一个个的符号(token),而语法分析则检查这些符号是否符合C语言的语法规则。如果源代码符合语法规则,编译器会将其转换为中间表示,通常是汇编代码。在这个过程中,编译器还会进行类型检查、优化以及错误和警告的报告。
3. **汇编**:
汇编阶段,汇编器将编译器生成的汇编代码转换为机器语言,即目标代码。目标代码是与特定处理器架构相关的二进制形式,但还不是可以直接执行的程序,因为它还缺少与操作系统交互的必要信息。
4. **链接**:
链接阶段,链接器将编译产生的目标文件与其他库文件(如标准库)合并,生成最终的可执行文件。它负责解决函数调用和全局变量的引用,确保所有必要的代码片段都包含在内。如果源代码中使用了外部函数或全局变量,链接器会在系统库中查找它们的定义,并将它们连接到目标代码中。
整个编译过程是一个复杂且有序的步骤,旨在将人类可读的源代码转换为机器可执行的二进制代码。理解这个过程有助于开发者更好地调试和优化他们的C语言程序,特别是在处理依赖关系、错误定位和性能提升时。通过了解编译过程,开发者能够更有效地利用编译器的特性,如宏、条件编译和优化选项,来提高代码的质量和效率。
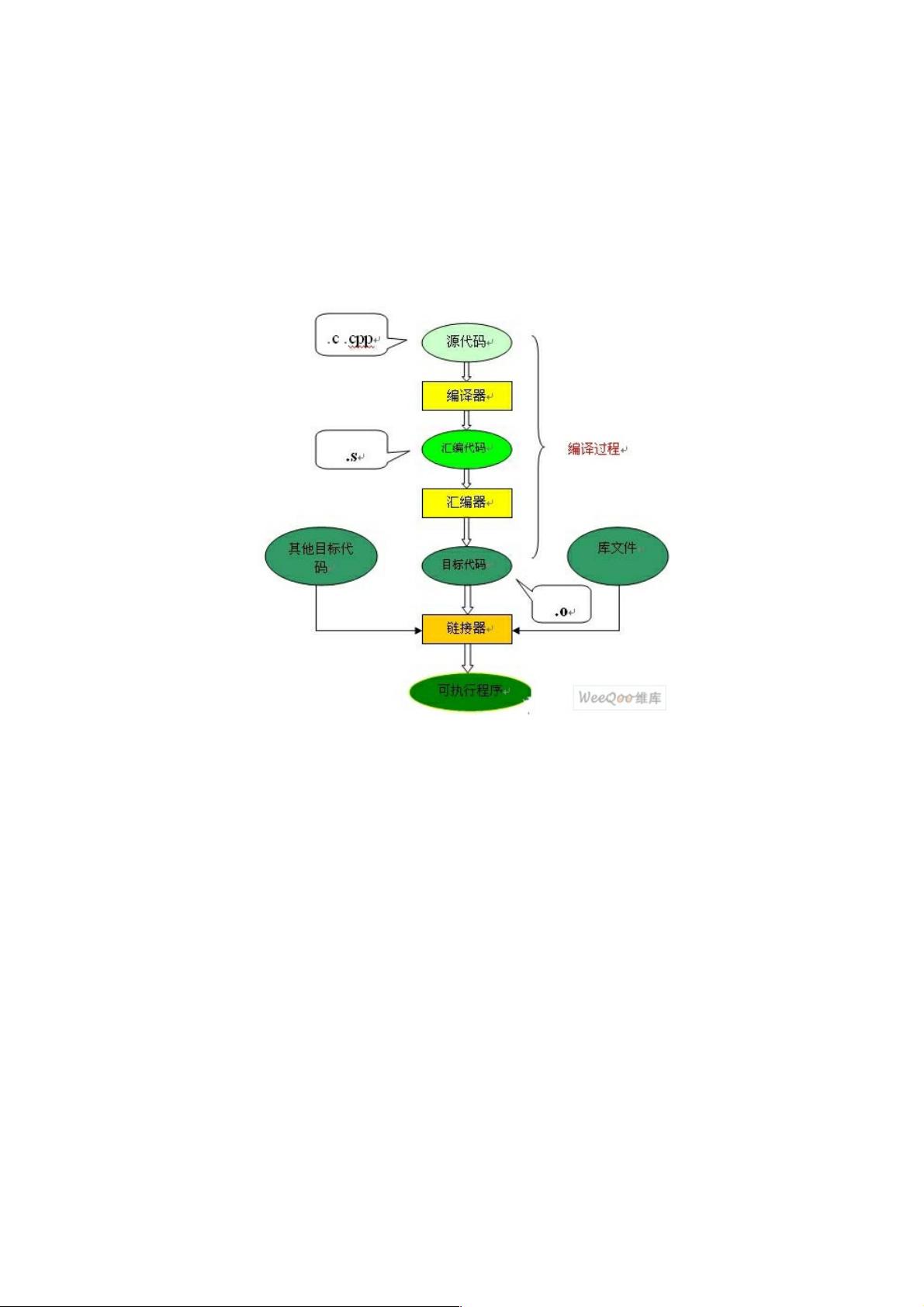
C语言编译过程总结详解语言编译过程总结详解
C语言的编译链接过程要把我们编写的一个c程序(源代码)转换成可以在硬件上运行的程序(可执行代码),
需要进行编译和链接。编译就是把文本形式源代码翻译为机器语言形式的目标文件的过程。链接是把目标文
件、操作系统的启动代码和用到的库文件进行组织形成终生成可执行代码的过程。过程图解如下: 从图上
可以看到,整个代码的编译过程分为编译和链接两个过程,编译对应图中的大括号括起的部分,其余则为链接
过程。 编译过程 编译过程又可以分成两个阶段:编译和会汇编。 编译 编译是读取源程序
(字符流),对之进行词法和语法的分析,将语言指令转换为功能等效的汇编代码,源文件的编译过程包含两
C语言的编译链接过程要把我们编写的一个c程序(源代码)转换成可以在硬件上运行的程序(可执行代码),需要进行
编译和链接。编译就是把文本形式源代码翻译为机器语言形式的目标文件的过程。链接是把目标文件、操作系统的启动代码和
用到的库文件进行组织形成终生成可执行代码的过程。过程图解如下:
从图上可以看到,整个代码的编译过程分为编译和链接两个过程,编译对应图中的大括号括起的部分,其余则为链接过
程。
编译过程
编译过程又可以分成两个阶段:编译和会汇编。
编译
编译是读取源程序(字符流),对之进行词法和语法的分析,将语言指令转换为功能等效的汇编代码,源文件的编译过程
包含两个主要阶段:
个阶段是预处理阶段,在正式的编译阶段之前进行。预处理阶段将根据已放置在文件中的预处理指令来修改源文件的内
容。如#include指令就是一个预处理指令,它把头文件的内容添加到.cpp文件中。这个在编译之前修改源文件的方式提供了很
大的灵活性,以适应不同的计算机和操作系统环境的限制。一个环境需要的代码跟另一个环境所需的代码可能有所不同,因为
可用的硬件或操作系统是不同的。在许多情况下,可以把用于不同环境的代码放在同一个文件中,再在预处理阶段修改代码,
使之适应当前的环境。
主要是以下几方面的处理:
(1)宏定义指令,如 #define a b
对于这种伪指令,预编译所要做的是将程序中的所有a用b替换,但作为字符串常量的 a则不被替换。还有 #undef,则将
取消对某个宏的定义,使以后该串的出现不再被替换。
(2)条件编译指令,如#ifdef,#ifndef,#else,#elif,#endif等。
这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关的文
件,将那些不必要的代码过滤掉。
下载后可阅读完整内容,剩余3页未读,立即下载
336 浏览量
3491 浏览量
138 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38560039
- 粉丝: 3
- 资源: 888
 我的内容管理
展开
我的内容管理
展开







最新资源
- Glenn Baddeley - GPS - NMEA sentence information
- Build your own web site the right way using HTML and CSS.pdf
- C++Builder6编程实例精解
- 单片机基础知识一定要学
- linux诞生和发展的5个支柱
- Snort 数据包捕获性能的分析与改进
- 高质量c++编程 林锐著
- Cognos性能调优
- ov7725 CMOS摄像头模组资料
- 跟我一起写Makefile
- 测试计划(GB8567——88)
- 图书馆管理系统 资源下载
- SAP应用及ABAP开发最佳实践—基于ABAP Workbench创建并发布Web Service.pdf
- MySQL5.0触发器
- SAP应用及ABAP开发最佳实践—Internal Table.pdf
- JAVA语言版数据结构与算法(中文)
